
文章图片

文章图片

文章图片
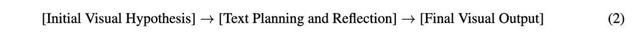
文章图片
文章图片
文章图片
在人类的认知过程中 , 视觉思维(Visual Thinking)扮演着不可替代的核心角色 , 这一现象贯穿于各个专业领域和日常生活的方方面面 。
图 1:需要借助「脑补」图像进行思考的真实世界任务 。 这些任务通常需要视觉预见性和想象力 , 仅凭基于文本的思考无法完全实现 。
生物化学家在探索新的治疗途径时 , 会在脑海中构建蛋白质的三维立体结构 , 通过视觉化的分子间相互作用来理解复杂的生化过程;法医分析师在破解疑难案件时 , 需要在心中重建犯罪现场的空间布局 , 通过视觉推理来验证证据之间的逻辑连接;建筑师在设计创新建筑时 , 会在脑海中不断勾勒和修正建筑草图 , 通过视觉想象来优化空间配置和光照效果;篮球运动员在制定战术策略时 , 需要在脑海中构想队友的跑位路线、防守阵型的变化以及关键时刻的战术配合 , 通过视觉化的场景想象来设计最佳的进攻方案;在日常决策中 , 一般人也会通过「脑补」各种可能的场景图像来辅助判断和选择 , 用脑海中自发生成的图像作为认知媒介 。
这种视觉思维能力的独特之处在于 , 它能够创造概念间的独特组合和新颖连接 , 帮助我们发现仅通过纯文本推理无法获得的洞察和创意 。 而在现代认知科学中 , 这种「深思熟虑」往往需要多模态的思维过程来支撑 。
如今 , AI 也迈出了这一步:上海交通大学、上海创智学院、复旦大学和 Generative AI Research Lab(GAIR)的团队提出 Thinking with Generated Images , 让大模型能够自发生成视觉中间步骤 , 像人类一样用「脑内图像」进行跨模态推理 。
- 论文链接:https://arxiv.org/abs/2505.22525
- 代码链接:https://github.com/GAIR-NLP/thinking-with-generated-images
- 模型链接 1:https://huggingface.co/GAIR/twgi-critique-anole-7b
- 模型链接 2:https://huggingface.co/GAIR/twgi-subgoal-anole-7b
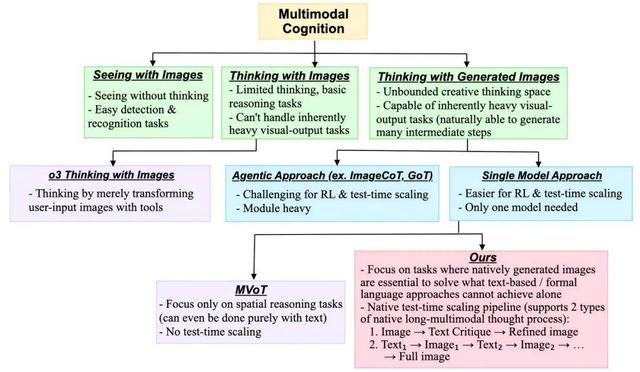
从「看图像」到「脑补图像」— 视觉思维的递进进化
如何让模型自发性地通过视觉进行「思考」仍属于早期探索阶段 。 此前的一些工作尝试通过空间搜索任务(如迷宫导航)进行早期探索 , 但这些任务的局限性在于它们往往可以直接通过文本思考或「对着」图像思考(Thinking with Images)来解决 , 而不需要真正的「脑补」图像思考(Thinking with Generated Images) 。
Thinking with Generated Images 系统性地整理并比较了三个核心概念的本质区别及其适用任务的差异:
- 「看」图像(Seeing with Images):模型仅在单次前向传播中处理用户提供的固定图像 , 主要适用于基础的视觉识别任务 , 如物体检测、图像分类等 。 这种模式下 , 模型只是被动地「观察」图像内容 。 在这个过程中 , 整个 AI 的思维过程完全发生在文本模态中 , 图像仅仅作为一个固定的先验条件 , 无法参与到动态的推理过程中 。 这也是大多数现有的大型多模态模型(Large Multimodal Models LMMs)或视觉语言模型(Vision-Language Models VLMs)的预设模式 。
- 「对着」图像思考(Thinking with Images):模型能够多次访问或对现有图像进行有限变换(如裁剪、旋转、代码执行器、OCR、图像处理工具) , 适用于需要多步视觉推理的任务 , 如视觉问答、图表解读、空间推理等 。 「对着」图像思考虽然在一定程度上改善了模型的视觉推理能力 , 但仍然受到一个核心约束:它们只能处理用户预先提供的固定图像或对这些图像进行简单变换 , 被动处理用户提供的图像 , 无法真正做到从零开始构建新的视觉概念 。
