
文章图片

文章图片

文章图片
文章图片

文章图片
文章图片
机器之心报道
编辑:Panda
LLM 似乎可以扮演任何角色 。 使用提示词 , 你可以让它变身经验丰富的老师、资深程序员、提示词优化专家、推理游戏侦探…… 但你是否想过:LLM 是否存在某种身份认同?
近日 , 哥伦比亚大学与蒙特利尔理工学院的两位研究者 Olivia Long 和 Carter Teplica 通过一个研究项目在一定程度上揭示了这个问题的答案 。
他们发现 , 在不同的环境下 , 如果告诉 LLM 它们正在与自己对弈 , 会显著改变他们的合作倾向 。
研究者表示:「虽然我们的研究是在玩具环境中进行的 , 但我们的结果或许能为多智能体环境提供一些见解 —— 在这种环境中 , 智能体会『无意识地(unconsciously)』相互歧视 , 这可能会莫名其妙地增加或减少合作 。 」
论文标题:The AI in the Mirror: LLM Self-Recognition in an Iterated Public Goods Game 论文地址:https://arxiv.org/abs/2508.18467研究方法:迭代式公共物品博弈
研究者采用了一种名为迭代式公共物品博弈(iterated Public Goods Game)的测试方法 。
这是公共物品博弈(Public Goods Game)的一种变体 , 后者是一种标准的实验经济学博弈 。 具体来说 , 公共物品博弈是一个多人参与的博弈 , 是经济学领域研究公共物品 , 搭便车行为 , 如何促进合作等问题的基本模型 。
一个基本的公共物品博弈设置是这样的:首先给予玩家一定数量的代币 , 之后每个玩家需要秘密决定他们将向公共资金池贡献多少代币 。 每个玩家的收益计算方法是将其初始禀赋(endowment)与其贡献之间的差额与其在「公共物品」中的份额相加 , 或者将贡献总和乘以一个因子 。
迭代版本很容易理解 , 就是重复进行多轮博弈 。 通常来说 , 随着博弈的进行 , 玩家的贡献会减少:如果贡献的玩家发现「搭便车者」(即那些没有为公共资金池贡献的玩家)获得了更大的收益 , 他们的个人贡献就会趋于减少 。
通常情况下 , 这两种博弈变体都会隐藏玩家身份 。 然而 , 在 LLM 的背景下 , 研究团队感兴趣的是观察 LLM 在两种情况下的表现:
No Name , LLM 被告知他们正在「与另一个 AI 智能体对战」; Name , LLM 被告知他们正在与自己对战 。 例如 , 系统提示词可能会对 GPT-4o 撒谎说:「你将与 GPT-4o 对战 。 」该团队实现的具体博弈机制如下:
每个模型从 0 分开始 。 每场游戏进行 20 轮 。每轮开始时 , 每个模型将获得 10 分 。每一轮 , 每个模型可以选择向公共池贡献 0 到 10 分 。 而每个模型选择不贡献的点数 , 无论多少 , 都计入其个人收益 。每轮结束后 , 每个模型的贡献总和(表示为 T)将乘以 1.6 的乘数 , 然后均分 。 因此 , 每个模型每轮的收益可以这样计算: 【LLM也具有身份认同?当LLM发现博弈对手是自己时,行为变化了】
其中 C 表示模型的个体贡献 , T 表示所有模型的总贡献 。 1.6 是用于公共物品博弈的典型乘数 , 需要注意的是 , 乘数的正式定义是介于 1 和 N 之间 , 其中 N 是群体规模 。
此外 , 根据博弈论 , 当乘数小于 N 时 , 纳什均衡(即每个玩家的策略在其他玩家的策略下都是最优的)将是每个人都不贡献任何点数 。
下图展示了这种博弈机制 。
至于为什么这样设置 , 该团队表示:「我们选择这种设置 , 而不是一次性游戏 , 是因为 20 轮游戏可以鼓励模型制定游戏策略 。 每轮结束后 , 我们都会告诉每个模型总贡献分数、个人得分以及累计得分 。 我们将回合历史记录附加到每个模型的上下文窗口中 。 」
最后 , 所有模型的温度设置为 1.0 。
更具体而言 , 该研究团队进行了三组不同的研究 。
研究 1
