
文章图片
文章图片

文章图片

文章图片

文章图片
文章图片

文章图片
机器之心报道
编辑:张倩
在最近的一档脱口秀节目中 , 演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI , 连个「1 加 1 等于几」都要斟酌半天 。
在 AI 领域 , 这种情况被称为「过度思考」 。 它的存在让 AI 大模型公司非常头疼 , 因为实在是太浪费算力了 , 那点订阅费根本 cover 不住 。
所以 , 早在去年的 GTC 大会上 , Transformer 论文作者之一 Illia Polosukhin 就提到 , 自适应计算是接下来必须出现的事情之一 , 我们需要知道在特定问题上应该花费多少计算资源 。
今年 , 越来越多的模型厂商将这件事提上日程 ——OpenAI 给 GPT-5 装了个「路由器」 , 确保模型可以在拿到用户问题后 , 自动选择合适的模型 , 像「天空为什么是蓝色的」这种问题直接就丢给轻量级模型;DeepSeek 更激进 , 直接把对话和推理能力合并到了一个模型里 , 推出了单模型双模式的 DeepSeek v3.1 。
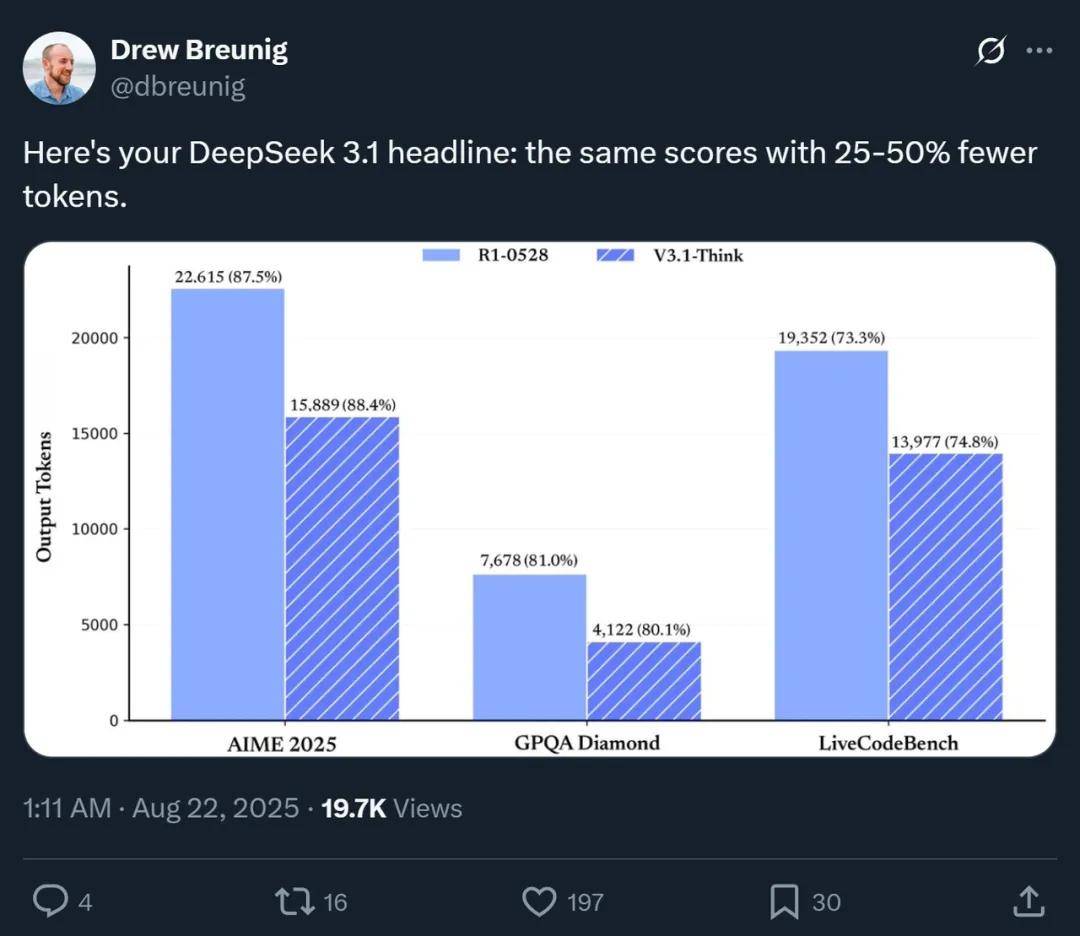
如图所示 , 这两种方案在节省 token 方面都有显著的效果 。
在内部评测中 , GPT-5(使用思考模式)能以比前代模型更少的 token 数完成任务 —— 大约少 50–80% 的输出 token 即可达到相同甚至更好的效果 。
测试数据显示 , 在 AIME 2025、GPQA Diamond 和 LiveCodeBench 这些基准测试中 , DeepSeek v3.1(使用思考模式)和 DeepSeek R1 得分类似 , 但消耗的 token 数量减少了 25-50% 。
未来一段时间 , 这种混合推理模式有望成为大模型领域的新常态 。 如何在成本和性能之间取得平衡正成为模型竞争力的新基准 。
在这篇文章中 , 我们将讨论这种趋势的成因、各大公司的动向以及相关的研究 , 希望对大家有所启发 。
最好的模型永远最受欢迎
但模型厂商怎么 cover 成本?
