文章图片

文章图片
文章图片
机器之心原创
作者:冷猫
好玩好用的明星视频生成产品再更新 , 用户操作基础 , 模型技术就不基础 。
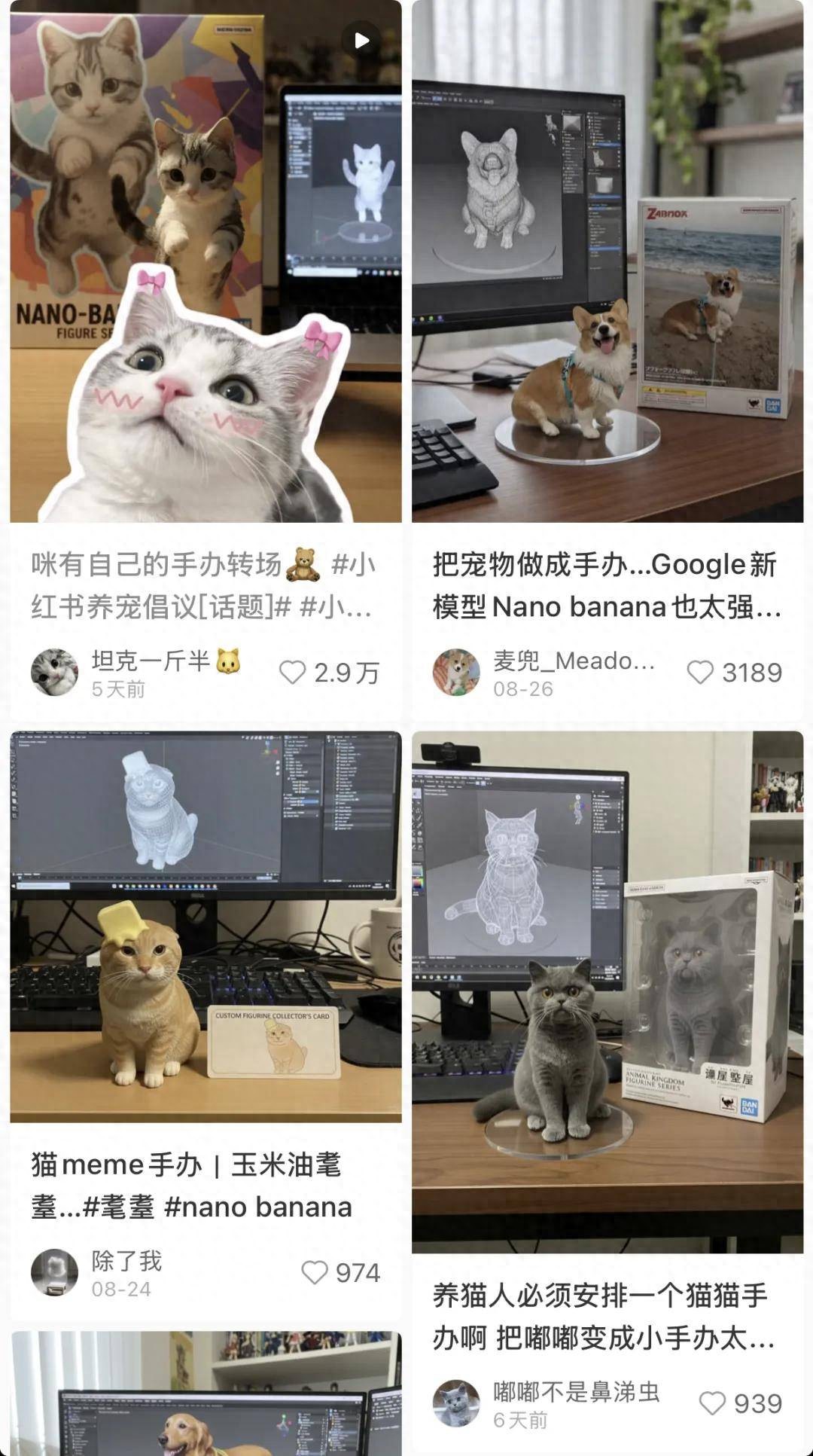
熟悉生成领域的读者们最近都被谷歌的一只纳米香蕉 nano-banana 刷了屏 。
在图像生成领域 , 纳米香蕉在短期内获得了巨量的影响力 , 凭着「照片变手办」的超高真实感的创意玩法横扫整个社交媒体 , 尤其触动了毛孩子家长们的心 。
在优秀的模型实力基本盘外 , 真正做到出圈的核心要素还得是「创意」 。
把自家宠物变成可爱手办的创意玩法的彻底出圈 , 让更多普通用户意识到 AI 生成让想象落地的能力 , 「这个好酷 , 我也想要」的心理触发了全民 AI 创作的裂变 。
不过 , 说到在 AI 视频中玩创意 , 老玩家 PixVerse(拍我 AI)上周五开始在国内开启免费开放周 , 两天内有创作者在小红书、短视频平台上玩 Nano banana 3D 手办 , 也有创作者用 Nano banana 生图和拍我 AI 模板结合 , 玩衣柜变装 , 获得视频号超 5000 点赞量 。
在两年前 , Sora 甚至还没有概念发布的时候 , PixVerse 就已经上线了网页端产品 , 上线 30 天内就实现了百万访问量 。
如此元老级的视频生成玩家 , 在「创意」上是认真的 。 过去那些火遍全网的神奇 AI 特效模板 , 都出自 PixVerse 之手 。
在今年 6 月 , 国内版本的产品「拍我 AI」正式上线 , 并搭载了当时最新的 PixVerse V4.5 底模 , 将长期霸榜视频生成应用榜的工具提供给期待已久的国内用户 。
当时 , 我们就做了一手全方位的体验 , 非常惊艳 , 一整个六边形战士 。
「让普通人感觉好玩 , 让创作者感觉好用」是拍我 AI 最贴切的标签 。
如果你是普通用户 , 首页中令人眼花缭乱的当下热门 AI 视频模板足够用来整活 , 越玩越上头;如果你是进阶创作者 , 文生视频、图生视频、首尾帧、多主体、视频续写等创作工具应有尽有 , 完美支持天马行空的创作思路 。 更值得一提的是 , PixVerse(拍我 AI)早于 veo3 就推出了音频音效和对口型等音频相关的创作功能 , 实现了视频创作的全流程闭环 。
PixVerse(拍我 AI)至 9 月 10 日期间生成任意视频不消耗积分 , 大家可以趁机随意尝试爆款短视频的创作 , 产生更多火爆的创意 , 进一步增进国内的AI视频创作热情 。
