AI读网页,这次真不一样了,谷歌Gemini解锁「详解网页」新技能

文章图片

文章图片
文章图片

文章图片

机器之心报道
机器之心编辑部
谷歌回归搜索老本行 , 这一次 , 它要让 AI 能像人一样「看见」网页 。
这是谷歌前不久在 Gemini API 全面上线的 URL Context 功能(5 月 28 日已在 Google AI Studio 中推出) , 它使 Gemini 模型能够访问并处理来自 URL 的内容 , 包括网页、PDF 和图像 。
Google 产品负责人 Logan Kilpatrick 表示这是他最喜欢的 Gemini API 工具 , 并推荐大家把这个工具设置为默认开启的「无脑选项」 。
那么灵魂一问:这和我平时把链接扔给 AI 对话框里有什么本质区别?感觉我一直在这么做 。
区别在于处理深度和工作方式 。 你平时扔链接 , AI 通常会通过一个通用的浏览工具或搜索引擎插件来「看」这个网页 , AI 很可能只读取了网页的摘要或部分文本 。
而 URL Context 则完全不同 。 它是一个专为开发者设计的编程接口(API) , 当开发者在他的程序里调用这个功能时 , 他是明确地指令 Gemini「把这个 URL 里的全部内容(上限高达 34MB)作为你回答下一个问题的唯一、权威的上下文」 , Gemini 会进行深度、完整的文档解析 , 理解整个文档的结构、内容和数据 。
以下是它的能力清单:
深度解析 PDF:能深刻理解 PDF 中的表格、文本结构甚至脚注 。 多模态理解:能处理 PNG、JPEG 等图片 , 并理解其中的图表和图示 。 支持多种网页文件:HTML、JSON、CSV 等常见格式均不在话下 。
官方 API 文档提供详细的配置教程 , 除此之外 , 还可以在 Google AI Studio 直接体验 。
Towards Data Science 上的一篇文章详细介绍了 URL Context Grounding , 作者 Thomas Reid 犀利地将 URL Context Grounding 评价为「RAG 的又一颗棺材钉」 。
文章地址:https://towardsdatascience.com/googles-url-context-grounding-another-nail-in-rags-coffin/
RAG 是过去几年中用于提升大语言模型回答准确性、时效性和可靠性的主流技术 。 由于大模型的知识截止于其训练数据 , RAG 通过一个外部知识库来为其提供最新的、特定性的信息 。
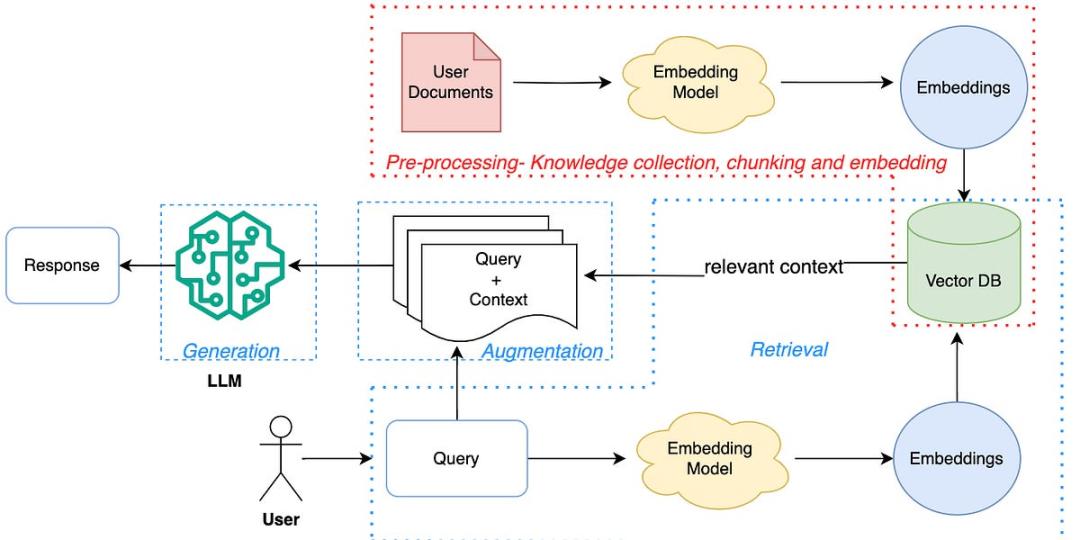
传统的 RAG 流程相对复杂 , 通常包括以下步骤:
提取内容:从数据源(如网站、文档)中抓取文本 。 分块:将长文本切分成更小、更易于处理的片段 。 矢量化:使用嵌入模型(Embedding Model)将文本块转换为数字向量 , 捕捉其语义信息 。 存储:将这些向量存储在专门的向量数据库中 。 检索:当用户提问时 , 系统首先在向量数据库中搜索与问题最相关的文本块 。 增强与生成:将检索到的相关文本块作为上下文信息 , 与原始问题一同输入给大语言模型 , 从而生成更准确、更具针对性的回答 。
RAG 架构 。 图源:Mindful Matrix
Thomas Reid 指出 , 使用 URL Context Grounding「无需提取 URL 文本和内容、分块、矢量化、存储等」 。 对于处理公开网络内容这个非常普遍的场景 , 它提供了一个极其简单的替代方案 。
开发者不再需要花费大量时间和精力去搭建和维护一个由多个组件(数据提取、向量数据库等)组成的复杂管道 , 只需几行代码就能实现更精准的效果 。