- 「脑补」图像思考(Thinking with Generated Images):模型能够主动生成中间视觉步骤作为推理过程的一部分 , 适用于需要视觉想象、创造性设计、空间规划、以及与物理世界环境交互感知的复杂任务 。 这种模式在需要视觉预见性(visual foresight)和创造性想象的任务上具有最大优势 , 因为纯文本推理无法充分表达这些任务所需的空间和视觉信息 。
图 2:区分「看」图像、「对着」图像思考、「脑补」图像思考的例子 。
技术实现方案:
自发原生多模态长思维链
研究团队创新性地提出了「原生多模态长思维过程」(the native long-multimodal thought process)这一核心技术框架实现「脑补」图像思考 。 原生多模态长思维过程由交错的多模态 token 组成:包括文本的词汇或子词(words/subwords)、视觉的图像块(patches)等 。
未来有更通用的基座模型后也能推广到音频的?。 ╢rames) , 以及其他模态领域特定的表示形式(domain-specific representations) 。 原生多模态长思维过程不仅能够让模型在思维过程中自然地自发生成图像 , 还能够原生地执行测试时扩展(test-time scaling)以获得更好的模型能力 。 透过原生多模态长思维过程实现 Thinking with Generated Images 有四大主要优势:
- 跨模态原生思维能力:通过单次推理过程即可「原生」地生成多模态的 tokens , 使模型能够自然无缝地跨模态进行「思考」 。
- 统一生成式任务执行:通过生成式范式原生地执行多样化的多模态任务 。
- 自然测试时扩展机制:通过生成的「长」思维过程提供自然跨模态的测试时扩展 , 使模型能够通过生成更长、更详细的多模态长思维过程 , 在推理时投入更多计算来提升性能质量 。
- 未来技术集成兼容性和可扩展性:单一模型集成的架构便于未来与强化学习等训练后扩展技术的集成 , 简化了训练和推理持续扩展的复杂度 。
研究团队深入分析人类多模态长思维的认知模式 , 据此设计并提出了两种原生多模态长思维链模式 , 应用于视觉生成任务上 , 最大的体现 Thinking with Generated Images 的优势:
- 视觉子目标分解(Vision Generation with Intermediate Visual Subgoals):视觉子目标分解模拟了人类在处理复杂视觉任务时的分而治之策略 。 面对较为复杂或多物体的视觉生成任务(如「一张沙发和一个酒杯」) , 模型首先进行整体性的分析 , 将大的视觉任务拆解成小的目标 , 分步生成沙发和酒杯的独立图像 , 再组合成最终结果 。 每个中间图像都承载了特定的子目标语义 , 不仅是视觉内容的载体 , 更是推理过程中的「思维节点」 。 视觉子目标分解允许模型在处理复杂视觉生成任务时保持对细节的精确控制 , 避免了直接生成复杂图像时可能出现的元素遗漏、比例失调或风格不一致等问题 。
图 3:原生多模态长思维链在GenEval上的例子 。
- 提出视觉假设并自我反思迭代(Vision Generation with Self-Critique):提出视觉假设并自我反思迭代体现了人类创作过程中的「草稿-修改-完善」循环机制 。 模型首先基于输入提示生成一个初始的视觉假设图像 , 这个假设通常包含了对任务的基本理解但可能存在各种不完善之处 。 模型随后以文本反思形式对自己生成的图像进行深入的多角度分析 , 包括内容完整性检查(如「图像缺乏雨伞」)、视觉质量评估(如「更清晰的海景化」)、语义一致性验证(如「更清楚的展示冰淇淋的融化」)、构图合理性判断(如「增强图像对比度」)等等 。 模型通过建立视觉假设、批判性分析、策略性改进的迭代过程来逐步优化生成结果 , 实现了视觉和文本模态之间的深度协同 , 形成了一个有效的自我改进反馈循环 , 显著提升了生成图像的质量和准确性 。
图 4:原生多模态长思维链在DPG-Bench上的例子 。
自发原生多模态长思维链在多模态统一理解生成模型的实现