其发布的最新的 Agent 创作助手功能 , 不再只是提供「模板」 , 而是像一个随身的 AI 导演:用户只需选择喜欢的模板并上传一张图片 , Agent 即可自动识别其特征 , 生成一段 5–30 秒的完整短片 。 智能体功能不仅覆盖了目前网络上爆火的特效和创意视频 , 而且将用户从繁杂的 Prompt 设计工作中解放 , 让更多普通人加入到 AI 创作中来 。
「照片变手办」也不再是纳米香蕉的标签 , 我们用这只网红哈基米的图像做了智能体创作:PixVerse(拍我 AI)不仅生成了高质量的手办尾帧图 , 还生成了一个炫酷的转场动画 。
当然 , 拥有这么多有意思的玩法的平台早已受到海量用户的认可 。 不久前 , PixVerse(拍我 AI)的全球用户数已跃升至破亿的规模 。
要想在全球范围内获得上亿用户的认可 , 能够承接上亿用户的创作灵感 , PixVerse(拍我 AI)背后的公司 —— 爱诗科技 —— 一定在技术创新上做对了些什么 。
图生视频榜首 PixVerse V5 , 更全面的六边形战士
8 月 27 日 , 爱诗科技发布新一代自研视频生成大模型 PixVerse V5 。
PixVerse V4.5 已经是一个六边形战士了 , 谁曾想 PixVerse V5 又一次把六边形硬生生扩大了一圈 。
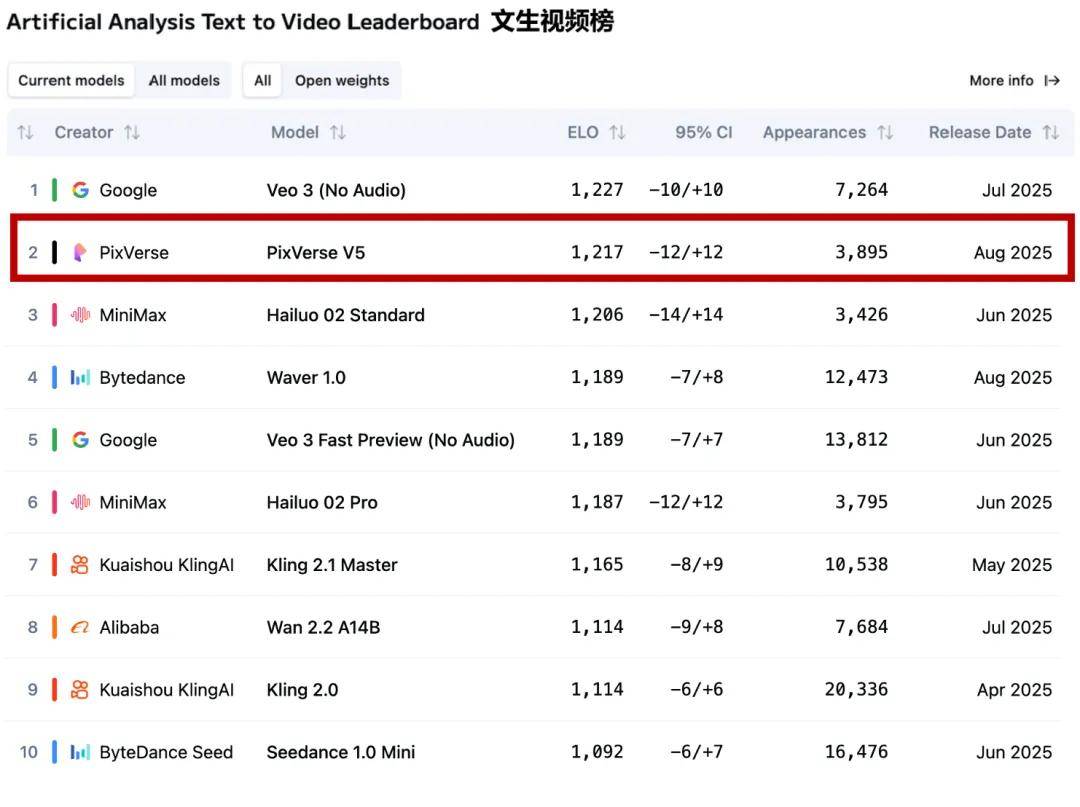
根据权威独立测评平台 Artificial Analysis 最新测试结果 , PixVerse V5 在图生视频(Image to Video)项目中排名全球第一 , 在文生视频(Text to Video)项目中位列同样位居第二 , 在视频生成赛道的最前列 。
PixVerse V5 的核心优势在三大方向:
智能理解:一句话生成精准视频 , 指令响应更准确 , 生成一致性和稳定性大幅提升 , 创意表达更自由高效 。 极速生成:视频生成速度保持在「分钟级」提升至「秒级」的准实时生成 , 最快 5 秒即可生成一段高质量短片 , 1 分钟生成 1080P 高清视频 。 更逼真自然:通过扩大模型参数规模和高质量训练数据 , 显著提升审美、复杂动作、运动幅度和光影的还原能力 , 让 AI 视频生成更接近真实拍摄 。令人惊喜的是 PixVerse V5 的更新并没有强调在某一个特定场景的能力提升 。 准确的说 , PixVerse V5 版本是对前一代底模的全方位进化 。 从技术革新的角度 , 我们来详细探究一下这三大方向上 , 爱诗科技是怎么走在时代前沿的 。
