
文章图片
文章图片

文章图片

文章图片
文章图片
文章图片

文章图片
衡宇 鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
继π0后 , 具身智能基座模型在中国也终于迎来了真正的开源——
刚刚 , WALL-OSS宣布正式开源!
在多项指标中 , 它还超越了π0 。
如果你是搞具身的开发者 , 了解它的基本资料 , 你就一定不会想错过它:
它是一个通用基础具身模型 , 泛化性和推理能力一流 , 你可以在自有本体上部署 , 快速微调后用起来 。
它还是一个多模态具身模型 , 输入与输出的数据 , 有语言、视频、动作等多种形态 , 具备良好的因果推理、空间理解和反思能力 。
我们调研了一圈发现 , 在4.2B参数规模下 , 融合了超大规模的高质量真机数据进行预训练的WALL-OSS , 是唯一一个具备语言、视觉、动作多模态端到端统一输出能力的开源具身模型 。
这一波操作 , 不香都难 。
它凭什么这么能打?我们得从背后的团队说起 。
用最近的流行梗来说 , 模型“基础” , 背后团队就不基础——成立于2023年底的自变量机器人 。
目前 , 分层架构与端到端模型是两条具身的主要技术路径 。 从成立起自变量就全身心押注后者 。 去年11月 , 团队推出了WALL-A , 全球最大规模的端到端统一具身大模型 。
技术上屡有成果 , 资本市场也分外看好 。
就在今天 , 这支队伍刚刚宣布完成了近10亿元A+轮融资 。
阿里云、国科投资领投 , 国开金融、红杉、渶策、美团、联想之星、君联资本都在这一轮股东名单之列 。
据了解 , 融来的这笔钱 , 大部分依旧投入全自研通用具身智能基础模型的持续训练 。
单卡训练+开放泛化 , 所有轮式机器人都能跑仅需要RTX 4090级别的同等算力显卡 , 开发者便能完成WALL-OSS从训练到推理部署的全过程 。
更重要的是 , WALL-OSS在保证低成本训练的同时 , 依旧实现了顶尖的泛化表现 。
在严格的ID(分布内)和OOD(分布外)评测中 , WALL-OSS展现出领先π0等同类开源模型的性能优势 。
首先在泛化性上 , 即使是在指令描述、动作动词、物体方位等要素发生变化的OOD场景下 , WALL-OSS依旧能保持高任务成功率和指令遵循度 , 展现出优异的环境适应性 。
在需拆解细分指令的长程任务中 , WALL-OSS也显著优于采用扁平化策略的基线模型(如π0-flat) 。
在依赖CoT的推理类任务里 , WALL-OSS更是优于π0-flat和pi-gpt-prompt等强基线 。
此外通过空间VQA、视觉定位、场景语言描述等多模态基准测试验证 , WALL-OSS不仅可以完整保留VLM的核心功能 , 还在原有基础上实现了能力强化 。
这种对核心能力的扎实沉淀 , 让它能同时兼顾推理规划和动作执行 , 可输出语言和动作双模态 , 一些视觉信息也能以语言形式传递 。
值得注意的是 , WALL-OSS采用统一的Transformer架构 , 并通过专家分流机制实现语言、视觉、动作在统一框架下的生成与协同优化 。
这种真正意义上的端到端避免了多阶段流程的误差累计 , 极大提升了模型在长程和“推理+操作”复合任务上的稳定性和成功率 。
截至目前 , WALL-OSS填补了此参数区间内的高水平具身智能大模型的空白 , 成为业界唯一一个同尺寸下的面向物理世界交互、端到端路径的具身智能统一模型 。
更重要的是 , WALL-OSS并不依赖特定场景优化 , 且具备跨场景迁移与执行能力——
从养老护理到工业装配 , 从酒店服务再到物流分拣……一个真正意义上可以通用部署的具身大脑 , 展现出巨大的应用潜能 。
所以从现在起 , 无论是产业界做场景落地的团队还是高校实验室 , 甚至是极客爱好者 , 都可以部署最前沿的具身智能大模型 。
具体到硬件适配方面 , WALL-OSS可以通过微调 , 快速适配到不同本体上 , 极大地降低了机器人应用的落地 。
4大创新 , 让4.2B模型击碎具身智能“不可能三角”目前的具身智能界 , 存在着一个广泛公认的技术难题:
【开放全栈!超越π0,具身智能基础大模型迎来真·开源,开发者狂喜】如何在模态统一、动作精度和能力泛化之间达成平衡?