研究团队选择在自回归 next-token-prediction 的多模态统一理解生成模型上开发原生多模态长思维链 , 这一决策基于几个层次的技术考虑:
- 自回归架构与人类思维过程的天然契合性 。 人类的思维过程本质上是序列化的——我们在思考复杂问题时 , 会逐步构建想法 , 从一个概念过渡到另一个概念 , 在文本思考和视觉想象之间自然切换 。 自回归模型通过逐 token 生成的方式 , 能够最自然地模拟这种渐进式、序列化的思维展开过程 。
- 统一架构的简洁性和可扩展性优势 。 相比于需要协调多个独立组件的复杂系统架构 , 自回归统一模型提供了一个优雅的解决方案 。 在这种架构下 , 文本推理、视觉生成、自我批判等所有能力都统一在同一个模型中 , 避免了多组件系统中常见的信息传递损失、同步协调复杂性等问题 。
- 与现有技术生态的深度兼容性 。 当前大语言模型领域已经在自回归架构上积累了丰富的训练技巧、优化方法和推理技术 。 选择这一架构使得研究团队能够直接继承和利用这些成熟的技术成果 , 而不需要从零开始构建全新的技术栈 。
- 未来发展的技术路径一致性 。 随着计算能力的不断提升和算法的持续优化 , 自回归架构展现出了强大的扩展潜力 。 选择这一技术路径确保了研究成果能够与未来的技术发展趋势保持一致 , 具备长期的技术价值 。
- 原生交错生成能力:Anole 直接在交错的文本-图像 token 上进行预训练和后训练 , 具备了交错生成多模态 token 的固有能力 , 这是实现本研究目标的基础前提 。
- 高效的视觉表示机制:Anole 采用相对高效的图像表示方案 , 使得基于原生多模态长思维过程的测试时扩展在合理的推理预算内成为可能 。
研究团队提出的「原生多模态长思维过程 (the native long-multimodal thought process)」这一核心技术框架实现「脑补」图像思考 。 与现有方案对比 , 该提出方案解决了五大局限:
- 摆脱用户输入依赖:过去的方法(如 OpenAI 的 o3 thinking with images)需用户提供图像作为推理起点 , 而原生多模态长思维过程能从零构建视觉上下文 , 让模型在无图场景下也能自发地做多模态思考 。
- 超越静态图像处理:目前的工具增强型模型通常只能裁剪、标注或轻度编辑给定图像;原生多模态长思维过程在推理链中动态生成全新的视觉假设 , 为创造性规划与空间推演打开更大搜索空间 。
- 端到端统一架构:无需多模型协作或外部工具链 , 单一模型即可完成「生成-推理-反思-迭代」的全流程 , 部署与调用更加轻量 。
- 可扩展的测试时扩展和未来后训练扩展:原生多模态长思维过程天然支持测试时扩展(test-time scaling) , 通过生成更长、更详细的多模态长思维序列来提升性能 。 此外 , 该架构为未来与强化学习、自我改进等后训练技术的集成预留了充分空间 。
- 实际落地的应用场景:过去的相关研究往往专注于相对局限任务场景 , 如数学(几何)题求解、迷宫导航、简单的空间推理等 。 这些任务虽然在技术验证上有一定价值 , 但存在一个根本性问题:它们大多可以通过纯文本描述和逻辑推理来充分表达和解决 。 例如 , 迷宫问题可以用坐标和路径描述完全编码 , 几何题可以通过形式化语言和逻辑步骤来求解 , 这些任务并未真正发挥视觉思维的独特优势 。 研究团队专注于解决那些无法通过纯文本充分表达的复杂视觉推理任务 , 实现了从「专注于能用文本充分解决的视觉任务」到「专注于必须依赖视觉想象的复杂创造性任务」的认知跃升 。
未来 , 当这些能力并行叠加时 , 既能利用 Thinking with Generated Images 提出的「脑内草图」 , 也能借助现有检索增强、外部工具调用等技术 , 形成 1+1>2 的整体效果 。
图 5:多模态认知领域相关工作的对比
实验设计
为了在多模态理解生成模型上实现 Thinking with Generated Images 的自发原生多模态长思维链 , 研究团队在训练数据、训练策略、以及推理策略上都有深入的探索 。
训练数据