统一特征空间 , 指令没有沟通障碍
从用户角度而言 , 一个「好用」的生成模型 , 首先得听得懂诉求 。 当用户和模型之间有沟通障碍时 , 生成质量再高的模型也很难实现用户的目标 , 更难以称得上好用 。
就比如下面这个案例:
某国内头部产品模型生成的:「莱特兄弟的双翼飞机进化到喷气客机」
拍我 AI 生成的:「莱特兄弟的双翼飞机进化到喷气客机」
越是简单模糊的文本指令 , 越是考验模型对文本、图像、视频多模态数据的理解能力 。 爱诗科技显然在多模态大模型领域有着深刻的积累 。
我们知道 , VLM 多模态大模型 , 能够同时处理和理解图像和文本数据 。 以前的模型大多是「单模态」的:比如卷积神经网络只能看图 , 语言模型只能看文字 。 而 VLM 能同时理解图像和文本 , 并且把两者关联起来 , 处理更加复杂的任务 。 而在视频大模型中 , 视频相比于图像增添了时间维度 , 语义信息更丰富 , 更复杂 。
PixVerse(拍我 AI)将不同模态数据映射到同一语义体系 , 让不同模态的数据能够在同一个语义体系下对齐和交流 , 在 VLM 的体系下弥合了用户指令和生成视频之间的语义鸿沟 。
除了语义理解外 , 目前在视频生成领域的最大痛点在于视频生成的速度普遍不及预期 , 并且模型要实现高质量和长序列的视频生成 , 对训练数据和训练资源的需求是巨大的 。
爱诗科技在这两大传统痛点上持续发力 , 奠定了在视频生成领域坚实的技术优势 。
扩散极致蒸馏 , 几秒完成生成的准即时魔法
用过 Sora 生成过视频的朋友们都应该很有感触 , 从指令输入到成片出现至少也要以数分钟计算 。 一个慢速的生成模型非常干扰用户的创作思路 , 非常影响使用体验 , 更别提连续创作了 。
而生成速度这部分 , 是 PixVerse(拍我 AI)的传统强项 , 也是其获得全球海量 AI 创作用户青睐的核心竞争力 。
爱诗科技是业界第一个把视频生成做到 5 秒之内的 AI 初创团队 。
在 PixVerse V4.5 的时候我们就实测过 , 即使我们将各项生成指标拉满 , 平台输出结果的时间也没有超过 1 分钟 。
对于用户来说 , 如此短暂等待能够成为「准即时」生成 , 完全不给使用带来负面影响 。
为了实现超高速的视频生成 , 爱诗科技对视频扩散模型进行了大刀阔斧的改进 , 采用了「分数匹配蒸馏」的方式 , 将视频扩散生成过程从几十步压缩至极少数步骤 , 极大的提高了模型的生成速度 。
