
文章图片

文章图片
文章图片
机器之心报道
编辑:Panda
AI 最臭名昭著的 Bug 是什么?不是代码崩溃 , 而是「幻觉」—— 模型自信地编造事实 , 让你真假难辨 。 这个根本性挑战 , 是阻碍我们完全信任 AI 的关键障碍 。
大模型会有幻觉 , 这几乎已经成为一个常识 , 让每一个严肃使用大模型的人都不得不谨慎小心 。 OpenAI 也指出:「ChatGPT 也会产生幻觉 。 GPT-5 的幻觉明显更少 , 尤其是在执行推理时 , 但幻觉仍然会发生 。 幻觉仍然是所有大型语言模型面临的一大根本挑战 。 」
尽管现在学术界已经提出了各种各样用来降低模型幻觉的方法 , 但目前尚未出现能彻底「根治」模型幻觉的良方 。
那么 , 大模型究竟为什么会出现幻觉呢?今天 , OpenAI 罕见发表论文 , 系统性地揭示了幻觉的根源 。
首先 , 定义幻觉 。 OpenAI 给出的简单定义是:「模型自信地生成不真实答案的情况 。 」
至于原因 , 简单来说就是:标准的训练和评估程序更倾向于对猜测进行奖励 , 而不是在模型勇于承认不确定时给予奖励 。
论文标题:Why Language Models Hallucinate 论文地址:https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf下面我们就来具体看看 OpenAI 究竟发现了什么 。
什么是幻觉?
幻觉是语言模型生成的看似合理但却错误的陈述 。
即使看似简单的问题 , 它们也可能以出人意料的方式出现 。 OpenAI 举了个例子 , 当向不同的广泛使用的聊天机器人询问 Adam Tauman Kalai(论文一作)的博士论文标题时 , 它们自信地给出了三个不同的答案 , 但没有一个是正确的 。
当询问他的生日时 , 它给出了三个不同的日期 , 同样都是错误的 。
为了测试而学习
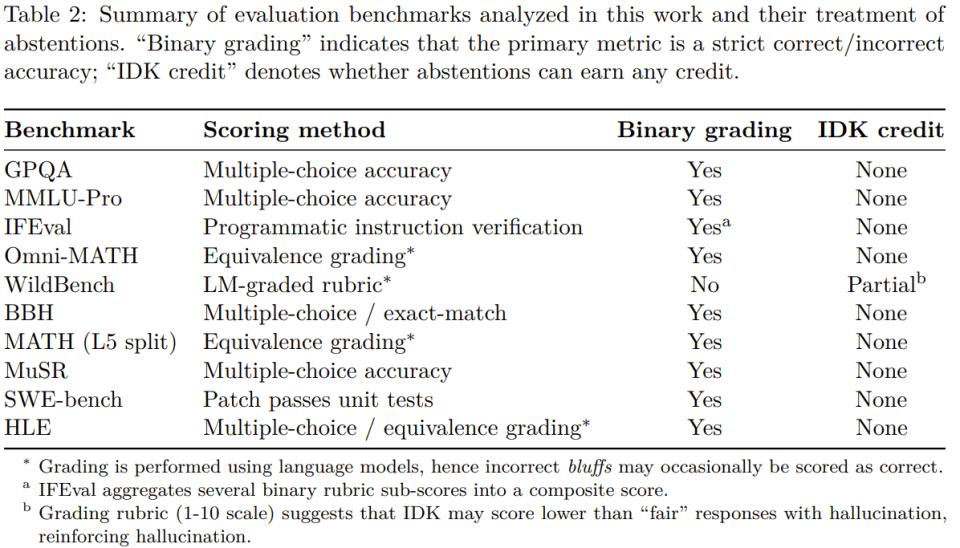
【OpenAI罕见发论文:我们找到了AI幻觉的罪魁祸首】OpenAI 表示 , 幻觉持续存在 , 部分原因是当前的评估方法设置了错误的激励机制 。 虽然评估本身不会直接导致幻觉 , 但大多数评估模型性能的方式会鼓励模型进行猜测 , 而不是诚实地面对不确定性 。
可以把它想象成一个多项选择题测试 。 如果你不知道答案 , 但随意猜测 , 你可能会很幸运地猜对 。 留空则必定得零分 。 同样 , 当模型仅根据准确度(即完全答对问题的百分比)进行评分时 , 它们会被鼓励进行猜测 , 而不是承认「我不知道」 。