研究团队精心设计了一套合成数据构建流程 , 专门用于训练模型生成两种类型的多模态长思维链 。 由于目前没有现成的 LMM 模型支持多模态生成的测试时扩展 (test-time scaling) , 传统蒸馏技术并不适用 , 团队创新性地开发了完整的数据构建管线(如图 6 所示) 。
数据收集三大黄金法则:
- 高质量图像生成提示词:采用 Deepseek-V3、GPT-4o、Claude3.7-Sonnet 和 Qwen2.5-72B-Instruct 顶尖模型生成复杂提示词 , 通过规则过滤确保质量 , 并借助 Qwen3-32B 将复杂视觉任务拆解成小的目标 。
- 高质量反思推理链:借助 QVQ-72B-Preview 的强大长链推理能力 , 对每个提示-图像对进行准确性评估、差异识别和改进建议 , 并实现模型通过迭代分解获得最终图像的过程 。
- 高质量中间视觉思维:
- 初始生成:
- 使用 Anole-7b(自我批判)或 Flux1-dev(子目标分解) 。
- 精修阶段:
- Flux1-Redux 结合原始提示、首轮图像和批判反馈进行优化 。
- 最终生成:
- 基于前几轮图像及思考过程来生成最终结果 。
技术亮点解析:
- 突破性数据架构:专门为「视觉思维」范式优化的统一数据结构 。
- 多模型协同:充分发挥各领域顶尖模型的专长 , 构建训练样本 。
- 严格质量把控:从提示词到最终图像的全流程质量控制机制 。
图 6:数据收集流水线示例
训练策略
在使用统一多模态模型进行视觉生成任务的训练时 , 大多仅依赖交叉熵训练没有完整的考虑图像 token 之间的关系 。
为了解决这个问题 , 研究团队引入了视觉特征级别的重建损失 , 将生成图像的隐状态投影回视觉特征空间 , 并计算与 ground-truth 图像对应特征之间的均方误差 (MSE) 损失 。 这种设计鼓励模型产生具有更强视觉连贯性和结构完整性的输出 。 基于优化后损失函数 , 研究团队设计了系统性的两阶段训练流程:
- 基础能力强化:使用 JourneyDB 图文对数据集对 Anole-7b 进行持续训练 , 增强模型的基础视觉生成能力 。 这一阶段为后续的专门化训练奠定了坚实的多模态基础 。
- 专门化微调:基于上述的合成数据集进行模型训练 , 精细化调整两个专门化模型:
- TwGI-Anole-7b-Obj.:使用视觉子目标分解数据集进行微调 , 使其具备生成视觉中间子目标的能力 。
- TwGI-Anole-7b-Crit.:使用视觉自我批判数据集进行微调 , 使其具备自我批判视觉假设的能力 。
推理策略
与标准的视觉语言模型或大语言模型不同 , 统一多模态模型在进行视觉生成任务时面临着独特的推理挑战 。 为了充分发挥模型的性能潜力 , 无分类器引导 (Classifier-Free Guidance CFG) 技术成为提升视觉生成性能的关键 。 在传统的完整条件 (full conditions)、无条件 (unconditions) 和图像条件 (image conditions) 基础上 , 研究团队增加了:
- 「原始提示条件」(Original Prompt Conditions):确保生成过程始终与用户的原始意图保持一致 。
- 「负面条件」(Negative Conditions):避免生成不当或无关的视觉内容 。
- 充分利用长文本思维的指导作用:从详细的文本推理中获得有价值的语义信息和逻辑指导 。
- 有效过滤思维过程中的潜在噪声:避免被长思维序列中可能存在的无关信息或错误推理分散注意力 。
- 保持视觉生成的一致性和质量:确保最终输出既符合原始提示要求 , 又体现了深度推理的成果 。
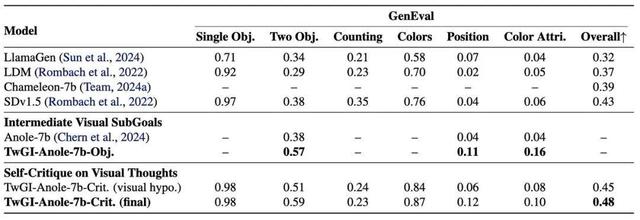
研究团队在 GenEval 和 DPGBench 两个图像生成基准上对 TwGI-Anole-7b-Obj. 和 TwGI-Anole-7b-Crit. 进行了全面的性能评估 。