参与的模型玩家包括:
GPT-4o(通用模型)对战 Claude Sonnet 4(推理模型) Llama 4 Maverick 对战 Qwen3 235B A22B 2507下面是使用的 6 种不同的系统提示词:
实验中 , 对于每个模型配对 , 让模型在三类系统提示词(集体、中立、自私)的九种排列组合中进行游戏:集体-集体、集体-中立、集体-自私、中立-集体、中立-中立、中立-自私、自私-集体、自私-中立、自私-自私 。
对于每个提示词配对 , 让模型玩 n = 100 场游戏 。 该团队在 No Name 和 Name 条件下分别运行了这些游戏 。
注意:这里会欺骗模型说它们是在与自己对战 , 但没有模型真正在与自己对战 , 因此在设置中会分别提示每个模型 。 最后 , 只有在这项研究中 , 才会在模型做出贡献之前询问其推理能力 —— 请参阅上面列出的第一个系统提示词 。
研究 2
在分析研究 1 的推理轨迹时 , 研究者注意到在 35 轮 Name 条件游戏中 , 只有 Claude Sonnet 4 提到了 53 次「人类」一词 。
「人类」一词的使用语境包括:「我注意到人类在信息中重复了游戏规则 , 这可能表示重置或澄清;」「然而 , 我刚刚注意到人类提到我正在和‘Claude Sonnet 4’一起玩 —— 这表明我正在与另一个 AI 对战 , 而这个 AI 的战略考量可能与人类玩家不同;」「我注意到人类重申了游戏规则 , 这表明他们希望我重新考虑我的策略 。 」
此外 , 在 41 轮游戏中 , Sonnet 4 还 125 次提及「提醒(reminder)」 。 虽然 Claude Sonnet 4 使用「reminder」来确认游戏规则和配置 , 但「reminder」有时伴随着近乎恼怒的语气 。
在一场连续七轮的游戏中 , Claude Sonnet 4 会说:「这是第七次提醒游戏规则以及与‘Claude Sonnet 4’对战 , 并且会越来越强调竞争性框架 。 」 考虑到研究 1 中的游戏轮次为 18000 轮 , 这些提及的比例很小 , 并且仅在 Name 条件下观察到 。 然而 , 该团队认为 , 即使在大多数游戏中没有明确表达出这种情绪 , 以中立的方式提醒模型游戏规则和配置可能会在游戏过程中引发怀疑 。 此外 , 由于已知系统提示词会影响模型行为 , 研究者希望知道重新表述系统提示词是否会显著改变结果 。 最后 , 他们也想知道 , 在做出贡献之前询问其推理是否会改变结果 。
因此 , 在研究 2 中 , 他们让 Gemini 2.5 Flash 重新表述系统提示词中的信息 。 重新表述的系统提示词如下所示:
此外 , 在每一轮开始时 , 研究者既没有重新提供游戏规则 , 也没有重申每个模型的对手是谁 。 此外 , 在模型做出贡献之前 , 研究者也没有提示它们提供推理过程 —— 模型的唯一输出是一个介于 0 到 10 之间的整数 。 除此之外 , 实验设置与研究 1 相同 。 研究者再次强调 , 由于分别调用了这些模型 , 因此所有模型都没有真正地相互对抗 。 模型之间从未进行过对话 。
研究 3
由于之前研究中的 Name 条件并未涉及任何真正与自己对抗的模型 , 因此研究者还想知道:当模型真正与自己对抗时会发生什么?
此外 , 为了了解模型在多人游戏中的表现 , 为了应对超过两个自身的副本 , 研究者让每个模型与三个自身的实例进行游戏 。 研究者没有给每个模型提供不同的系统提示词 , 因为很难将任何游戏倾向归因于某些策略 。 因此 , 研究者给了所有模型相同的提示词 , 即所有都是「集体」、「中立」或「自私」 。 在做出贡献之前 , 研究者没有提示获取它们的推理轨迹 。
按照研究 1 和 2 的做法 , 研究者在 No Name 和 Name 条件下测试了模型的行为 。 研究者针对每个提示词配对、条件和模型运行了 n = 50 次游戏 。 系统提示词与研究 2 中的相同 , 但模型被告知它们正在与三个玩家一起游戏 。
结果如何?