这个“三难困境” , 几乎构成了当前具身智能模型的能力上探的绊脚石 。 市面上大多数模型通常只能做到一个 , 两者兼顾已经很难 , 更别提三者具备 。
WALL-OSS是少数试图正面破解这一结构性难题的模型之一:它在各项指标上均追求极限 , 并从架构到训练范式 , 从数据构建到推理机制 , 进行了系统性重构 。
这让模型在当前4.2B参数的体量下 , 实现了模态统一、推理泛化与动作生成的能力闭环 。
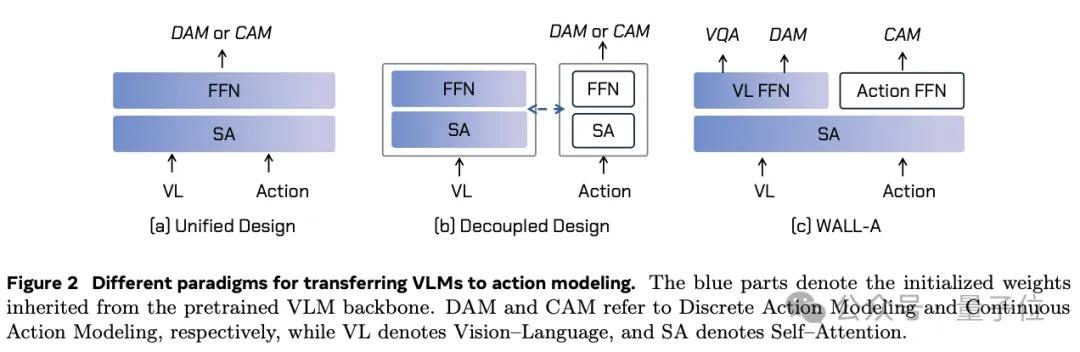
这背后的第一步 , 事关模型架构设计 。
WALL-OSS没有采用传统多模态拼图式的堆叠结构 , 而是首创了“共享注意力 + 专家分流(FFN)”这一新架构 。
简单来说 , 它将语言、视觉、动作等信息都嵌入在同一个表示空间中处理 , 通过共享注意力机制实现模态间的信息交叉 , 同时再通过专家FFN高效处理不同任务 。
这种设计有效避免了VLM知识迁移中的“灾难性遗忘”和“模态解耦”两大难题 , 在融合度更高的同时 , 又能保留每一模态的独特表达能力 。
第二个关键点 , 是对数据质量及训练策略的把控 。
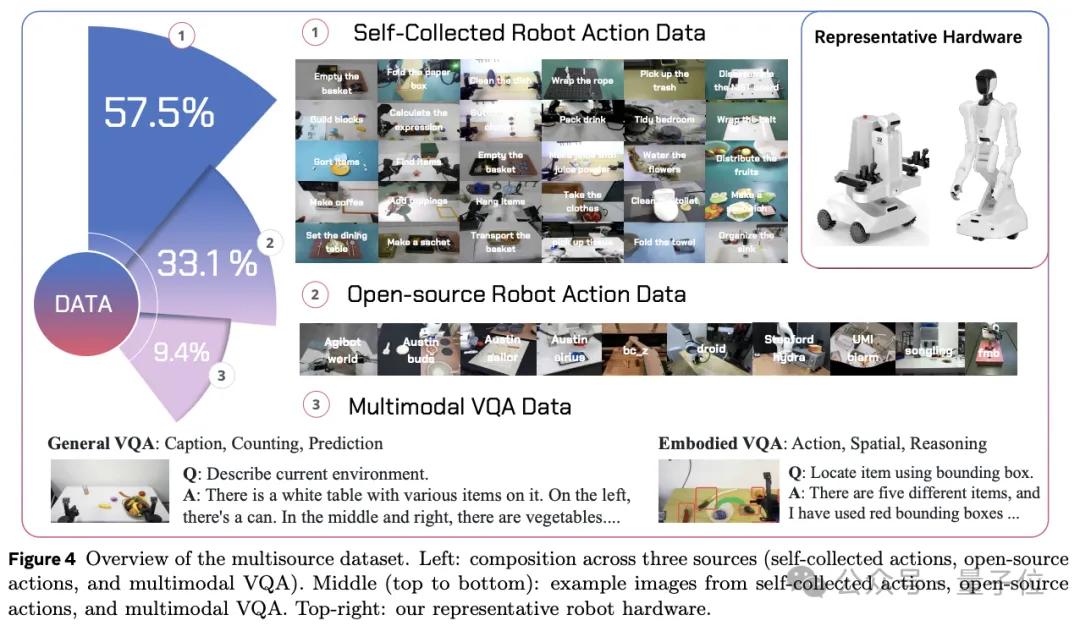
WALL-OSS背后 , 是大规模的VLA训练集的支撑 , 其中主要包括大量自采高质量真机数据和具身多模态数据 。
值得注意的一点是 , 真机数据高质量、高精度 , 与真实世界高度贴合 , 是目前具身大模型中最好的数据源 。
在有了规模够大、多样性丰富、质量够高的数据的基础上 , 自变量团队精心设计了训练策略 。
传统端到端训练方式常常面临一个问题:认知能力强的模型不一定能输出精准动作 , 而擅长动作控制的模型则缺乏推理和规划力 。
为了解决这一问题 , WALL-OSS设计了Inspiration Stage(启发阶段)和Integration Stage(融合阶段)两阶段训练策略 。
在Inspiration Stage阶段 , 继续使用原VLM的FFN结构 , 加入多种预训练任务以增强空间+语义理解能力、引入Embodied VQA(具身视觉问答)任务 , 并引入离散动作学习 。