再举一个例子 , 假设一个语言模型被问及某人的生日 , 但它不知道 。 如果它猜测「9 月 10 日」 , 那么它有 1/365 的概率猜对 。 说「我不知道」则必定得零分 。 在数千道测试题中 , 猜测型模型最终在记分牌上的表现要优于谨慎且承认不确定的模型 。
对于只有一个「正确答案」的问题 , 可以考虑三类答案:准确答案、错误答案以及模型不愿冒险猜测的弃权答案 。
OpenAI 表示 , 弃权答案是谦逊(humility)指标的一部分 , 而谦逊是 OpenAI 的核心价值观之一 。
大多数分数指标会根据准确度对模型进行优先排序 , 但错误答案比弃权答案更糟糕 。 OpenAI 的模型规范指出 , 指出不确定性或要求澄清会更好 , 而不是自信地提供可能不正确的信息 。
以 GPT5 系统卡中的 SimpleQA 评估为例 。
在准确度方面 , 更早期的 OpenAI o4-mini 模型表现略好 。 然而 , 其错误率(即幻觉率)明显较高 。 在不确定的情况下进行策略性猜测可以提高准确度 , 但也会增加错误和幻觉 。
在对数十次评估的结果进行平均时 , 大多数基准测试都会剔除准确度指标 , 但这会导致对错之间的错误二分法 。
在像 SimpleQA 这样的简单评估中 , 一些模型的准确度接近 100% , 从而消除了幻觉 。 然而 , 在更具挑战性的评估和实际使用中 , 准确度会固定在 100% 以下 , 因为有些问题的答案由于各种原因(例如信息不可用、小型模型的思维能力有限或需要澄清的歧义)而无法确定 。
尽管如此 , 仅以准确度为衡量标准的评估指标仍然占据着排行榜和模型卡的主导地位 , 这就会鼓励开发者构建能够猜测而不是退缩的模型 。
正因为此 , 即使模型变得更加先进 , 它们仍然会产生幻觉 。 原因之一便是它们倾向于自信地给出错误答案 , 而不是承认不确定 。
更好的评估方法
对此 , OpenAI 指出了一个简单的解决办法:对自信错误(confidential error)的惩罚力度大于对不确定性的惩罚力度 , 并对恰当表达不确定性的行为给予部分加分 。
这个想法并不新鲜 。 一些标准化测试长期以来一直使用对错误答案进行负面评分或对留空问题给予部分加分的方法来阻止盲猜 。 一些研究团队也探索了考虑不确定性和校准的评估方法 。
但 OpenAI 表示 , 仅仅增加一些新的不确定性感知测试是不够的 。 广泛使用的、基于准确度的评估方法需要更新 , 使其评分能够阻止猜测 。
如果主要评估指标依然继续为模型幸运的猜测给予奖励 , 模型就会继续学习猜测 。 修改评估指标可以扩大降低幻觉技术的采用范围 , 包括新开发的和先前研究的技术 。
幻觉是如何从下一个词预测中产生的
前面已经讨论过为什么幻觉如此难以摆脱 , 但这些高度具体的事实性错误究竟从何而来?
