
文章图片
文章图片

文章图片

文章图片
快分叉与稳收敛
在扩散 / 流匹配模型的人类偏好对齐中 , 实现高效采样与稳定优化的统一 , 一直是一个重大挑战 。
近期 , 北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法 。 不同于顺序展开的 DanceGRPO , BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning) , 让多个轨迹共享前缀、在中间步骤分裂 , 并通过逐层奖励融合实现稠密反馈 。
该方法在 HPDv2.1 图像对齐与 WanX-1.3B 视频生成上均取得了优异表现 。 最令人瞩目的是 , BranchGRPO 在保证对齐效果更优的同时 , 迭代时间最高近 5×(Mix 变体 148s vs 698s) 。
论文链接: https://arxiv.org/pdf/2509.06040 项目主页: https://fredreic1849.github.io/BranchGRPO-Webpage/ 代码链接: https://github.com/Fredreic1849/BranchGRPO PKU HMI 实验室主页:https://pku-hmi-lab.github.io/HMI-Web/index.html 单位:该项目主要由来自北京大学、北京师范大学、字节跳动的师生联合研究 , 作者包括李聿明、王一凯等 , 通讯作者为北京大学仉尚航 。
研究背景与挑战
近年来 , 扩散模型与流匹配模型凭借在图像与视频生成上的高保真、多样性与可控性 , 已成为视觉生成的主流方案 。 然而 , 仅靠大规模预训练并不能保证与人类意图完全对齐:模型生成的结果常常偏离美学、语义或时间一致性的需求 。
为解决这一问题 , 「人类反馈强化学习(RLHF)」被引入 , 用以直接优化生成模型 , 使其输出更贴近人类偏好 。
在 RLHF 体系中 , 「群体相对策略优化(GRPO)」被证明在图生文、文生图和视频生成中具有良好的稳定性与可扩展性 。 然而 , 当 GRPO 应用于扩散 / 流模型时 , 依旧面临两大根本性瓶颈:
低效性:标准 GRPO 采用顺序 rollout , 每条轨迹必须在旧策略和新策略下独立采样 , 复杂度达到 O (N×T)(其中 T 是扩散步数 , N 是组大?。 ?。 这种重复采样带来大量计算冗余 , 严重限制了大规模生成任务的扩展性 。
稀疏奖励:现有方法通常只在最终生成结果上计算单一奖励 , 并将其均匀回传至所有步 。 这种 “稀疏且均匀” 的反馈忽视了中间状态中蕴含的关键信号 , 导致 credit assignment 不准确 , 训练波动大、收敛不稳 , 甚至出现高方差梯度 。
因此 , 一个关键问题被提出:如何在不破坏多样性的前提下 , 既提升采样效率 , 又让奖励信号更稠密、更稳定地作用于训练过程?
正是在这一背景下 , 我们提出了 BranchGRPO 。 通过树形分叉、奖励融合与剪枝机制 , BranchGRPO 做到了「又快又稳、又强又准」 , 为大规模视觉生成对齐开辟了新路径 。
BranchGRPO如何在扩散过程中分化出树形结构
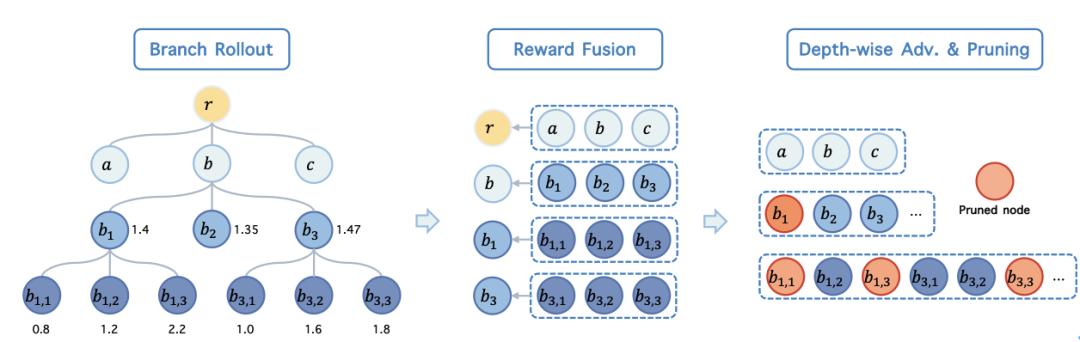
为突破顺序 rollout 的低效与稀疏奖励瓶颈 , BranchGRPO 将原本单一路径的采样过程 , 重构为一种树形展开:
分叉(Branching):在若干预设的扩散步上进行分裂 , 每条轨迹可以向多个子路径扩展 , 前缀计算被复用 , 大幅减少冗余采样 。 这种结构既保持了扩散过程的完整性 , 又让探索更高效 。 奖励融合与逐层归因(Reward FusionDepth-wise Advantage):不同于将单一终末奖励均匀分配到所有步骤 , BranchGRPO 将叶子节点的奖励自底向上传递 , 并在每一深度上进行标准化 , 形成逐步稠密的优势信号 , 使训练过程更稳定、更精准 。 剪枝(Pruning):为避免树形结构带来的指数级成本 , BranchGRPO 设计了两种剪枝策略: 宽度剪枝:仅保留关键叶子参与反向传播 , 减少梯度计算量; 深度剪枝:跳过部分层的反传(但保留前向和奖励评估) , 进一步压缩开销 。这一系列设计使得 BranchGRPO 在效率和稳定性之间实现了统一:既能显著加速训练、降低迭代开销 , 又能在奖励归因上更精细、更稳定 , 从而在图像与视频生成任务中同时提升对齐效果与收敛速度 。
精度、速度、稳定度
1.图像对齐(HPDv2.1):
在图像对齐测试中 , BranchGRPO 带来了真正的「又快又好」:
更快:
