
文章图片
2025 年 8 月 29 日 , 由清华大学计算机系崔鹏教授团队联合稳准智能共同研发的结构化数据通用大模型「极数」(LimiX)正式宣布开源 。
此次发布标志着我国在结构化数据智能处理领域的技术突破与生态开放迈出关键一步 , 将显著降低千行百业应用结构化数据 AI 技术的门槛 , 特别是在结构化数据占主导的泛工业领域 , 「极数」大模型将助力 AI 深度融入工业生产全流程 , 破解工业数据价值挖掘难题 , 为实现智能制造与新型工业化提供关键支撑 , 推动产业技术变革和优化升级 。
在泛工业领域 , 结构化数据是核心资产——工业生产参数、设备运行数据、质量检测数据、科研实验数据等均以结构化数据形式呈现 , 其智能处理能力直接影响产业效率与科研突破 , 也是 AI 赋能工业制造的关键突破口 。
虽然通用大语言模型(LLM)凭借强大的文本理解与生成能力 , 已在内容创作、对话交互等领域实现广泛应用 , 但 LLM 在面对表格、时序等结构化数据时短板明显:数值比较、计算等基础任务易出偏差 , 更无法胜任数据分类、预测、归因等复杂任务 , 准确率难以满足真实行业需求 。 因此 , 目前工业结构化数据处理依然依赖私有数据 + 专用模型的传统范式 。
由于专用模型难泛化、不通用 , 面对不同场景需要训练多个专用模型 , 成本高、效果差 , 且难以发挥数据要素聚集的乘数效应 , 严重制约了 AI 在工业场景的落地路径 。
结构化数据通用大模型(Large Data Model LDM)则针对性解决这一痛点:不同于 LLM 聚焦文本 , LDM 融合结构因果推断与预训练大模型技术 , 既能捕捉结构化数据的内在关联 , 又具备强泛化能力 , 可跨行业适配多类任务 。
「极数」大模型可以支持分类、回归、高维表征抽取、因果推断等多达 10 类任务 , 在工业时序预测、异常数据监测、材料性能预测等场景中 , 性能达到甚至超越最优专用模型 , 实现单一模型适配多场景、多任务的通用性突破 , 为人工智能赋能工业提供了 One-For-All 解决方案 。
从技术性能到产业落地 , 「极数」大模型的核心优势已得到充分验证 。
在超过 600 个数据集上的十余项测试结果表明 , 「极数」大模型无需进行二次训练 , 已经在准确率、泛化性等关键指标上均能达到或超过专有 SOTA 模型 。
而在产业应用层面 , 「极数」大模型已成功落地多个真实工业场景 , 无需训练、部署成本低、准确率高、通用性强的特点获得合作企业的高度认可 , 成为推动工业数据价值转化的实用型技术方案 , 正加速形成面向泛工业垂直行业核心业务场景的真正智能底座 。
研发团队
「极数」模型的研发核心力量 , 由清华大学计算机系崔鹏教授牵头组建 , 团队汇聚了学术研究与产业落地的双重优势 , 其技术突破背后是深厚的科研积淀与前瞻性的方向布局 。