毕竟 , 大型预训练模型很少出现其他类型的错误 , 例如拼写错误和括号不匹配 。
OpenAI 表示 , 区别必定在于数据中存在哪些模式 。
语言模型首先通过预训练进行学习 , 这是一个预测海量文本中下一个词的过程 。
与传统的机器学习问题不同 , 每个语句没有「真 / 假」标签 。 该模型只看到流畅语言的正面示例 , 并且必须去近似整体分布 。
当没有任何被标注为无效的示例时 , 区分有效语句和无效语句会更加困难 。 但即使有标签 , 一些错误也是不可避免的 。
为了理解原因 , 可以考虑一个更简单的类比 。 在图像识别中 , 如果数百万张猫狗照片被标记为「猫」或「狗」 , 算法可以学会可靠地对它们进行分类 。 但想象一下 , 如果用宠物的生日来标记每张宠物照片 。 由于生日本质上是随机的 , 无论算法多么先进 , 这项任务总是会产生错误 。
同样的原则也适用于预训练 。 拼写和括号遵循一致的模式 , 因此这些错误会随着规模的扩大而消失 。 但像宠物的生日这样任意的低频事实 , 无法仅凭模式预测 , 因此会导致幻觉 。
OpenAI 的分析解释了哪些类型的幻觉会由下一个词预测产生 。 理想情况下 , 预训练后的后续阶段应该能够消除这些幻觉 , 但由于上一节中描述的原因 , 这并未完全实现 。
总结
OpenAI 表示:「我们希望本文中的统计学视角能够阐明幻觉的本质 , 并驳斥一些常见的误解」:
有人宣称:幻觉可以通过提高准确度来消除 , 因为 100% 准确的模型永远不会产生幻觉 。
发现:准确度永远不会达到 100% , 因为无论模型规模、搜索和推理能力如何 , 有些现实世界的问题本质上是无法回答的 。
有人宣称:幻觉是不可避免的 。
发现:幻觉并非不可避免 , 因为语言模型在不确定时可以放弃回答 。
有人宣称:避免幻觉需要一定程度的智能 , 而这只有大型模型才能实现 。
发现:小型模型更容易了解自身的局限性 。 例如 , 当被要求回答毛利语问题时 , 一个不懂毛利语的小型模型可以直接回答「我不知道」 , 而一个认识一些毛利语的模型则必须确定其置信度 。 正如论文中所讨论的 , 「校准」所需的计算量远小于保持准确 。
有人宣称:幻觉是现代语言模型的一个神秘缺陷 。
发现:我们可以理解幻觉产生以及在评估中获得奖励的统计学机制 。
有人宣称:要测量幻觉 , 我们只需要一个好的幻觉评估 。
发现:已有研究者发表了一些幻觉评估 。 然而 , 一个好的幻觉评估与数百种传统的基于准确度的评估相比几乎没有效果 , 这些评估会惩罚谦逊并奖励猜测 。 相反 , 所有主要的评估指标都需要重新设计 , 以奖励不确定性的表达 。
OpenAI 表示:「我们最新的模型幻觉率更低 , 并且我们将继续努力 , 进一步降低语言模型输出的置信错误率 。 」
顺带一提 , 据 TechCrunch 报道 , OpenAI 正在重组其模型行为(Model Behavior)团队 , 这是一支规模虽小但颇具影响力的研究人员团队 , 他们决定着该公司的 AI 模型与人互动的方式 。 现在 , 该团队将向 OpenAI 的后期训练主管 Max Schwarzer 汇报 。
而该团队的创始负责人 Joanne Jang 则将在公司启动一个新项目 , 名为 oai Labs 。 据她的推文介绍:「这是一个以研究为导向的团队 , 专注于发明和设计人们与 AI 协作的新界面原型 。 」
参考链接
https://openai.com/index/why-language-models-hallucinate/
https://techcrunch.com/2025/09/05/openai-reorganizes-research-team-behind-chatgpts-personality/
https://x.com/joannejang/status/1964107648296767820
推荐阅读














- 刚刚,光刻机巨头ASML杀入AI!豪掷15亿押注欧版OpenAI成最大股东
- 字节多模态Agent又进化!多项性能超OpenAI,玩游戏赶上人类水平
- 发展引擎动力足!“工业互联网+AI”助力传统制造业更“智慧”
- 小米AI眼镜发布固件更新:支付宝看一下支付上线
- 6899元起的壹号本游侠X1 Air、3999元的壹号方糖SUGAR 1掌机发布
- iPhone 17 Air 突然被曝,发布时间变了?
- 国行版iPhone AI,终于要发
- 开放全栈!超越π0,具身智能基础大模型迎来真·开源,开发者狂喜
- 专注“冷阴极”X射线源技术研发,「新鸿电子」获数亿元战略融资|36氪首发
- AI机器萌宠企业「Ropet萌友智能」完成数千万A1轮融资 | 36氪首发