在 Thomas Reid 提供的示例中 , Gemini 仅凭一个指向特斯拉 50 页财报 PDF 的 URL , 就准确无误地提取出了位于第 4 页表格中的「总资产」和「总负债」数据 , 这是仅靠摘要绝无可能完成的任务 。
自特斯拉 SEC 10-Q 申报文件第 4 页内容 。
以下是我们在 Google AI Studio 中的测试结果 。
作者接着测试了 URL Context 挑选其他信息的能力 。 在 PDF 的末尾 , 有一封写给即将离开公司的员工的信 , 概述了他们的遣散条款 。
信中提到的退出日期用星号(***)标记 , 屏蔽退出日期的原因在脚注中给出 。
URL Context 准确识别出了脚注中的内容 。
根据所提供的文件 , 员工离职协议中的离职日期被标记为「***」 , 原因在于某些公司视为隐私或机密的特定非关键信息 , 已在公开文件中被有意略去 。
该文件包含一条对此做法的澄清说明:「本文档中某些已识别的信息已被略去 , 因为这些信息并非关键信息 , 且属于公司视为隐私或机密的信息类型 , 并已用「***」标记以示省略之处 。
根据官网介绍 , URL Context 采用一个两步检索流程 , 以平衡速度、成本和对最新数据的访问 。
当用户提供一个 URL 时 , 该工具首先尝试从内部索引缓存中获取内容 , 以提高速度和成本效益 。 如果 URL 不在缓存中(比如一个刚刚发布的页面) , 它会进行实时抓取 。
那它的能力边界在哪里呢?官方介绍中也有明确说明 。
无法翻越「付费墙」:需要登录或付费才能访问的内容 , 它无能为力 。 专用工具优先:YouTube 视频、Google Docs 等有专门 API 处理的内容 , 它不会涉足 。 有明确的容量限制:单次请求最多处理 20 个 URL , 且单个 URL 内容上限为 34MB 。
价格方面 , 它的计费方式非常直观:按处理的内容 Token 数量计费 。 你提供的 URL 内容越多 , 被转换成输入 Token 的数量就越多 , 成本也相应增加 。 这可能会间接引导开发者进行更高效的应用设计 , 即精确地提供所需的信息源 , 而非宽泛地投喂大量不相关的 URL , 从而优化成本 。
不过话说回来 , URL Context Grounding 的出现并非宣告 RAG 的终结 , 而是对其应用场景的重新划分 。 对于处理企业内网的海量私有文档、需要复杂检索逻辑和极致安全性的场景 , 构建一套自主可控的 RAG 系统依然是不可或缺的 。
【AI读网页,这次真不一样了,谷歌Gemini解锁「详解网页」新技能】URL Context 揭示了一个行业趋势:基础模型正在将越来越多的「外部能力」内置化 。 过去需要由应用层开发者承担的复杂数据处理工作 , 正在被逐步吸收到底层模型的服务中 。
推荐阅读














- AI能读取思维——脑机接口技术实现74%准确率解码内心语言
- 旗舰学不会的细节,真我GT8 Pro这次都补齐了,还有2K屏和2亿潜望
- 澎湃OS 3首发评测:UI大改终于「上岛」,这次要逆转口碑?
- 荣耀这次真急眼了,16GB+1TB跳水1495元,100倍变焦+北斗卫星消息
- 郭平解读华为“狼的精神”:有三层含义
- 专利全球第一!这次中国6G技术,又有了突破
- 2K屏+潜望长焦+7000mAh,定价四千元内,红米这次要KO大哥了
- 余承东预热新款三折叠,这次有手写笔和新颜色,发布会定档9月4日
- 苹果发布会邀请函解读:网页源代码暗藏关键细节
- 首款曲面iPhone上热搜!这次真换外观了