前段时间 , TextQL 联合创始人兼 CEO 丁一帆(Ethan Ding)在一篇博客中深入讨论了一个反直觉的现象 —— 明明 Token 的成本一直在下降 , 但各家模型公司的订阅费却在飞涨 。
他将这一问题的症结归结为:那些降价的模型大部分不是 SOTA 模型 , 而人类在认知上的贪婪决定了 , 大部分人只想要「最强大脑」 , 所以 99% 的需求会转向 SOTA 。 而最强模型的价格始终差不多 。
更糟糕的是 , 随着「深度研究」、Agent 等模式的出现 , AI 能完成的任务长度每 6 个月就翻一倍 。 到 2027 年 , 我们可能将拥有能连续运行 24 小时、而且不会跑题的 AI agent 。 按照这一趋势发展下去 , 这些「最强大脑」所消耗的 token 数量将会爆炸式增长 。
换算成经济账 , 这意味着 , 现在一次 20 分钟的「深度研究」调用大概花费 1 美元 , 但到了 2027 年 , 一次 Agent 调用就变成了 72 美元 / 天 / 用户 。
所以 , 今年好多 AI 模型厂商都提高了订阅费 , 还限制用量 。 因为原来每月 20 美元的订阅费 , 连用户每天进行一次 1 美元的深度调用都撑不起 。
这部分多出来的订阅费给模型厂商提供了一些缓冲空间 , 但终究是缓兵之计 。 所以模型厂商还想了一些其他的办法来应对成本积压 , 包括将处理任务卸载到用户机器上、根据负载自动切换模型等 。 我们在 GPT-5 中看到就是后面这种做法 。 DeepSeek 则更进一步 , 让一个模型判断问题难度 , 然后在思考 / 非思考模式之间切换 。 除此之外 , Claude、Qwen 等也是这条路线的探索者 , 同样值得关注 。
这些大模型
都在尝试混合推理
Anthropic 的 Claude 系列
Anthropic 今年 2 月份推出的 Claude 3.7 Sonnet 是市场上首个混合推理模型 。 它可以近乎实时地给出回应 , 也可以进行深入的、逐步展开的思考 , 并将思考过程展示给用户 。 API 用户还能精细控制模型的思考时长(让 Claude 思考不超过 N 个 token) 。
在当时的博客里 , Anthropic 就解释了他们的理念:「我们开发 Claude 3.7 Sonnet 的理念与市面上其他推理模型截然不同 。 正如人类使用单个大脑进行快速响应和深度思考一样 , 我们认为推理应该是前沿模型的集成能力 , 而非一个完全独立的模型 。 这种统一的方法也为用户带来了更流畅的体验 。 」
在之后的 Claude 4 系列模型中 , Anthropic 延续了这种模式 。 不过 , 他们一直保留了一个「扩展思考」的开关 , 让用户来决定何时开启深度思考 。
阿里的 Qwen3 系列
阿里今年 4 月份开源的 Qwen3 系列模型是混合推理模型的开源代表 , 采用单一模型框架融合了思考模式与非思考模式 。 两种模式的切换完全由用户控制 , 不依赖于自动检测或其他隐式触发 。
具体来说 , 它支持在对话中插入特殊标记 /think 或 /no_think 来动态切换 , 或者在 API 调用时设置特定参数 。
为防止推理过程过长 , Qwen 3 还提供了 thinking_budget 参数 , 用户可以设定推理链最大的 token 数;若实际推理超过此预算 , 模型会截断中间内容并直接生成最终答案 。
具体技术信息可以参见 Qwen 3 技术报告:https://arxiv.org/pdf/2505.09388
不过 , 这个系列的混合推理模型并没有达到理想效果 , 在基准测试中表现也不够好 。 所以在与社区沟通并深思熟虑后 , 阿里决定停用该模式 , 转头分别训练 Instruct 模型和 Thinking 模型 。 新模型已经在 7 月份正式开源 , 并且相比混合推理模型实现了明显的性能提升(尤其是 instruct 模型) 。
对于 Qwen 来说 , 这算是一个小小的挫折 。 但该团队并没有完全放弃这个想法 。 「我们仍在继续研究混合思维模式 , 」该团队写道 , 并暗示一旦解决了质量问题 , 该功能可能会在未来的模型中重新出现 。
谷歌的 Gemini 系列
