
文章图片
文章图片

文章图片

文章图片

文章图片

文章图片
文章图片

文章图片

文章图片
文章图片
文章图片

编辑:桃子 好困
【新智元导读】大模型再强 , 也躲不过上下文限制的「蕉绿」!MIT等团队推出的一套组合拳——TIM和TIMRUN , 轻松突破token天花板 , 让8b小模型也能实现大杀四方 。
一直以来 , 上下文限制 , 如同「紧箍咒」限制了模型的潜能 。
如今 , 一种全新突破性方案已经到来 。
来自MIT、普林斯顿、特拉维夫大学等机构联手 , 重磅推出「线程推理模型」(TIM)——一种专为递归和分解式问题求解而训练的大模型 。
论文地址:https://arxiv.org/pdf/2507.16784
与此同时 , 研究团队还提出了「推理运行时」引擎TIMRUN , 让长程推理成为现实 。
具体来说 , 他们将自然语言建模为「推理树」 , 由任务、思考、递归子任务、结论组成 , 实现了多轨并行推理 。
此时 , 树的「长度」和「深度」成为了度量的标准 。
在生成过程中 , TIMRUN就像一个内存管家 , 只保留当前最需要的token键/值状态 , 可以反复利用推理中的位置编码和GPU内存页 。
TIM+TIMRUN这套组合拳 , 让推理效率直接飙升 。
实验结果显示 , 即便在90%的内存占用下 , TIM能实现高吞吐性能 。
同时 , 在数学任务中 , TIM可以提供给精准推理 , 信息检索挑战应对自如 , 能轻松完成需要长程推理和跨多步工具调用的任务 。
LLM脑容量不够?剪掉无用记忆
大模型的本质 , 是token序列生成器 。
不论是循环神经网络(RNN) , 还是Transformer , 都受限于一个致命的问题:上下文窗口 。
比如 , Deepseek R1标配的128k上下文 , 在现实中 , 一个复杂任务动不动就超出了这一上限 。
若是LLM再从外部一边调用工具 , 一边推理 , token只会越跑越多 , 最终导致GPU内存爆表 。
更别提 , 传统的「线性序列」方式 , 全部记住了所有上下文 , 内容占用更高 。
为了破解记忆瓶颈 , 开发者们通常将复杂工作流 , 拆分为多个模块 , 然后再交由AI智能体分工协作 。
然而在实操中 , 「多智能体架构」出现了协调难、延迟高等问题 。
在研究人员看来 , 推理并非是一个线性的过程 , 而是一种递归结构化的 。
这一过程 , 就如同编码任务中人类大脑的一样 , 我们会「选择性记忆」 , 在进行下一任务前 , 只保留关键信息 , 其余清空才能专心搞定当前任务 。
基于这些观察 , 研究团队将推理轨迹建模为一个「递归的子任务树」 。
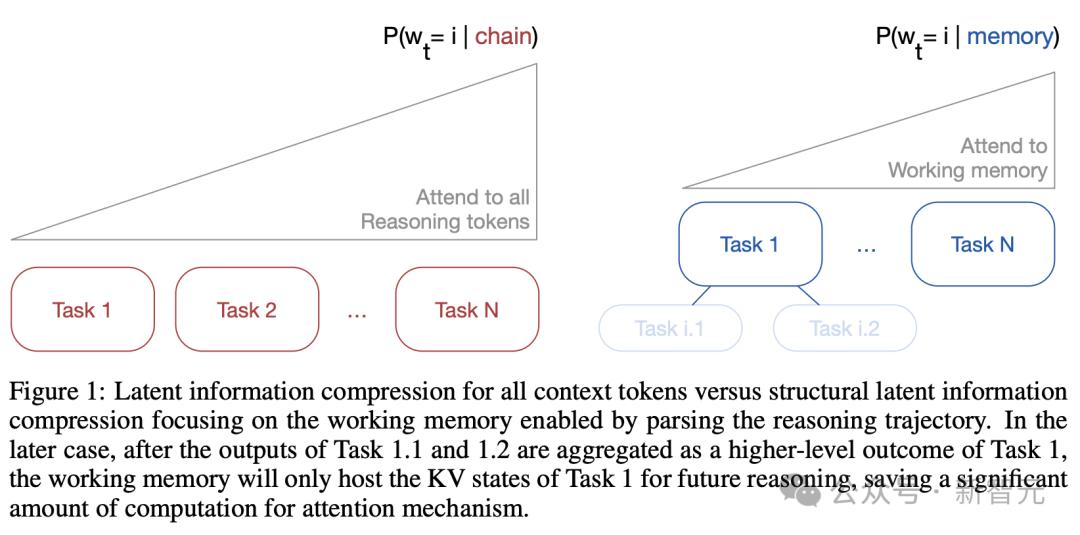
推理时 , AI只需关注当前子任务 , 剪掉无关的「枝叶」 , 大幅减少内存占用 , 如下图1所示 。
通过剪枝无关子任务 , 模型只需聚焦于一个选择性的「工作记忆」
如前所述 , 论文中 , 研究团队提出的「线程推理模型」(TIM)和TIMRUN推理引擎 , 彻底颠覆了传统LLM的推理方式 。
TIM就是一个会拆解任务的超级AI , 能够轻松识别分解出的子任务、工具参数以及递归的层级关系 。
