
文章图片

文章图片
文章图片
文章图片

文章图片

机器之心报道
编辑:笑寒、陈陈
这或许是庞若鸣(Ruoming Pang)在苹果参与的最后一篇论文 。
庞若鸣 , 苹果基础模型团队负责人、杰出工程师 , 即将成为 Meta 新成立的超级智能团队的最新成员 。 他本科毕业于上海交通大学 , 在谷歌工作了 15 年 , 此后加入苹果 。 另据彭博社最新消息 , Meta 更是开出了 2 亿美金的天价来邀请庞若鸣加入 。
虽然即将跨入另一段人生旅程 , 但庞若鸣还在为苹果站好最后一班岗 。
7 月 9 日 , 庞若鸣在 X 上宣传了自己参与的一项研究《 AXLearn: Modular Large Model Training on Heterogeneous Infrastructure 》 , 据了解 , 这项研究是构建 Apple Foundation 模型的基础代码库 。
具体而言 , 本文设计并实现了 AXLearn , 一个用于大规模深度学习模型训练的生产级系统 , 其具备良好的可扩展性和高性能 。 与其他先进的深度学习系统相比 , AXLearn 具有独特的优势:高度模块化和对异构硬件基础设施的全面支持 。
AXLearn 内部的软件组件接口遵循严格的封装原则 , 使得不同组件能够灵活组合 , 从而在异构计算环境中快速进行模型开发和实验 。
此外 , 本文还提出了一种用于衡量模块化程度的新方法:基于代码行数的复杂度(LoC-complexity)指标 。 实验表明 , AXLearn 在系统扩展时可以保持恒定的复杂度 , 而其他系统则呈现出线性甚至二次增长的复杂度 。
例如 , 将 Rotary Position Embeddings(RoPE)这类功能集成到 AXLearn 的上百个模块中仅需约 10 行代码 , 而在其他系统中可能需要数百行代码才能实现相同效果 。 同时 , AXLearn 也保持了与主流高性能训练系统相当的训练性能 。
- 论文地址:https://arxiv.org/pdf/2507.05411
- 开源地址:https://github.com/apple/axlearn
- 论文标题: AXLearn: Modular Large Model Training on Heterogeneous Infrastructure
AXLearn 介绍
现阶段 , 像 ChatGPT、Gemini 这样的聊天机器人都是由大模型驱动的 。 这种深度学习系统会优先考虑性能和可扩展性 。
作为全球最大的消费电子和在线服务公司之一 , 苹果已经将许多 AI 模型集成到自家产品中 , 服务于全球数十亿用户 。
除了训练性能和可扩展性外 , 苹果对深度学习系统还有两个额外的要求 。 首先是赋能模型工程师 , 只需编写最少的代码 , 就能配置复杂的模型定义和训练方法 。 其次 , 作为一家大型科技公司 , 他们不能依赖单一的硬件供应商 , 因而他们的设计目标是兼容异构后端 , 如 GPU、TPU 和 AWS Trainium 。
为了达到上述目的 , AXLearn 被开发出来 。
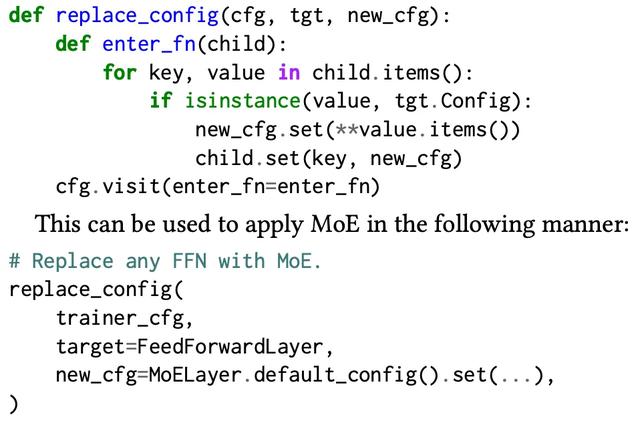
为了促进模块化 , AXLearn 的核心设计决策是强制执行严格的封装 。此外 , 本文还通过将旋转位置嵌入(RoPE)和专家混合模型(MoE)集成到 AXLearn 中的案例研究 , 展示了该框架与传统代码行数计数方法的一致性 。
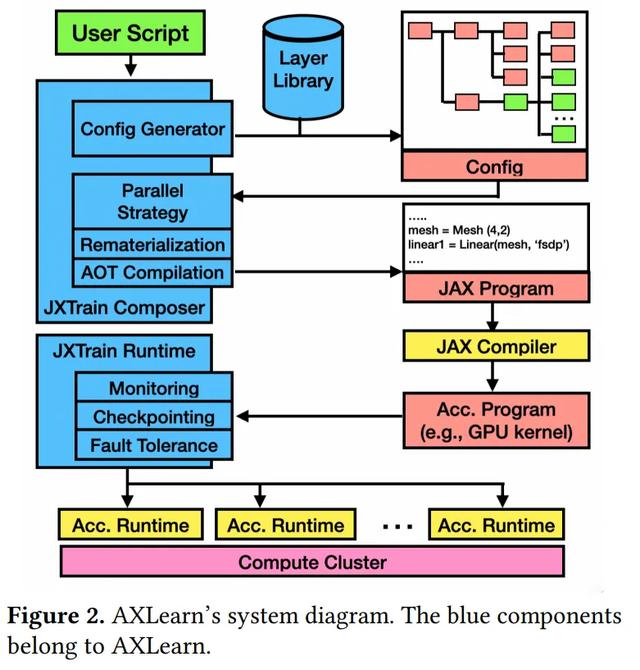
图 2 显示了 AXLearn 的系统架构和工作流程 。 AXLearn 有两个关键组件:
(1)AXLearn 组合器(AXLearn composer)和(2)AXLearn 执行框架(AXLearn runtime) 。
用户通常使用 AXLearn 内置的层库和第三方层组件来定义训练配置 。 基于该配置脚本 , AXLearn 组合器会首先生成完整的 JAX 程序 。
这一过程包含以下关键步骤: 包括为目标加速器实例选择合适的网格形状、为特定层应用分片注释、为目标硬件自动调优 XLA 编译选项、为后端选择合适的注意力内核 , 并根据模块层次中的标记点应用适当的重计算策略 。 这些注释对于训练的高效运行至关重要 。