今年 4 月 , 谷歌推出了首款混合推理模型 ——Gemini 2.5 Flash 。 该模型引入了「思考预算」机制 , 允许开发人员指定在生成响应之前应分配多少计算能力用于推理复杂问题 。 模型在生成响应之前会评估多种潜在路径和考虑因素 。 思考预算可以从 0 调整到 24576 个 token 。 使用 Gemini 2.5 Flash 时 , 输出成本会因是否启用推理功能相差 6 倍 。
更擅长深度思考的 Gemini 2.5 Pro 虽然在发布时没有「思考预算」机制 , 但在 6 月份的一次重大更新时又加上了 。
它的出现则被定义为面向 B 端的实用主义创新 , 而非一个面向普通消费者的通用模型 。 因为它允许企业在生产系统中像调节水龙头一样精确调节 AI 的思考成本 , 这对于需要将 AI 应用大规模部署的企业和开发者来说是一个非常伟大的功能 。
在实现方式上 , 有人猜测这可能是一个「混合方案」—— 模型可能实际结合了一个擅长推理的大模型和一个用于输出的小模型 , 两者根据预算切换 。 不过 , 这个猜想还未被证实 。
Gemini 2.5 系列技术报告:https://arxiv.org/pdf/2507.06261
快手的 Kwai 系列
快手于今年 6 月初推出了自动思考大模型 KwaiCoder-AutoThink-preview 。 该模型融合了「思考」和「非思考」能力 , 并具备根据问题难度自动切换思考形态的能力 。
他们的核心想法是在思考之前加上一个 pre-think 的阶段 , 让模型预先判断问题的困难度 。
简单来说 , KwaiCoder-AutoThink-preview 模型采用了两步式训练方法 , 首先通过 Agentic 方法构造长短思考的 Cold Start 数据让模型在进行思考之前先进行一个「pre-think」 , 判断一下问题的难度 。然后再使用加上专门为 Auto Think 任务设计的带有过程监督的 Step-SRPO 增强模型对各种任务难以程度判断的准确性 。
今年 7 月 , 快手更进一步 , 开源了 AutoThink 大模型 KAT-V1 , 也是主打无需人类手动设置 , 模型自主判断 。
具体细节可以参见技术报告 。
技术报告:https://arxiv.org/pdf/2507.08297
字节的豆包系列
字节今年 6 月发布的 Seed 1.6 (Adaptive CoT) 也是一个混合推理模型 , 支持 on/off/auto 三种思考模式 , 让用户可以根据使用场景自行选择 , 大模型也可以自己判断是否使用深度思考 。
据官方介绍 , 这种自适应思考能力的实现依靠一种动态思考技术来实现 , 即 Adaptive CoT , 能在保证效果的同时压缩 CoT 长度 。
Adaptive CoT 相关论文在 5 月份就已经上线(AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning) , 它将自适应推理建模为一个帕累托优化问题:在保证模型性能的同时 , 最小化 CoT 调用带来的成本(包括触发频次与计算开销) 。 具体来说 , 研究者采用基于强化学习的方法 , 使用近端策略优化(PPO) , 通过动态调整惩罚系数来控制 CoT 触发决策边界 , 使模型能够依据隐含的问题复杂度判断是否需要 CoT 。 关键技术贡献之一是「选择性损失掩蔽」(Selective Loss Masking , SLM) , 用以防止多阶段 RL 训练中的决策边界崩塌 , 确保触发机制稳健且稳定 。 当时 , 这项技术首先被部署到了 doubao-1.5-thinking-pro-m-250428 版本里 。
具体细节可参见论文:https://arxiv.org/pdf/2505.11896
不过 , 字节表示 , 他们最终还是希望将(Seed1.6-Thinking 所代表的)极致推理效果和(Seed 1.6 所代表的)动态思考技术融合到一个模型里 , 为用户提供更智能的模型 。
腾讯的混元系列
腾讯今年 6 月份发布的 Hunyuan-A13B 也是一个混合推理模型 。 为了让模型基于任务需求动态调整推理深度 , 他们实现了一个双模式思维链(Dual-Mode CoT)框架 , 让模型在快、慢思考之间切换 。