【清华校友出手8B硬刚GPT-4o!单一模型无限工具调用,终结多智能体】TIMRUN是TIM的「最佳拍档」 , 专为推理树优化内存管理 , 两者结合实现了以下三大突破:
- 支持几乎无限的长程推理 , 突破输出token上限
- 在复杂任务中实现高效的单模型推理 , 具备更高解码吞吐量和内存效率
- 开启最简化的智能体构建方式:给TIM提供工具包 , 启动一次推理 , 即可获得具备智能体特性的推理轨迹 。
TIM:8b训练 , 复杂任务切成块
线程推理模型(TIM) , 直观可以理解为 , 一颗推理树有不同分支(子任务) 。
它采用了Thread-2框架 , 将推理过程建模为一个「任务树」 , 也就是说 , 推理的基本单元是——任务 。
每个任务由四个部分组成:思考、工具调用、子任务、结论 。
与上一代Thread推理框架相比 , Thread-2做出了多项改进 。
它能够访问工作记忆 , 包含系统提示、用户输入 , 以及尚未被剪枝的任务 , 让LLM实现端到端推理 , 一次调用就能完成推理
同时 , Thread-2还采用了一个固定大小的子任务「堆栈」结构来执行剪枝 , 即动态清理无关子任务 , 只保留关键信息 , 让内存占用大幅降低 。
此外 , 其推理结果可以直接高效地解码为JSON字典(JSON dictionary) , 告别了复杂的符号操作 。
如下实践中 , 研究团队以如下模式进行JSON解码 , 并结合搜索和网页阅读工具作为示例 。
需要注意的是 , 多个工具调用可以在一次解码过程中处理 。
传统方法中 , 一个推理过程需要20次工具调用 , 可能要重复计费20次初始token 。
而在TIM生成过程中 , 它将将工具响应以JSON字典字符串形式返回到「推理引擎」 , 在转化为新的输入token批扩展KV缓存 。
这样一来 , 就实现了模型一次调用 , 即可调用多个工具 , 避免了延迟和开销 。
训练细节
研究中 , 团队对Qwen3-8b进行了后训练 , 不用复杂提示工程 , 最终生成Thread-2推理结构 。
为此 , 他们打造了一个「合成训练集」 , 覆盖了2万条openr1-math-220k数学问题、2万条研究类问题、6千条ToolBench问题 。
基于以上数据训练后 , 团队又在openR1-math-220k上 , 利用GRPO对模型进行了强化学习 。
训练完成后 , 就得到了「线程推理模型」(TIM) 。
TIMRUN:保留关键信息 , 复用GPU
TIM结构化输出确实能够大幅提升推理性能 , 另一个问题来了——如何实现部署?
为此 , 研究团队为TIM开发了一个配套的引擎TIMRUN 。
为了实现超过输出限制的长时推理 , TIMRUN必须支持在输出生成过程中 , 复用GPU内存和位置嵌入 。
那么 , 研究中它是如何做到的呢?
子任务剪枝
TIMRUN的核心绝技之一 , 就是子任务剪枝(Subtask Pruning) 。
它的逻辑非常简单粗暴 , 在推理时 , 保留当前任务需要的关键信息 , 把不必要的任务细节直接丢掉 。
这个灵感 , 来自一个经典的思想实验——怎么把大象装进冰箱?只需三步 , 开门、塞进去、关门 。
