
文章图片

文章图片
文章图片
文章图片
文章图片

近日 ,蚂蚁集团知识引擎团队协同浙江大学、同济大学正式发布了其在结构化推理领域的最新成果 —— KAG-Thinker 模型 , 该模型是 KAG 框架的重要迭代升级 , 聚焦于为通用或专业领域复杂推理任务构建稳定、可解释的思考范式 。
2025 年以来 , OpenAI 推出的 Deep Research 展示了大模型在复杂推理任务中多轮检索、规划推理的强大能力 。 随后 , 产学界涌现了较多以模型为中心 (Model-Centric) 的方法 , 比如 Search-R1、ReSearch 等 。 它们的核心思路是 , 通过强化学习让模型自己 “学会” 如何检索和利用外部知识 , 从而让小模型也能像专家一样 “思考” 。 然而 , 这些基于自然语言的推理方法就像让模型 “自由发挥” , 推理不严谨、过程不稳定等问题依然突出 。 而人类专家解决复杂问题时 , 往往采用结构化的思考方法 , 把原始问题拆解成多个可独立验证的小问题 , 并依次求解 。受此启发 , 研究团队提出了 KAG-Thinker , 为模型的思考过程建立一套清晰、分层的 “脚手架” , 从而提升复杂任务中推理过程的逻辑性与稳定性 。
- 技术报告:https://arxiv.org/abs/2506.17728
- Github:https://github.com/OpenSPG/KAG-Thinker
- Huggingface: https://huggingface.co/OpenSPG/KAG-Thinker-en-7b-instruct
【KAG-Thinker:结构化思考新范式,支持逻辑严谨的大模型复杂推理】该模型延续了 KAG 框架 Logical Form 自然语言与逻辑函数双语义表示机制 , 以更好地利用结构化知识;并通过广度拆分与深度求解相结合的方式 , 提升问题求解的严谨性;同时引入以知识点对齐为中心的知识边界判定机制 , 以充分利用大模型参数化知识与外部形式化知识 , 并借助内容抗噪模块降低检索信息噪声 , 增强检索内容的可信度 。
视频 1 KAG-Thinker 与 KAG 框架集成 , 「结构化思考」引导的 「深度推理」 问答产品示例
最终 , 研究团队将上述策略集成于一个支持多轮迭代与深度推理的统一架构中 , 通过监督微调方法训练出 KAG-Thinker 7B 通用模型 。
实验结果显示 , 在 7 个单跳和多跳推理数据集上 , 其性能相较使用强化学习 Search-R1、ZeroSearch、ReSearch 等 SOTA 深度搜索方法平均提升了 4.1% 。 与 KAG 框架集成后在多跳推理任务上超越 HippoRAG V2、PIKE-RAG 等 In-Context Learning(以 Qwen2.5-72B 为基模)方法 。 此外 , 模型也在医疗问答任务中验证了其在专业领域中的有效性 。 其他专业领域的精细化定制 , 可以参考其在医疗问答上的应用及表现 。
图 1 KAG-Thinker 语料合成和模型训练过程概览
模型方法
模型的架构如下图所示 。 模型的核心内容包括:
图 2 复杂问题求解概览图
广度拆分 + 深度求解:应对复杂决策任务
复杂多跳问题通常需拆分为多个简单子问题 , 以更高效地利用外部知识库进行求解 , KAG-Thinker 提出了一种 「广度拆分 + 深度求解」 的方法(详见图 2):
广度拆分 :将原始问题分解为若干原子问题 , 各子问题间保持逻辑依赖关系 , 确保拆分的准确性 。 每个原子问题由一个 Logical Form 算子表示 。 每个 Logical Form 具备双重表示形式 —— 自然语言描述(Step)与逻辑表达式(Action) , 二者语义一致 。
深度求解 :针对需要检索 (Retrieval) 的子问题 , 进行深入求解 , 以获取充足的外部知识保障答案准确 。 在检索前 , 模型会先执行知识边界判定:若判断当前大模型自身知识已足够回答该子问题 , 则跳过检索;否则继续深度求解 。