DanceGRPO (tf=1.0) 每迭代 698s;BranchGRPO 493s;剪枝版 314s;Mix 变体 148s(相对 698s 最高近 4.7× 加速)
更稳更准:
HPS-v2.1 0.363–0.369 , 稳定高于 DanceGRPO 的 0.360;ImageReward 1.319(DepPru) 为全表最佳 。
对比其他方法:
MixGRPO 虽然也能压缩时间到 289 秒 , 但对齐分数略有下降 , 并且 MixGRPO 训练常常不稳定;相比之下 , BranchGRPO-Mix 在极致加速的同时 , 依旧保持了与原始 BranchGRPO 相当的对齐效果和稳定的训练 , 展现出惊人的性价比 。
2.视频生成(WanX-1.3B)
在视频生成任务中 , BranchGRPO 同样展现了强大的优势:
更清晰:
不使用 RLHF 的基础模型常出现严重的闪烁和变形;DanceGRPO 虽有所改善 , 但画面依旧模糊、不够稳定 。 相比之下 , BranchGRPO 生成的视频帧更锐利 , 细节更丰富 , 角色和物体在时间维度上保持一致 , 真正实现了「流畅不掉帧」的观感 。
更快:
在相同硬件条件下 , DanceGRPO 每次迭代大约需要 近 20 分钟;而 BranchGRPO 仅需约 8 分钟 就能完成一次迭代 , 训练效率直接翻 2 倍以上 。
3.消融实验
从消融实验可以看到:适中的分支相关度、早期更密集的分裂能加快奖励提升;路径加权的奖励融合让训练更稳;深度剪枝带来最佳最终效果;而混合 ODE–SDE 调度则在保持稳定的同时达到最快训练速度 。
4.多样性保持:
分叉并未削弱样本分布 , MMD2≈0.019 , 几乎与顺序采样一致 。
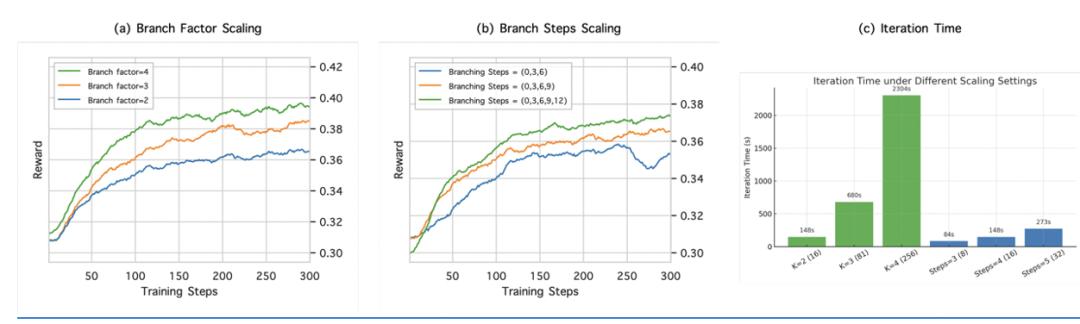
5. 扩展性(Scaling Law):
得益于 BranchGRPO 的高效性与训练稳定性 , 我们能够轻松扩大分支规模而不崩溃:无论是增加分支因子还是分支次数 , 性能都持续提升 。 比如在 81 个样本规模下 , DanceGRPO 每次迭代要花 2400 秒 , 而 BranchGRPO 只需 680 秒 , 真正把大规模对齐训练变得可行 。
总结与展望
BranchGRPO 通过树形分叉、奖励融合与轻量剪枝 , 创新性地融合了效率与稳定 , 奖励从「终点一锤子」变「全程有信号」—— 在速度、稳定与对齐效果上全面提升(HPDv2.1 最高近 5× , 视频生成更清晰更一致) 。 成为视觉生成对齐的新一代解决方案 。
未来 , 若引入自适应分裂 / 剪枝策略 , 并拓展至多模态与更大规模生成任务 , BranchGRPO 有望成为扩散 / 流模型 RLHF 的核心方法 , 为高效、稳定的人类偏好对齐提供新的范式 。
如果您在研究中使用BranchGRPO , 欢迎引用我们的工作:
@article{li2025branchgrpo
title={BranchGRPO: Stable and Efficient GRPO with Structured Branching in Diffusion Models
author={Li Yuming and Wang Yikai and Zhu Yuying and Zhao Zhongyu and Lu Ming and She Qi and Zhang Shanghang
journal={arXiv preprint arXiv:2509.06040
year={2025
参考链接:
DanceGRPO: Unleashing GRPO on Visual Generation:https://arxiv.org/abs/2505.07818
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE:
【北大与字节团队提出BranchGRPO,「树形分叉 + 剪枝」重塑扩散模型】https://arxiv.org/abs/2507.21802
推荐阅读
















- 荣耀AI智能体YOYO亮相科幻星云奖,联动刘慈欣共话科幻文学与AI
- 人工智能、意识与长寿:与迪帕克·乔普拉的对话
- 传三星已与IBM签订Power11芯片代工订单
- OpenAI找上立讯与歌尔打造全新AI硬件,目标出货1亿台!
- 三星证明实力!与IBM达成Power11芯片代工协议
- 微软建议用户“不要升级系统”,股票下滑原因可能就与它有关!
- vivo X300与iQOO 15:设计均出炉,配置规格也都悬念不大了
- 一加15跑分与外观双曝光:超高跑分+超窄边框,或成行业新标杆!
- iPhone 17快充升级实测:329元新充电头非必需,与普通PD充电头效果相近
- NVIDIA与英特尔宣布战略合作 共同开发AI基础设施与个人计算产品