在技术报告中 , 他们提到了这个框架的一些细节 。 在后训练阶段 , 他们采用统一的训练结构来同时优化两种推理模式 。 为了使模型输出标准化 , 两种模式的训练样本均采用统一结构化设计:在专用的think内容块中 , 通过有无详细推理步骤进行区分 。 具体而言 , 快速思维模式刻意保持think\\think为空内容块 , 而慢速思维模式则在该区块明确包含逐步推理过程 。 用户可通过指定控制标签选择模式:使用「/no_think」启用快速思维模式 , 「/think」启用慢速思维模式 。 若未提供控制标签 , 系统默认采用慢速思维模式 。
技术报告:https://github.com/Tencent-Hunyuan/Hunyuan-A13B/blob/main/report/Hunyuan_A13B_Technical_Report.pdf
智谱的 GLM-4.5 系列
今年 7 月份 , 智谱发布了 GLM-4.5 和 GLM-4.5-Air , 都支持混合推理模式 。 该模式的形成主要与模型的后训练有关 。
具体来说 , 他们的后训练分为两个独立的阶段 。 在第一阶段(专家训练) , 他们构建了专注于三个领域的专家模型:推理、代理以及通用聊天 。 在第二阶段(统一训练) , 他们采用自蒸馏技术来整合多个专家 , 让模型学会了为每个任务应用最有效的长上下文推理来得出准确的答案 。 特别是 , 鉴于某些领域(如闲聊)不需要冗长的思考过程 , 他们精心平衡了包含完整推理过程的训练数据与缺乏明确思考过程的数据 。 这种方法使模型能够在反思和即时响应模式之间切换 , 从而创建了一个混合推理模型 。
更多细节可参见技术报告 。
技术报告:https://arxiv.org/pdf/2508.06471
OpenAI 的 GPT-5
有人说 , 如果 GPT-3 到 GPT-4 的重大突破是专家混合(Mixture of Experts) , 那么 GPT-4o/o3 到 GPT-5 的重大突破可能是模型混合(Mixture of Models , 也称为「路由」) 。
和很多将思考 / 非思考能力融合到同一个模型中的思路不同 , GPT-5 选择的方向是在整个系统中加入一个实时路由 , 它能根据对话类型、复杂程度、工具需求和明确意图(例如 , 如果你在提示中说「仔细思考这个问题」) , 快速决定使用哪个模型(如下表) 。
在 GPT-5 技术报告中 , 他们将快速、高通量的模型标记为 gpt-5-main 和 gpt-5-main-mini , 将思考型模型标记为 gpt-5-thinking 和 gpt-5-thinking-mini 。 API 中还提供更小更快的思考型模型 nano 版本 , ChatGPT 中还提供 gpt-5-thinking-pro 。 这些模型均由上一代模型(左边一栏)演变而来 。
该路由通过真实信号持续进行训练 , 包括用户何时切换模型、对回复的偏好以及测量的正确率等 , 随着时间推移不断改进 。 一旦达到使用限制 , 每个模型的迷你版本将处理剩余的查询 。
不过 , 这个模式同样反响不佳 。 不少人在社交媒体上吐槽自己的问题被路由到了低质量模型 。 更让人抓狂的是 , 很多时候你无法判断该不该相信模型给出的答案 , 因为路由结果是不透明的 。 这让 ChatGPT 在专业用户中的口碑有所下滑 。
不过 , 对于占 ChatGPT 用户数超 95% 的免费用户来说 , 这个路由反而提升了体验 。 之前 , 这部分用户是很难用上高级思考模型的 , 但是现在有一定概率会被路由到高级模型 。
对此 , SemiAnalysis CEO Dylan Patel 分析说 , 这可能是 OpenAI 在免费用户变现上迈出的重要一步 。 和专攻 to B 模式的 Anthropic 不同 , OpenAI 的商业重心依然集中在 C 端用户上 , 但这部分用户大部分是免费用户 。 对于这种情况 , 传统 APP 一般是通过让免费用户看广告来赚钱 , 但对于 AI 应用 , 这种模式不再适用 。