为了实现这个设计 , TIMRUN维护了一个剪枝缓冲区 , 即一个栈 。
它用来临时缓存少量可剪枝的子任务 , 只保留足够的冗余 , 以确保信息流的无损传递 。
子任务剪枝的过程 , 如下图3所示 。
具体来说 , 当TIM在某个任务中解码时 , TIMRUN会动态地把已完成子任务对应的token的KV状态从GPU内存中清除 。
同时 , TIMRUN还引入了「分页注意力」 , 把KV缓存分块处理 , 分页大小为1 , 剪枝时只针对单个token序列 , 推理则由FlashInfer加速 。
端到端多步工具调用
TIMRUN的解决方案是:在运行时直接发起工具调用 , 而不是把工具参数回传给客户端 , 如下图4所示 。
这种方式大大减少了模块之间的通信 , 让智能体的开发和部署更简单 。
关键在于 , 推理链中的每个token只会传输到 TIMRUN 一次 , 从而彻底消除了冗余的token传输 , 并最大限度地减少了通信开销 。
实验结果
总的来说 , 研究人员观察到的关键结果有三个:
- 维持工作记忆 , 而非计算全部上下文Token的注意力权重 , 并不会损害推理准确性 。
- 剪除不相关上下文 , 可以提升语言模型的推理准确性并减少幻觉现象 。
- 面对密集的内存访问与操作 , TIMRUN可以保持极高的吞吐量 。
推理
在考验STEM领域知识与推理能力的评测中 , TIM模型仅凭8B的参数规模就取得了卓越的成绩 。
- MATH500最高69.6%(略逊Llama 3.1 405B的73.8% , 但超越Llama 3.1 70B的65%)
- MMLU-STEM500最高88.4%
- AMC 2022最高60.5%
- AMC 2023最高80.0%
- AIME 2024最高46.7%(略逊GPT-4.1的48.1% , 但超越GPT-4.5的36.7%)
- GPQADiamond最高48.5%(略逊Llama 3.1 405B的51.1% , 但超越Gemma 3 27B的42.4%)
研究
相比起传统的AI智能体工作流 , TIMRUN可以将多跳工具的使用 , 作为一种无缝的、端到端的大语言模型API调用来处理 , 无需依赖任何智能体框架或复杂提示词 。
Datacommons QA
Datacommons QA考验的是模型在多跳信息检索、工具响应处理以及推理方面的能力 。
TIM仅需一条简洁的系统提示词和关于工具的基本信息 , 包括工具描述、输入参数和输出格式 , 便可对训练期间未曾遇到的新任务 , 表现出良好的泛化能力 。
与基线方法相比 , 它在三个关键领域展现出更高的效率:
- 无需精心构建的少样本学习示例和任务特定的提示词 , 一条简单的系统提示词便足以获得优异性能 。
- 无需长达4000 token的提示词 , 极大地降低了生成过程中的计算开销 。
- 在子任务完成并从剪枝缓冲区移除时会自动处理工具响应 , 开发者便无需再为处理工具响应而开发定制逻辑 。
Browsecomp
Browsecomp是一项针对深度研究型智能体的挑战性基准测试 。