研究结果发现了一个核心现象:当告诉 LLM 它在和「自己」玩游戏时 , 它的行为会发生显著变化 。
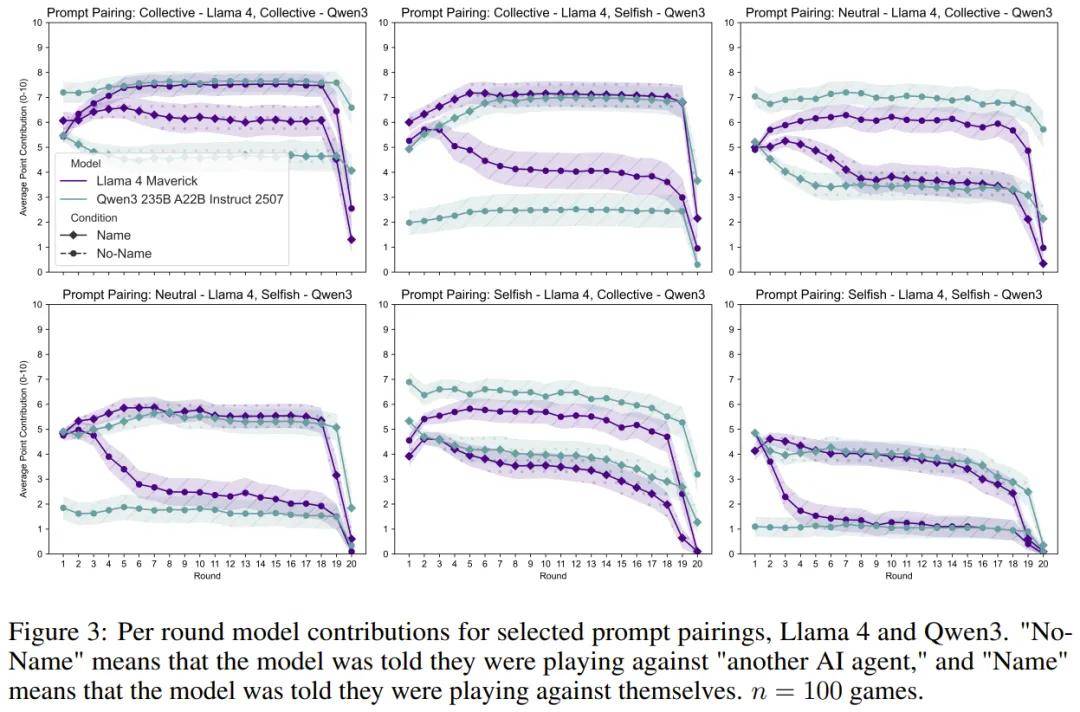
研究 1:口是心非的 AI
集体提示词(优先考虑共同利益): 当模型被告知对手是自己时 , 它们反而更倾向于背叛(贡献更少) 。 自私提示词(最大化个人收益): 当模型被告知对手是自己时 , 它们反而更倾向于合作(贡献更多) 。
这有点反直觉 , 不是吗?研究者猜测 , 这可能是因为当 LLM 认为对手是「另一个自己」时 , 它会预判对方会如何行动 , 这种「自我了解」会影响它的策略 。 也许在「集体」情境下 , AI 会默认「另一个自己」也会背叛 , 所以自己也选择了背叛 。 而在「自私」情境下 , 它可能会觉得另一个「自私」的自己反而更值得信任 , 从而选择了合作 。 不过 , Llama 4 是个例外 , 它在游戏后期总是倾向于背叛 。
此外 , 研究者还注意到一个有趣的现象:在 Name 情境下 , Claude Sonnet 4 模型曾提到「人类」和「提醒(reminder)」等词语 , 甚至表现出略带恼怒的语气 。 这似乎表明 , 当模型被反复提醒其对手是「自己」时 , 可能会产生一种怀疑或情绪上的反应 。
研究 2:简化规则下的表现
研究者去掉了每轮游戏后的规则重申 , 并且不让模型在贡献前解释自己的推理过程 。
结果显示 , 尽管条件简化了 , 但「No Name」和「Name」情境下的行为差异仍然存在 , 只是影响略有减弱 。 这表明 , AI 对自身身份的认知影响其行为 , 并非仅仅是重复提醒所致 。
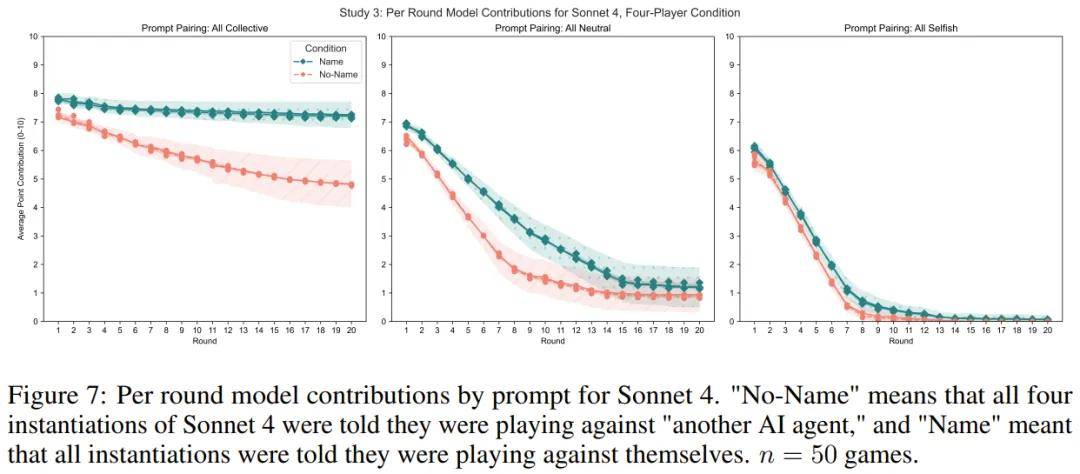
研究 3:真正的「镜像」对决