其核心目标是保持原始VLM能力不变的基础上 , 增强其对空间结构和动作的初步理解 , 为后续动作生成打下感知语义基础 , 避免“灾难性遗忘” 。
Integration Stage阶段则分为两个子步骤 。
第一步 , 冻结VLM , 仅训练动作模块;第二步 , 解冻VLM , 联合优化全模型 。
如此这般 , 模型能从语言和视觉输入中连续生成高频物理动作 , 既保留了VLM的语言与视觉理解能力 , 又具备细粒度动作执行力 , 建立统一、协同、紧耦合的跨模态表示空间 。
研发团队发现 , 采用“先离散、后连续、再联合”这一范式后 , VLM强大的认知能力 , 能稳定、无损地迁移和扩展到物理动作上 。
而团队独具匠心的第四个创新点 , 是让WALL-OSS有了内生的高级推理能力 。
具体来说 , WALL-OSS的统一跨层级思维链将思维链推理的概念从传统狭义CoT(大语言模型中逐步文本推理)推广至涵盖整个语义-感知运动频谱的广义CoT:
指令→推理(CoT)→子任务规划→连续动作 。
这种统一框架实现了跨层级抽象层面的前向任意映射 , 使模型能够在单一可微分框架内无缝切换高层决策与底层执行 。
自变量机器人CTO王昊表示:
这是WALL-OSS能够胜任长程、复杂任务的关键 。 在面对未知环境、从未习得的任务时 , 模型也能自主拆解步骤 , 逐步思考 , 寻求解决办法 。
So , 具身智能“不可能三角”不是真的牢不可破 。
架构、数据、训练、统一跨层级CoT四线齐发 , 让WALL-OSS在体量适中、硬件可负担的前提下 , 建立了一个真正能通用执行的具身智能能力底座 。
真·开源通用模型 , 为具身智能“修路”说完模型能力、技术突破 , 最后我们得说说它最破圈的一步:
WALL-OSS , 它真·开源了 。
在此前 , 具身行业里除了π0 , 开源界没有完全开源又真能打、真能用的;但对开发者来说 , π0又得花很长时间才能微调用起来 。
那么WALL-OSS呢?