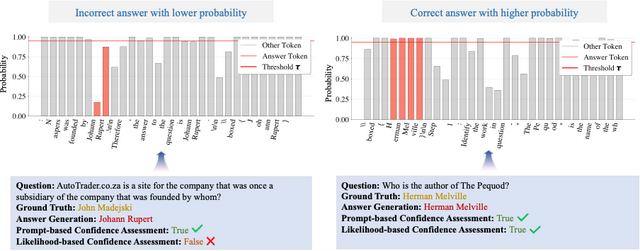
知识边界判定:充分利用 LLM 参数化知识
为充分利用大模型的参数化知识、减少不必要的检索任务 , KAG-Thinker 以知识点(如实体、事件)为中心定义 Retrieval 子任务 , 并通过 SPO 三元组限定检索粒度 , 以此为基础判断大模型与外部知识库的边界 。
知识边界判定任务是一个无监督过程:首先让大模型直接作答子问题 , 再由其判断该答案是否为真实答案 。 此过程生成两个标签:
- 自然语言输出的判断结果(True/False);
- 答案首次出现时对应 token 的概率 , 若低于设定阈值则标记为 False , 否则为 True 。
仅当两个标签均为 True 时 , 才认为大模型自身知识足以回答该子问题 , 无需额外检索 , 可直接采用其生成的答案 。
图 3 知识边界判定
检索内容抗噪:提升检索内容的可信度
对于必须检索的子问题 , Thinker 需要判断当前检索结果是否能求解出对应子问题 。 然而 , 不同检索器检索的内容参差不齐 , 尤其是网页检索得到的内容 。
为了更好的分析检索结果 , 检索抗噪模块会分析每篇检索回来的文章与当前子问题的关系 , 去掉一些无关内容 , 再从剩余内容从中提取一些核心信息 , 作为直接给出子问题的答案还是继续进行深度检索的依据 。
Logical Form 求解器
在广度拆分和深度求解时 , Thinker 沿用 KAG 框架中定义的 4 种 Logical Form 求解器 。 每种 Logical Form 算子的定义如图 4 所示 。 Retrieval 主要解决检索类的问题 , Deduce 和 Math 主要解决推理分析类问题 , Output 主要用于答案汇总 。
图 4 4 种 Logical Form 算子的定义
实验结果
单跳和多跳问答
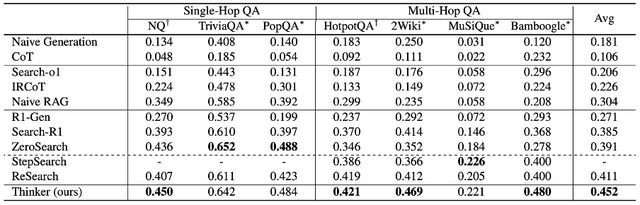
为了评估模型的效果 , 研究团队选了 7 个通用的单跳和多跳推理数据集 , 并使用相同的检索器 (E5-base-v2) , Baseline 选择了最新的 ReSearch、Search-R1、ZeroSearch 和 StepSearch 等 。 并沿用这些 Baseline 方法的评价指标 (EM) 。 为了使用相同的检索器 , 只使用 Logical Form 表示中的 Step 中的纯自然语言的内容 。 整体实验效果如表 1 所示 。
与无检索基线相比 , Thinker 模型的平均性能比 Naive Generation 和 CoT 分别高出 27.1% 和 34.6% 。
与检索增强方法相比 , Thinker 模型的平均性能比 Search-o1、IRCoT 和 Naive RAG 分别高出 24.6%、22.6% 和 14.8% 。
与基于强化学习的方法相比 , Thinker 模型比 SOTA 模型 ReSearch 高出 4.1% 。
具体而言 , 在单跳数据集中平均提升了 4.5% , 在多跳数据集中平均提升了 3.9% 。 主要原因是 , 知识点粒度的检索任务拆解降低了检索的复杂性 。
表 1 不同模型 (基座模型 Qwen2.5-7B-Instruct) 在不同数据集上的 EM 性能
KAG 框架升级
KAG V0.8 升级了知识库的能力 。 扩展了私域知识库(含结构化、非结构化数据)、公网知识库 两种模式 , 支持通过 MCP 协议引入 LBS、WebSearch 等公网数据源 。 此外 , 升级了私域知识库索引管理的能力 , 内置 Outline、Summary、KnowledgeUnit、AtomicQuery、Chunk、Table 等多种基础索引类型 , 支持开发者自定义索引 & 产品端联动 的能力 (如视频 2 所示) 。
用户可根据场景特点选择合适的索引类型 , 在构建成本 & 业务效果之间取得平衡 。 在本次 0.8 的发版中 , KAG 全面拥抱 MCP , 提供接入公网 MCP 服务及在 agent 流程中集成 KAG 推理问答(基于 MCP 协议)的能力 。