分数匹配蒸馏是一个扩散模型体系下 , 将扩散模型转换为一步生成 , 极大地加快了生成速度并保持质量的代表性方法 。 最初 , 该方法在图像生成领域使用 。 在视频生成领域 , 该方法具有很大的应用潜能 。
据爱诗科技技术团队介绍 , PixVerse V5 不仅采用了分布匹配损失优化模型采样轨迹提速生成 , 为了保证视频生成的质量 , 他们还结合了特征自约束损失 , 让模型实现自我监督 , 以此稳定画面质量 , 实现了生成速度和生成质量之间完美的平衡 。
自研生成架构 , 突破创造力上限的驱动力
决定了 PixVerse(拍我 AI)产品能力的核心是底模 , 决定了底模能力上限的是高质量的模型架构 。
爱诗科技全面采用自研的视频生成模型 , 采用 DiT 架构 , 在模型结构设计、训练策略等方向上进行了充分的创新工作 , 能够充分激发 DiT 架构模型的生成潜力 。
为了满足读者对领先的模型的技术细节的好奇心 , 机器之心特意向爱诗科技的技术团队了解了一些他们在自研 DiT 模型的架构创新和技术细节 。
简而言之 , DiT 模型将 VAE 框架之下扩散去噪中的卷积架构换成了 Transformer 架构 , 结合了视觉 transformer 和扩散模型的优点 , 利用全局注意力机制 , 具备可扩展性强 , 多模态扩展 , 生成质量高的优势 。
DiT 基本模型架构图 , 来自论文《Scalable Diffusion Models with Transformers》
DiT 虽然效果好 , 但是对训练的算力要求很高 , 需要有好的模型设计以及好的模型训练策略 , 才能实现高质量的生成 。 尤其是在视频生成领域 , 要采用 DiT 模型进行高质量视频生成则更为复杂 , 需要在模型架构中添加时间维度 。 正所谓牵一发而动全身 , 视频生成 DiT 模型在算力需求、数据需求、分辨率兼容等多个问题上都面临着不小的挑战 。
【全球图生视频榜单第一,爱诗科技PixVerse V5改变一亿用户视频创作】爱诗科技的技术团队向我们透露 , PixVerse V5 在模型结构设计上有两大亮点:
Tokenizer 方面:我们正在训练专用于视频与图像生成的 Tokenizer , 在保持较高压缩比的同时 , 依然能够保证出色的重建质量与生成效果 。 自适应 Attention 结构(FullAttn + SparseAttn):通过在计算量与注意力精度之间动态平衡 , 不仅能有效降低整体计算开销 , 还能在推理速度几乎不受影响的前提下 , 为模型提供更大的规模扩展(ScaleUp)空间 , 并显著提升其拟合能力 。众所周知 , 视频数据相比于文本和图像数据更为复杂和庞大 , 数据包含的信息量更大且更难以提取 , 给模型训练提出了巨大的难题 。