然后 , JAX 程序和编译选项被传递给 XLA 编译器 , 以生成加速器程序(例如 , CUDA 内核) , 该程序随后通过 AXLearn 运行时在分布式硬件(例如 Kubernetes)上进行调度 , 并使用特定于加速器的运行时(例如 CUDA 运行时) 。
AXLearn 执行框架监控加速器程序的执行 , 并提供额外的功能 , 如高效的检查点、监控和容错能力 。
实验评估
下表展示了不同系统的代码量复杂度(LoC-Complexities)汇总 。
在 AXLearn 中 , RoPE 和 MoE 被严格封装 。 本文提供了一个 10 行的代码片段 , 可以将这两个功能集成到任何实验配置中 。
在本文的内部实践中 , 正是通过类似的代码片段 , 成功配置了超过 1000 个实验 , 用于启用 RoPE、MoE , 或两者同时使用 。 随着模块数量或 RoPE 或 MoE 变体的增加 , 无需对任何现有接口进行更改 , 实现了恒定的代码复杂性 。
在异构硬件上的性能
本文将 AXLearn 的训练性能与以下系统进行了对比:PyTorch FSDP、Megatron-LM 以及 MaxText , 这些系统在 GPU 与 TPU 上均实现了先进的训练性能 。
本文在三种硬件平台上评估了两个模型:Llama2 7B 与 Llama2 70B:
1. 256/512 H100 GPU(分别对应 32/64 个 AWS P5d 实例 , 每个实例含 8 张 H100);
2. TPU-v5p-512/1024(分别对应 64/128 个 GCP Cloud TPU 主机 , 每个主机含 4 颗芯片);
3. 1024 颗 Trainium2 芯片(64 个 AWS trn2 实例 , 每个实例含 16 颗 Trainium2 芯片) 。
下表总结了性能结果 。
为验证 AXLearn 的可扩展性 , 本文对两个实际部署的模型进行了弱扩展性(weak-scaling)实验 。
这些结果表明 , AXLearn 接近线性扩展性 , 如图 4 所示 。
AXLearn 在 TPU 上同样展现出业界领先的推理性能 。 本文对比了 AXLearn 与 vLLM 在 Llama2 7B 与 70B 参数模型上的推理表现 。
如表 4 和图 5 所示 , AXLearn 在延迟和吞吐量方面均显著优于 vLLM:
- 在延迟方面 , AXLearn 在 TTFT 和 TPOT 上分别实现了 500 倍和 6 倍加速;
- 在吞吐量方面 , AXLearn 在 7B 模型推理上快 2.8 倍 , 在 70B 模型上快 1.6 倍 。
在生产中的使用体验
如今 , AXLearn 已从最初仅有数位开发者、训练百万级参数模型的工具 , 发展为支持数百位开发者训练十亿至万亿参数规模模型的大型平台 。
它在任意时刻可并行支持超过 10000 个实验的开发与运行 , 并部署在数十种异构硬件集群上 。
借助 AXLearn 训练的部分模型 , 现已被广泛应用于十亿级用户规模的产品功能中 , 包括:智能助手、多模态理解与生成、代码智能等关键能力 。
【Meta为他豪掷2亿美元,上交校友庞若鸣,晒出在苹果的最新论文】了解更多内容 , 请参考原论文 。
推荐阅读














- 苹果大模型团队负责人叛逃Meta,华人AI巨星+1,年薪飙至9位数
- 高价从OpenAI和苹果挖AI人才的Meta 现金储备还超过550亿美元
- Meta以每年数千万美元待遇成功挖角苹果AI核心工程师
- 刚刚,Ilya被逼当CEO,联合创始人都被Meta挖跑了
- OpenAI CEO阿尔特曼怒斥Meta挖人 称使命感驱动者终将击败雇佣兵
- 让GUI智能体不再过度执行,上海交大、Meta联合发布OS-Kairos系统
- OpenAI四位华人学者入职Meta,小扎绝密「天才名单」曝光
- OpenAI人才防线崩塌:被Meta一周内两度挖角七人
- 美法院裁定AI训练用书属“合理使用”,Meta与Anthropic如释重负
- 美联邦法官在版权书籍训练AI模型诉讼中支持Meta