视频 2 可配置化的知识索引构建能力
KAG 框架的应用
KAG 框架 V0.8 版本为 Thinker 模型应用提供支持 , 融入 KAG 框架后的 Thinker 模型 ,Math、Deduce 都使用框架中的求解器进行求解 , 再用 Thinker 模型进行答案汇总 , 可以看到 KAG-Thinker 7B 的平均 EM 和 F1 性能相比于 Thinker 模型平均提升 3.0% , 3.8% 。 这也说明 KAG 框架能更好的帮助 Thinker 模型进行求解 。
表 2 不同模型在自建检索库上的性能
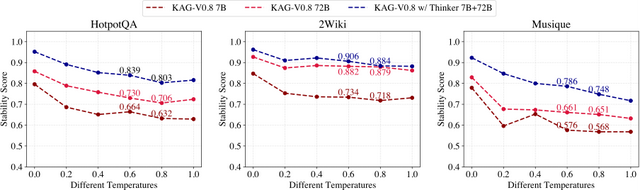
同时 , 针对 KAG 框架问题拆解不稳定的现象 , 也做了问题广度拆解的稳定性测试 , 将同一个问题 , 拆解两次 , 如果两次结果相同 , 则分数为 1 , 否则为 0 。
实验结果如图 5 所示 , KAG-Thinker 7B 在 HotpotQA、2Wiki 和 Musique 这三个数据集上的稳定性表现优于 KAG-V0.8 7B 和 KAG-V0.8 72B 。 在常用的温度参数 0.6 和 0.8 下 , KAG with Thinker 7B+72B 分别相对于 KAG-V0.8 7B 和 KAG-V0.8 72B 平均提升了 17.9% 和 7.6% 。
图 5 不同温度参数下不同模型稳定性测试
KAG-V0.8 with Thinker 在三个数据集上的平均性能要优于 HippoRAGV2 和 PIKE-RAG , 详细的实验设置参考 KAG-V0.8 release notes 。
虽然 KAG-V0.8 with Thinker 大幅度提升了框架的稳定性 , 但是平均性能要低于 KAG-V0.8 72B , 略高于 KAG-V0.8 32B 。 这说明 7B 的 Thinker 模型的问题拆解能力还有所欠缺 , 分析 BadCase 发现 , 对于一些复杂的问题 , Thinker 模型的拆分能力还不够 , 例如 「Who is the paternal grandmother of John Iii Duke Of Cleves?」 , 需要分解出 John Iii Duke Of Cleves 的妈妈是谁和 John Iii Duke Of Cleves 的妈妈的妈妈是谁 。
这种问题 Thinker 模型拆分不稳定 , 主要的原因有两种 , 第一 , LLM 对复杂的纯自然语言问题拆分存在不一致 , 第二 , 7B 模型的泛化能力有限 。 为了解决这些问题 , 研究团队表示将来会从结构化数据中合成问题拆分样本 , 保证模型拆分的一致性 。
表 3 不同框架在多跳推理上的性能表现
医疗领域的应用
为了验证该框架在专业领域的能力 , 研究团队在医疗领域做了一系列的改造 , 训练出了 KAG-Med-Thinker 。 实验结果如表 4 所示 , 在 DeepSeek-R1-Distill-Qwen-14B 上 , 与已有的多轮规划和检索增强模型 IRCoT 和 ReAct 相比 , KAG-Med-Thinker 分别取得了 3.95% 和 4.41% 的显著性能提升 。 同时 , 它还比 Naive RAG 自适应检索模型高出 3.8% 。
表 4、不同模型在 MedQA 上的准确性
推荐阅读










- AI 与产品工作的思考:重构、挑战与共生之路
- AI 技术热潮冲击,谷歌搜索地位动摇引发的行业变革与思考
- AI需要「像人类」那样思考?AlphaOne揭示大模型的「思考之道」
- 安卓皮,苹果骨?OPPO新机全新设计引发深层思考
- 中国团队让AI拥有「视觉想象力」,像人类一样脑补画面来思考
- 火山引擎密集上新:豆包全新视频生成模型、视觉深度思考模型,Trae多个重点功能升级
- 从“一码难求”到被多方质疑 Manus过山车式走红的冷思考
- 重新思考 6G
- 浙江大学教授陈德人:企业家要尽早思考成为“超级个体”
- 大定3万!R7持续增涨,华为不给油车思考时间,奇瑞忙到笑出声!