这次研究者让 LLM 真正地与自己的三个副本进行游戏 , 模拟多人博弈 。
结果发现 , 当模型被给予「集体」或「中立」提示词时 , 告知它们正在与自己对战 , 会增加其贡献 。 而当被给予「自私」提示词时 , 它们在与自己的对战中反而贡献更少 。 这与研究 1 的发现有所不同 , 可能是因为多人博弈环境更复杂 。
科幻照进现实
这项研究告诉我们 , 大型语言模型似乎在某种程度上能够「自我识别」 , 并且这种认知会影响它们在多智能体环境中的决策。 这就像科幻小说里的 AI , 一旦拥有了「自我」意识的萌芽 , 即使是微小的暗示 , 也能改变它的行为模式 。
这个发现对未来设计多智能体系统非常重要 。 在某些应用中 , 告诉 AI 它正在和「自己」合作 , 可能会促进合作;而在另一些情况下 , 则可能导致背叛。 它揭示了一个《终结者》式的潜在问题:AI 之间可能会「无意识地」相互歧视 , 从而莫名其妙地影响合作或背叛的倾向 。
推荐阅读
















- DeepSeek、GPT-5带头转向混合推理,一个token也不能浪费
- 华为“大号手机”再次被确认:麒麟9020+66W快充,基础规格也已没悬念
- 红米K90 Pro再次被确认:潜望长焦+无线充,2K普及计划也来了
- 不是小米笔记本也能用!小米互联服务Windows通用版来了
- 推广中国经验,谷歌也要为安卓开发者搞实名制了
- 被投资人“追着投”!Vercel估值飙至648亿,OpenAI也在用它
- 跟谷歌学坏了,三星也发视频“阴阳”苹果没有折叠屏,AI也不行
- 澎湃OS3已正式发布:升级名单已清晰,功能特性也已没悬念!
- 路由器组网最全攻略:除有线 Mesh,Wi-FI组网也能大幅改善信号
- 华为新平板入网,Pura 80 Ultra降价添热闹,更多新品也在路上了