为了模型能够有效学习数据集中的信息 , 快速实现模型收敛 , 实现模型性能提升 , 爱诗科技在模型训练策略上下了很大功夫 , PixVerse V5 在多模态训练策略上有四大创新优势:
多模态统一表征:将文本、图像、视频等模态映射至同一语义空间 , 显著提升模型的理解与生成精度 , 并加速整体收敛过程 。 自适应加噪去噪:在训练过程中动态调整噪声水平 , 并结合任务难度相关的损失加权机制 , 在不同信噪比条件下有效加速模型收敛 。 渐进式训练策略:采用「由简入繁」的训练路径 , 先进行图像任务学习 , 再逐步扩展至图像 + 视频的联合训练;在联合训练中 , 从低时长到高时长、低分辨率到高分辨率逐步递进 , 保证稳定收敛与性能提升 。 原生动态分辨率支持:模型能够直接处理不同分辨率的图像与视频 , 无需额外的 resize 或 crop 操作;结合原生动态分辨率与绝对时间编码机制 , 使其具备处理多尺度图像及长时序视频的能力 。另外 , 爱诗科技团队透露 , 他们拥有领先的海量图像和视频数据 , 和高质量、高精准的精选数据 , 不仅能够为模型预训练提供了无限可能的数据分布 , 也在监督训练微调(SFT)阶段更上一层台阶 。
这些硬核的技术革新驱动着 PixVerse 模型的不断进化 , 支撑着用户生成动作自然、光影真实、物理规律准确的创意视频 , 也是满足广告、电商、影视、教育、游戏等场景的高标准要求的核心基本盘 。
过去 , 在视频生成的研究探索阶段 , 我们一般都在讨论一些最基本的生成逻辑 , 包括物理效果 , 光影效果 , 动作的合理性等等 。
随着技术的不断迭代 , 视频生成已经进入了投入实际应用的新阶段 , 而现在我们讨论的更多的是生成视频的创意和美学范畴了 。 随着 PixVerse V4.5 对各种趣味创意、光影艺术的创作、镜头语言的理解方面的功能实现 , 我们自然希望 PixVerse V5 在美学上能够有一些新的理解 。
爱诗科技在模型中利用高质量视频数据和人类偏好标注 , 结合强化学习后训练(RLHF) , 提升了文本 - 视频对齐精度、动作自然度和美学评分 。
超可爱的小猫咪舔爪爪 , 毛茸茸的小窝和字体设计 , PixVerse V5 真的很懂可可爱爱的心头好 。
将人类的审美喜好加入到大模型训练中 , 让 AI 更懂人心 , 更懂审美 , 为打开模型生成的上限 , 投入 AI 艺术创作奠定了坚实的基础 。
疾速成长 , 领跑视频生成马拉松