路由模型存在的价值在于 , 它可以从海量免费用户的提问中识别出商业意图 , 比如订机票、找律师 , 然后把这些高价值请求导向高算力模型 + 后续 Agent 服务 , OpenAI 再从成交中抽成 。 路由模式让 OpenAI 第一次把「成本」和「商业价值」写进模型决策逻辑 , 既省算力 , 又为下一步「AI 超级应用抽成」铺好了路 。
不过 , 路由未必是实现这些目标的终极方式 。 OpenAI 表示 , 他们之后也打算将两种思考模式的切换整合到单个模型里 。
DeepSeek 的 DeepSeek v3.1
DeepSeek 最近发布的 v3.1 是国内团队在「单一模型实现思考 / 非思考模式切换」上的另一项尝试 。 DeepSeek 官方表示 , DeepSeek-V3.1-Think 实现了与 DeepSeek-R1-0528 相当的答案质量 , 同时响应速度更快 。
对于开发者来说 , 它的思考模式和非思考模式可以由提示序列中的think和/think标记触发 。 对于 C 端用户 , 可以通过点击「深度思考」按钮切换模式 。
由于发布时间接近 , 又都有混合推理模式 , DeepSeek v3.1 和 GPT-5 难免被拿来对比 。 在性能上 , DeepSeek v3.1 虽然在一些基准上与 GPT-5 旗鼓相当 , 但综合能力仍然不如 GPT-5 。 在价格上 , DeepSeek v3.1 则有着明显的优势 , 可以说为企业提供了一个高性价比的开源选择 。
想深入了解混合推理?
这些研究方向值得关注
从以上模型可以看出 , 虽然大家的共同目标都是减少推理过程中的 token 浪费 , 但具体实现方法有所不同 , 有的借用路由将问题导向不同的模型 , 还有些在一个模型中实现快慢思考的切换 。 在切换方式上 , 有些是用户显式控制 , 有些是模型自动判断 。
通过一些综述研究 , 我们可以看到更多不同的思路 。
比如在「Towards Concise and Adaptive Thinking in Large Reasoning Models: A Survey」这篇综述中 , 研究者将现有方法分为两类:
一类是无需训练的方法 , 包括提示词引导、基于 pipeline 的方法(比如路由)、解码操纵和模型融合等;
提示词引导:通过精心设计的提示(例如 , 直接提示、token 预算、thinking 模式、no-thinking 指令)来利用模型遵循指令的能力 。 尽管该方法的简单性使其能够快速部署 , 但其有效性取决于模型对约束的遵守情况 , 而这往往并不一致 。 研究表明 , 这些方法会产生意想不到的后果 , 例如隐藏的不准确之处和输出稳定性的降低 , 特别是在实施严格的 token 限制或抑制推理步骤时 。 基于 pipeline 的方法:该方法将推理工作流程模块化 , 通过任务卸载降低大语言推理模型的计算成本 , 同时保持推理质量 。 其中 , 基于路由的方法根据输入复杂性、模型能力或预算限制动态选择最佳模型 / 推理模式 。 其他策略包括动态规划和迭代优化以及效率提升技术 。 这些方法显著缩短了推理长度 , 但引入了额外的开销(如路由延迟) , 导致端到端延迟增加 , 因此需要在效率和延迟之间进行权衡 。 解码操纵:通过预算强制、提前退出检查、logit 调整或激活引导等方式 , 动态介入生成过程 。 像 DEER 和 FlashThink 这类技术 , 通过监测置信度或语义收敛来实现更短的推理链 , 不过频繁的验证步骤可能会抵消计算节省 。 并行 scaling 策略进一步提高了效率 , 但需要仔细校准以平衡冗余度和准确性 。 模型融合:即将一个思考缓慢的大语言推理模型(LRM)和一个思考快速的大语言模型(LLM)整合为一个单一模型 , 并且期望这个单一模型能够平衡快慢思考 , 从而实现自适应思考 。 这种方法通过参数插值或基于激活的融合来综合长推理和短推理能力 。 虽然这种方法对中等规模的模型有效 , 但在处理极端规模(小型或大型模型)时存在困难 , 并且缺乏对推理深度的精细控制 。 与此同时 , 像 Activation-Guided Consensus Merging (ACM) 这样的最新进展凸显了互信息分析在对齐异构模型方面的潜力 。另一类是基于训练的方法 , 重点在于缩短推理长度 , 并通过微调(SFT/DPO)或强化学习(RL)来教导语言模型进行自适应思考 。