——没有OpenAI那种长期吊胃口式的夸张性预告 , 不是只发paper那种程度的 , 开源的还不是几百个数据样本量的小模型 。
这次自变量放出的 , 是一整套完整可复现的具身大模型方案 。
包括预训练模型权重、训练代码、数据集接口 , 甚至还附带了详细部署文档 , 开发者可以在自己的机器人上直接跑通闭环流程 。
这样即使开发者没什么训练经验 , 也能让第三方机器人无门槛接入最先进的具身智能基座 , 完成模型微调和复现任务 。
不管你是研究机构、机器人公司 , 还是独立开发者 , 只要你有一个本体设备 , 哪怕不是自变量出品 , 也能把WALL-OSS跑起来 。
这一步 , 直接把具身智能的进入门槛拉低了好几个台阶——实测反馈 , 外部团队最快一周内就能完成适配 。
(注:通常情况下 , 这一过程需要1~2个月)
当然 , 如果用的是自变量本家的具身智能硬件 , 适配会更快 , 效果更丝滑 。
为什么要开源?为什么要这么彻底地开源?
过去几年 , 整个具身智能赛道看上去热闹 , 发布会一个接一个 , 但似乎陷入了一种“过拟合演示”怪圈 。
Demo演示一次次惊呆众人 , 但真正用起来 , 效果就是大打折扣 。
自变量团队认为根本原因还是模型基建的缺失 。
具身智能特别就特别在它是“软硬件一体”的 , 所以一旦基础设施受限 , 想把模型用起来 , 就需要不断适配、微调 , 就意味着高投入、高门槛、长时间 。
与其每个团队每次都要花那么大功夫 , 为什么不索性直接彻底开源呢?
要知道 , 国内不缺有想法、有实力的人才或团队 , 能在某一个环节上节约时间 , 都能加速推动研发进度和实际场景落地 。
至于数据和算力的问题 , 很多科研团队、中小企业都难以只靠自己克服 。
所以 , 具身智能领域迫切需要一个低算力、能力强、还开源的基础模型来打破僵局 。
WALL-OSS , 就是这么一个符合上述条件的具身大模型 。
“我们想让整个行业以最低的成本 , 获得最先进、最通用的能力基座 。 ”自变量CTO王昊总结道 , “因为没有基础模型 , 具身智能行业根本长不大 。 ”
并且 , 自变量团队希望通过WALL-OSS乃至后面持续的开源 , 建立起开源的标杆 。
这个举动 ,能让“只能在定制化场景中表现优异”的机器人无处遁形 , 进一步推动行业之间的公平 , 倒逼技术透明化发展 。
也能让更多的人才愿意加入具身智能行业 , 去一起攻破一些核心的技术难点 。
在具身智能这场长跑里 , 终点一定不会只给某一家公司准备鲜花和奖杯 。 但起点 , 至少该有一块足够稳的起跑板 。
自变量要做的 , 就是这块起跑板 。
GitHub:https://github.com/X-Square-Robot/wall-x项目主页:https://x2robot.com/en/research/68bc2cde8497d7f238dde690
— 完 —
量子位 QbitAI · 头条号
关注我们 , 第一时间获知前沿科技动态
推荐阅读














- AMD 锐龙5 9500F首测 游戏帧数超越14600K 千元质价比拉满
- 华为首次超越三星,2025上半年全球折叠手机出货量排名第一
- Denodo声称DeepQuery能超越生成式AI的表面洞察
- 首个AI计算开放架构在重庆发布,国产智算迎来“安卓模式”
- 韩国发布报告:中国芯片技术超越韩国,全球第二!
- 微软团队打破光纤40年技术瓶颈!速度与损耗首次全面超越传统玻璃
- 蚂蚁专用模型超越o3!仅用2K训练样本刷新医疗AI榜单纪录
- 小米汽车营收被曝已超越小米手机,小米副业快干成主业了?
- 超越X200 Ultra!vivo X300 Pro确认将搭载2亿HPB长焦
- 首次超越苹果,华为手表全球称王!