- 视觉子目标分解模式的评估:视觉子目标分解模拟了人类在处理复杂视觉任务时的分而治之策略 。 面对较为复杂或多物体的视觉生成任务(如「一张沙发和一个酒杯」) , 模型首先进行整体性的分析 , 将大的视觉任务拆解成小的目标 , 分步生成沙发和酒杯的独立图像 , 再组合成最终结果 。 每个中间图像都承载了特定的子目标语义 , 不仅是视觉内容的载体 , 更是推理过程中的「思维节点」 。 视觉子目标分解允许模型在处理复杂视觉生成任务时保持对细节的精确控制 , 避免了直接生成复杂图像时可能出现的元素遗漏、比例失调或风格不一致等问题 。
- 视觉自我批判模式的评估:测试 TwGI-Anole-7b-Crit. 模型是否能够纠正其初始视觉假设(图 7 和图 8 中的 TwGI-Anole-7b-Crit. (visual hypo.)) , 并生成更好的图像生成结果(图 7 和图 8 中的 TwGI-Anole-7b-Crit. (final)) 。
图7: 在GenEval上的表现
图8: 在DPG-Bench上的表现
中间视觉思维生成对视觉生成任务的显著效益
实验结果表明 , TwGI-Anole-7b-Obj 在 GenEval 和 DPGBench 两个基准上都始终优于基线模型 Anole-7b 。 在 GenEval 上 , TwGI-Anole-7b-Obj 在「双对象」类别中取得了显著提升(0.57 vs. 0.38 , 相对提升 50%) , 表明其在处理涉及多个实体的复杂提示时具备了更强的能力 。 在位置和颜色属性对齐方面也显示出显著改进 , 体现了在精确空间和视觉构图推理方面的更强能力 。
在 DPGBench 上 , TwGI-Anole-7b-Obj 在「实体」、「属性」和「关系」类别中都取得了实质性进步 , 总体分数从 58.32 提升至 68.44(相对提升 17.3%) , 反映出其在细粒度视觉语义理解方面的增强能力 。 这些改进验证了我们的假设:将视觉任务分解为中间子目标使得大语言模型能够更系统地推理并生成更高质量的输出 。
原生多模态长思维过程使模型能够纠正和完善自身的视觉假设
视觉思维自我批判的实验结果证明了让模型反思和修正自身视觉输出的有效性 。 TwGI-Anole-7b-Crit. 模型在自我批判步骤后性能显著提升:GenEval 总分从 0.45 提升至 0.48 , DPGBench 分数从 62.83 提升至 67.14 。 这表明模型具备了内省分析生成图像的能力——通过基于视觉反馈的文本推理链 , 能够识别不匹配、幻觉或遗漏的元素 , 并随后进行纠正 。 这种视觉反馈循环的有效性反映了一种模态间协同效应 , 其中视觉和文本模态相互迭代指导 , 形成了真正的多模态智能推理机制 。
这些结果共同验证:在推理链中主动「画草图」或「打草稿」 , 不仅让模型生成质量更高、更可控 , 也带来了深度理解与纠错能力 。
未来展望
Thinking with Generated Images 的能力未来有望推动 AI 在需要空间想象和动态规划的领域实现突破:
- 创造性设计:模型可逐步生成并迭代建筑草图 , 同时用文本记录调整理由(如「将窗户东移以优化采光」) 。
- 科学发现:通过生成分子结构的中间假设图像 , 辅助生物学家验证药物结合路径 。
- 战术规划:让 AI 篮球员「脑补」生成不同战术配合的场上演示图像 , 可视化球员跑位路线和防守破解策略 。
- 它不只是性能指标的上涨 , 而是推理范式的突破;
- 它不只是会画画 , 而是把「画画」变成了思考的肌肉记忆;
- 它不只是一次概念验证 , 更是给未来「多模态 AGI」铺了条高速公路 。
推荐阅读














- 2025亚马逊云科技中国峰会6月19日上海开幕,聚焦生成式AI全球实践
- 玄戒VS麒麟:中国芯片突围的“双轨战略”价值
- 电池健康焦虑:厂商制造的消费陷阱,别让一个数字绑架你的钱包!
- 5G发牌六载:5G-A商用开启中国数字经济“价值挖掘”深水区
- 华为、新紫光等加持,中国集成电路学院+1
- 中国大陆出货量排名前10机型:苹果3款,小米2款,华为1款
- iPhone密码错太多被锁?这6招让你立刻解锁,不用跑维修!
- 最新5G用户数据拆解,中国广电离“半个小目标”还有多远?
- 华为,为什么让我们如此自豪?
- 跟三星们硬拼?中国内存芯片厂商,也要停产DDR4,转向DDR5、HBM