作为团队核心 , 崔鹏教授是我国数据智能领域的顶尖学者:他不仅是国家杰出青年科学基金获得者 , 更以突出成果两度斩获国家自然科学二等奖 , 同时获评国际计算机协会(ACM)杰出科学家 , 其学术影响力获国际学界广泛认可 。 在基础研究领域 , 崔鹏教授开创性提出「因果启发的稳定学习」新范式 , 突破传统机器学习在数据分布偏移场景下的性能局限 , 为 AI 模型的可靠性与泛化性研究奠定重要理论基础 。
2022 年 OpenAI 推出 ChatGPT 引发大模型技术浪潮后 , 崔鹏教授敏锐洞察到结构化数据方向大模型技术的发展潜力 , 迅速将研究方向从因果稳定学习拓展至结构化数据通用大模型(LDM)领域 。 依托既有理论积累 , 团队攻克结构因果数据合成、模型结构设计、跨场景泛化等核心难题 , 最终实现「极数」模型在多领域任务中的性能突破 , 为此次开源奠定关键技术基础 。
极数大模型简介
「极数」大模型将多种能力集成到同一基础模型中 , 包括:分类、回归、缺失值插补、数据密度估计、高维表征抽取、数据生成、因果推断、因果发现和分布外泛化预测等;在拥有优秀结构化数据建模性能的同时 , 极大提高了模型的通用性 。
在预训练阶段 , 「极数」大模型基于海量因果合成数据学习数据中的因果关系 , 不同于专用模型在训练阶段记忆住数据特征的模式 , 「极数」大模型可以直接在不同的上下文信息中捕捉因果变量 , 并通过条件掩码建模的方式学习数据的联合分布 , 以适应包括分类、回归、缺失值预测、数据生成、因果推断等各种下游任务 。
在推理阶段 , 极数可直接基于提供的上下文信息进行推理 , 无需训练即可直接适用于各种应用场景 。
模型技术架构
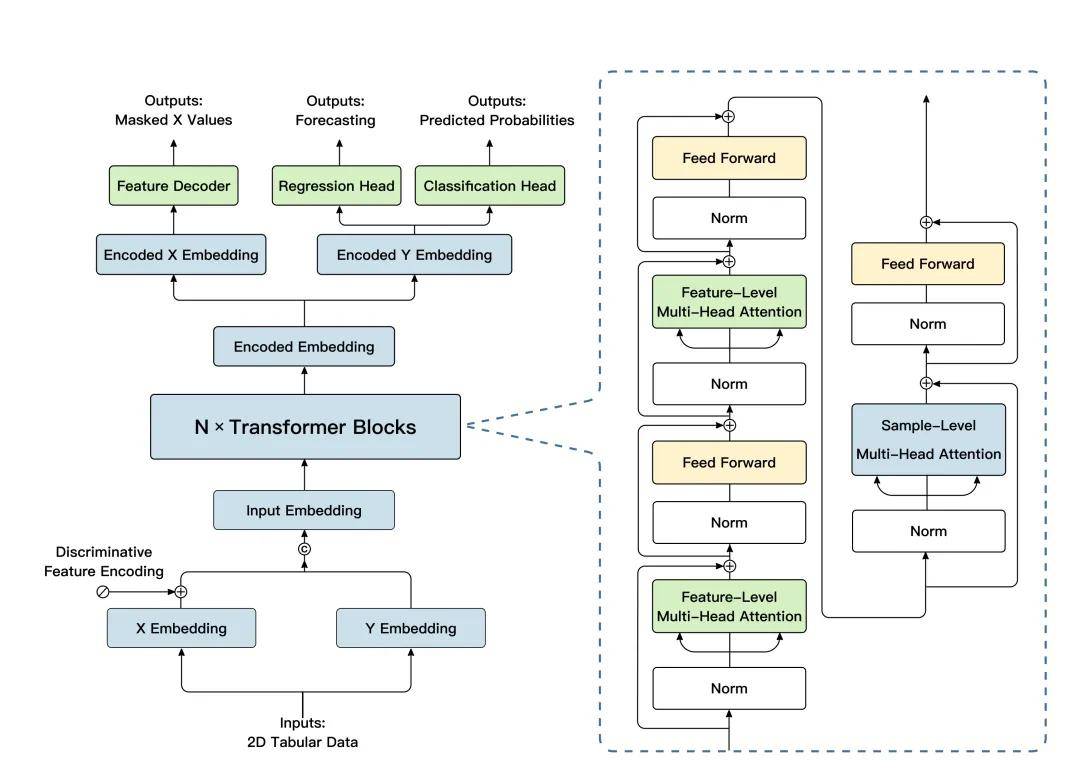
「极数」大模型沿用了 transformer 架构 , 并针对结构化数据建模和任务泛化进行了相关的优化 。
「极数」大模型先对先验知识库中的特征和目标分别进行 embedding;之后在主要模块中 , 在样本和特征维度上分别使用注意力机制 , 来聚焦关键样本的关键特征 。
【清华崔鹏团队LimiX:首个结构化数据通用大模型,性能超越SOTA】最终 , 提取到的高维特征被分别传入 regression head 和 classification head , 实现对不同功能的支持 。
推荐阅读















- 前中国商飞团队转战eVTOL、合作滴滴出行,拿下数亿元A轮融资|硬氪首发
- 华为海思芯片技术被窃取,估值超3亿!前高管离职后拉拢团队,14人获刑
- 清华辍学、斯坦福睡地板,华人小哥用AI社交挑战Meta,融资数千万
- 哈佛大学团队:AI如何像人类一样从少量例子中快速学会新技能
- 苹果AI华人总监跳槽Meta,核心团队再-1,库克被迫求助谷歌
- 小扎“亿元俱乐部”刚组就被拆,千人AI团队面临裁员,高管也得走
- 从繁杂技巧到极简方案:ROLL团队带来RL4LLM新实践
- 微软团队:让AI推理\短小精悍\而非冗长啰嗦,效果竟然更好?
- 清华校友出手8B硬刚GPT-4o!单一模型无限工具调用,终结多智能体
- 一张图0.1秒生成上半身3D化身!清华IDEA新框架入选ICCV 2025