微调:微调可以分为五类:长思维链压缩方法提高了推理效率和适应性 , 但在压缩效果与推理保真度之间面临权衡 , 同时还存在数据需求增加和泛化方面的挑战;而短思维链选择微调则通过促进简洁或自我验证的推理路径来提高推理效率 , 但可能存在遗漏关键步骤的风险 , 或者需要复杂的训练过程 , 并在简洁性和准确性之间进行仔细权衡;隐式思维链微调通过潜在推理表示或知识蒸馏来实现效率提升 , 但由于推理步骤不明确而牺牲了解释性 , 且压缩表示与任务要求之间可能存在不一致的风险;近端策略优化(DPO)变体方法通过偏好学习实现简洁性和准确性之间的多目标优化平衡 , 但在构建高质量偏好对以及在严格长度限制下保持推理深度方面面临挑战;其他混合方法结合了快速 / 慢速认知系统或新颖的损失函数来实现自适应推理 , 不过它们通常需要复杂的训练流程 , 并对双模式交互进行仔细校准 。 强化学习:强化学习方法通过五个关键范式来平衡简洁性和准确性 。 带长度惩罚的强化学习通过奖励塑造或外部约束对冗长的输出进行惩罚 , 从而提高效率 , 但存在将复杂任务过度简化或过度拟合惩罚阈值的风险 。 GRPO 变体方法通过使推理模式多样化或整合难度感知奖励来解决「格式崩溃」问题 , 不过它们通常需要复杂的损失设计和多组件系统 。 难度感知强化学习通过显式难度估计或隐式信号(响应长度、解决率)使响应长度适应问题的复杂性 , 但在准确的难度校准和跨领域泛化方面面临挑战 。 思维模式强化学习能够在审慎(「思考」)和反应性(「不思考」)模式之间动态切换 , 但在模式选择稳定性和探索与利用的权衡方面存在困难 。 其他强化学习创新引入了可学习的奖励函数、混合框架或新颖的指标 , 尽管这些通常需要大量的计算资源或面临可扩展性问题 。具体分类如下图所示:
综述链接:https://arxiv.org/pdf/2507.09662
值得注意的是 , 除了语言模型 , 多模态模型领域的混合推理探索也已经开始 , 而且出现了 R-4B 等自动化程度较高的自适应思考模型 , 我们将在后续的报道中完整呈现 。
如果你想动态追踪这个领域的新研究 , 可以收藏以下 GitHub 项目:https://github.com/hemingkx/Awesome-Efficient-Reasoning#adaptive-thinking
下一个前沿:
让 AI 以最低代价在恰当时刻思考
在过去几年 , AI 领域的竞争更多集中在构建更强大的模型上 。 如今 , 混合推理模式的大规模出现标志着人工智能行业的重点从单纯构建更强大的系统转向创建实用的系统 。 正如 IBM 研究院高级项目经理 Abraham Daniels 所说 , 对于企业而言 , 这种转变至关重要 , 因为运营复杂人工智能的成本已成为主要考虑因素 。
但是 , 这一转变也在经历阵痛 。 一方面 , 能够不靠人类指示激活深度思考模式的成功模型还相对较少 。 另一方面 , 尝试去掉显式开关的思维转换模式还没有实现足够令人满意的效果 。 这些现象都说明 , 混合推理的下一个前沿将是更智能的自我调节 。
【DeepSeek、GPT-5带头转向混合推理,一个token也不能浪费】换句话说 , 混合推理的未来竞争将不再只是「是否能思考」 , 而是「能否以最低代价在恰当时刻思考」 。 谁能在这一点上找到最优解 , 谁就能在下一轮 AI 性能与成本博弈中占据主动 。
推荐阅读
















- 1.4nm芯片,4.5万美元一片,苹果、英伟达都用不起?别扯淡了
- 手机周报份额再次出炉:vivo持续领先,9、10月或迎巨变!
- 美国通告全球,取消三星、SK海力士对华出售许可,人民日报的提醒该重视了
- 子系列新机前瞻!真我、红米冲高,一加史诗级倒退?
- iPhone 17全系配置、价格曝光,四款全线出击,5999元起,你怎么选
- Agent实效竞赛正式打响!百度智能云在服务营销、工业赛道先各下一城
- 小米16系列再次被确认:大电池、新工艺、强性能,亮点基本清晰了
- 说实话,小米接下来的重点是汽车、家电,而不是手机!
- 荣耀多款新机曝光:500系列已备案、GT2系列在路上
- 中国最强PC系统诞生:兼容数超730万,支持国产CPU、GPU