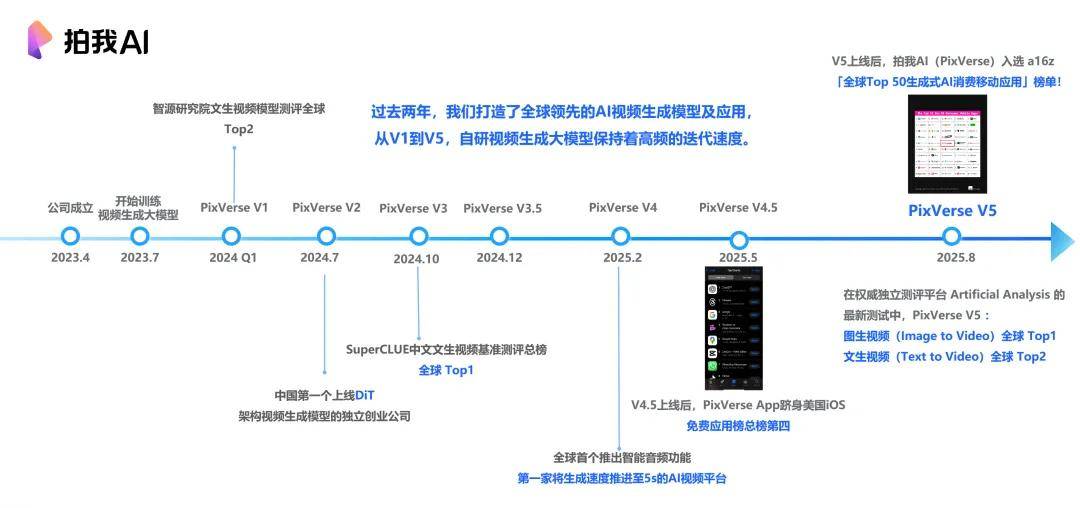
爱诗科技模型发展历程
从 2023 年 7 月开始 , 爱诗科技训练视频生成大模型 , 到 2025 年 8 月底发布 PixVerse V5 模型 , 仅有短短的两年时间 。
在这两年期间 , 每隔数个月就能有一次模型的迭代 , 成长非常迅速 。 直到 2024 年底 , 爱诗科技发布 PixVerse App 产品 , 创下了全球最快的高质量视频生成的模型纪录 , 真正进入应用阶段 。
从 V3 一直到 V5 , 生成速度从 10 秒进化到 5 秒准实时 , 视频生成进入了有声时代 , 镜头语言、多主体、智能体等里程碑式功能接连上线 , 这一切支撑着 PixVerse(拍我 AI)成为了全球用户量最大的视频生成平台 。
AI 视频生成是一场没有终点的马拉松 , 只有保持高速的技术迭代、不断刷新模型的边界 , 才能始终引领行业向前 。
爱诗科技创始人兼 CEO 王长虎博士在 2025 北京智源大会上表示:「视频是最贴近用户的内容形态 。 一旦视频生成技术能够落地 , 它的产品化和商业化潜力可能不亚于大语言模型 。 」
「去年 2024 年 10 月 , 我们的 PixVerse V3 上线 , 这是第一次真正让普通用户、普通消费者用 AI 能力创造出过去无法创造出来的视频 。 在我心中 , 这一刻才是视频生成的『GPT 时刻』 。 」
爱诗科技所秉持的愿景与技术理念 , 正是要在这条漫长而激烈的赛道上 , 持续释放视频这一最贴近用户的内容形态的潜能 , 让创造的能力真正走向每个普通人 。
文中视频链接:https://mp.weixin.qq.com/s/Sk5lEfj-1R5zhV6tNVPI2A
推荐阅读















- 设计完全逆华为!全球首款安卓三折叠屏亮相:配置非常凶猛!
- 中国芯崛起!只差2.2%,中芯就要超三星成全球第二了
- “奥运级”科技实力获全球认证!TCL实业荣获三项IFA2025大奖
- IDC报告:全球清洁机器人市场增速预估28.2%,石头科技半场领先
- 海信携新品闪耀 IFA ,以硬核黑科技定义全球显示新标杆
- 聚焦IFA 2025:创维尖端电视技术凸显中国智造全球竞争力
- 中国牢牢控制供应链 人形机器人有望主导全球
- 影石携首款全景无人机亮相IFA 2025 引领全球影像技术变革
- 华为首次超越三星,2025上半年全球折叠手机出货量排名第一
- 联想三高管IFA2025深度对话:AI如何重构PC形态与全球化品牌矩阵