要回答这里的问题 , 模型需要对输入进行分解 , 并使用工具从互联网筛选和检索相关信息;有时 , 还需深入探究特定网页的细节 , 并依据给定条件对发现进行验证 。
在没有任何智能体设计的情况下 , TIM-8b的表现便已经优于具备浏览功能的GPT-4o , 而Tim-large更是取得了与构建在Deepseek R1上的ReACT智能体相媲美的性能 。
这些发现印证了研究人员的假设:一个能通过递归分解子任务和剪枝其工作记忆来自主管理上下文的模型 , 其性能可以匹及采用更复杂实现的智能体 。
效率与可扩展性
吞吐量提升
上下文剪枝与注意力机制之间存在一种权衡关系——剪枝上下文虽能加速注意力计算 , 却也引入了额外的内存开销 。
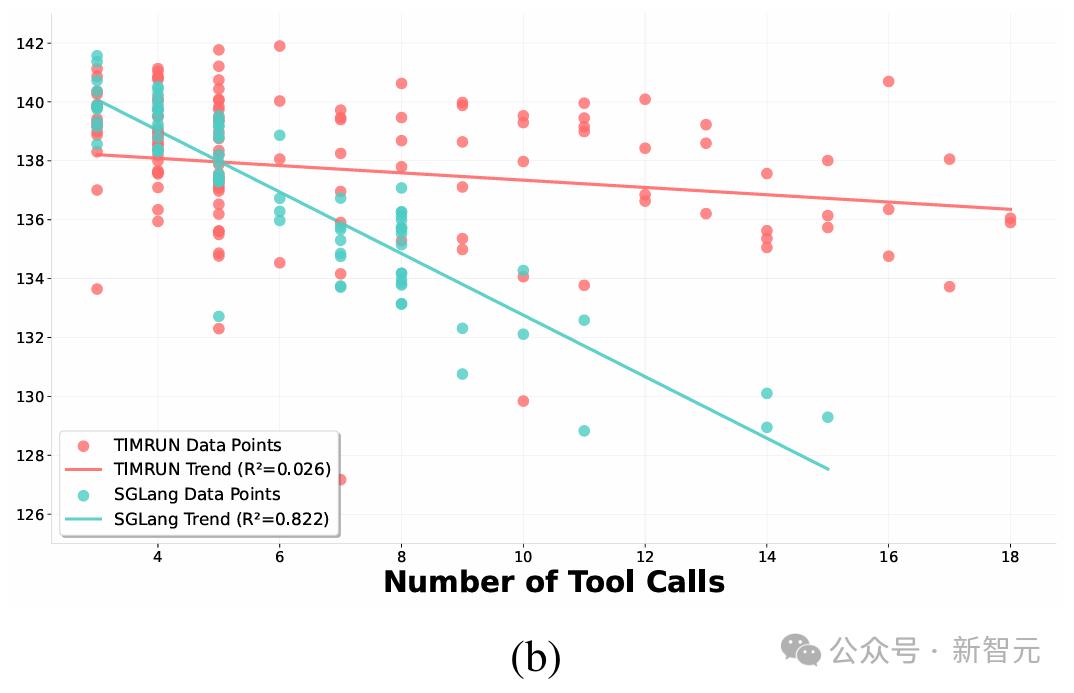
实验结果表明 , TIMRUN系统的性能优于朴素的内存操作实现以及强大的SGLang基线 。
更高效的工具使用
随着工具调用次数的增加 , SGLang的吞吐量因推理步骤和工具响应所产生的增量上下文及token缓存日益复杂而迅速下降 。
相比之下 , 得益于自动化的上下文管理机制 , 即便工具使用规模扩大 , TIMRUN仍能保持相对稳定的吞吐量 。
这使得TIM-8b模型无需任何智能体框架或针对特定任务的后训练 , 即可在BrowseComp基准测试上取得优异性能 。
尤其是 , 借助子任务剪枝 , TIMRUN可以在单次推理中支持超过30次的工具调用 。
作者介绍
论文一作罗鸿胤是麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)的研究员 , 也是Subconscious Systems的联合创始人兼CTO 。
他于2022年获得麻省理工学院电子工程与计算机科学(EECS)博士学位 , 师从James Glass教授 。 并在此前获得清华大学工学学士学位 , 师从刘知远教授 。
罗鸿胤的研究方向包括构建高效、透明、具备复杂推理能力的语言模型 , 以及支持智能体长期推理和工具调用的基础设施 。
他的代表性工作包括开发TIM模型(Thread Inference Model)和TIMRUN推理系统 , 这一组合实现了可扩展、结构化、递归的智能体推理能力 。
其中 , 全新推理框架突破了语言模型在传统上下文长度上的限制 , 显著提升了长周期智能体的吞吐量与推理效果 , 并大幅降低了上下文工程的开发和运行成本 。
参考资料:
https://arxiv.org/pdf/2507.16784
推荐阅读












- 一张图0.1秒生成上半身3D化身!清华IDEA新框架入选ICCV 2025
- 一位清华00后女生爆红
- 小米 OV 荣耀出手,这功能终于来了!
- 清华系制霸MetaAI天团
- 清华博士团队自供电传感器技术,获近千万天使轮融资|硬氪首发
- 字节x清华推出商用级视频换装模型DreamVVT,保真度显著领先SOTA
- 又是北大校友!ChatGPT Agent华人研发主力被Meta挖走了
- 扎克伯格看OpenAI直播挖人,北大校友孙之清加入Meta
- 让AI大模型\减肥\:清华大学和微软联手解决对话机器人内存爆
- 清华大学汪玉教授:当AI重塑产业,新时代的育人思考