
文章图片

文章图片
文章图片
文章图片

文章图片
文章图片

文章图片

文章图片
6 亿次下载 , 17 万个衍生模型 , 服务超 100 万家客户 。
在 AI 大战最为激烈的 2025 年 , 全球使用最广泛的开源 AI 模型 , 来自阿里的通义大模型 。 毫不夸张地说 , 当全球开发者需要一个免费、好用、没有商业限制的模型时 , 它几乎成了默认选择 。
而在今天的云栖大会上 , 七款通义大模型家族新成员集中亮相 , 覆盖语言、视觉、语音、多模态、代码等多个方向 , 从开源生态到商业服务 , 几乎囊括了当下 AI 应用的所有关键环节 。
这七款模型分工明确:Qwen3-Max 承担「天花板」角色 , 万亿参数对标全球最强模型;Qwen3-Next 主打「普惠」 , 用小轿车油耗跑出跑车性能;Qwen3-VL 让草图秒变代码 , Qwen3-Omni 做全模态助理 , Qwen3-Coder 专攻编程 , Wan2.5-preview 实现电影级视频创作 , 通义百聆 Fun 提供上百种音色服务 。
阿里巴巴集团 CEO 吴泳铭直接公布了阿里云的两大路线图:一是通义千问坚持开源开放 , 目标成为「AI 时代的 Android」;二是构建「下一代计算机」——超级 AI 云 , 为全球提供智能算力网络 。
回头看 , 阿里可能做对了这个时代最重要的一个判断:AI 公司不仅要讲述超越人类智能的故事 , 更要讲述让每个人都能拥有 AI 的故事——而后者 , 或许更有想象力 。
从模型到生态 , 通义千问的全家桶来了模型七连发 , 通义千问大模型家族这次具体亮出了哪些「新牌」?梳理下来 , 看上去琳琅满目 , 其实主线很清晰:两张王牌 , 再加一桌子硬菜 。
发布会上多个模型已经在 Hugging Face 上开源
第一张王牌 , 是 Qwen3-Max 。
这是阿里的「天花板担当」 , 总参数超过万亿 , 预训练使用 36 万亿 tokens 。 在架构上还是延续 Qwen3 系列的 MoE 设计 , 但在训练手法上做了很多改进 。
比如用全局负载均衡和流水并行 , 让训练过程更稳定 , 不会出现异常波动;效率比上一代快了 30%;还能支持 100 万字级别的长文本;就连大规模集群里常见的硬件故障 , 也把时间损耗压缩到原来的五分之一 。
划重点:
旗舰模型 Qwen3 -Max 大幅提升编程和智能体能力 , 在多个基准测试中表现亮眼)
Qwen3-Max-Base:强调大规模高效训练 , 长上下文和稳定性突出 。 Qwen3-Max-Instruct:已在 LMArena 文本榜单排名全球前三 , 超过 GPT-5-Chat 。 在代码测试 SWE-Bench Verified 上拿到 69.6 分 , 在智能体工具调用基准 Tau2-Bench 上以 74.8 分超越 Claude Opus 4 和 DeepSeek-V3.1 。 Qwen3-Max-Thinking (Heavy):推理增强版 , 结合代码解释器与并行计算 , 在 AIME 25、HMMT 等高难度数学推理基准上取得 100% 正确率 , 展现出极强的推理潜力 , 尚在训练中 。整体来看 , Qwen3-Max 把工程体系、训练效率、长上下文、推理能力和智能体任务一并拉升到了全球顶尖水准 。 它在代码和推理基准上的成绩 , 说明中国模型正在真正进入可以与最强对手正面对话的阶段 。
第二张王牌 , 是 Qwen3-Next 。
如果说 Max 是阿里的面子 , Next 就是它的里子:真正让开发者和企业用得起、跑得动 。
大模型通常存在「不可能三角」——高性能、低成本、易部署 , 三者难以兼得 。 顶级性能的模型(如 GPT-4/5)往往意味着高昂的推理成本 , 成为 AI 普及的最大障碍 。
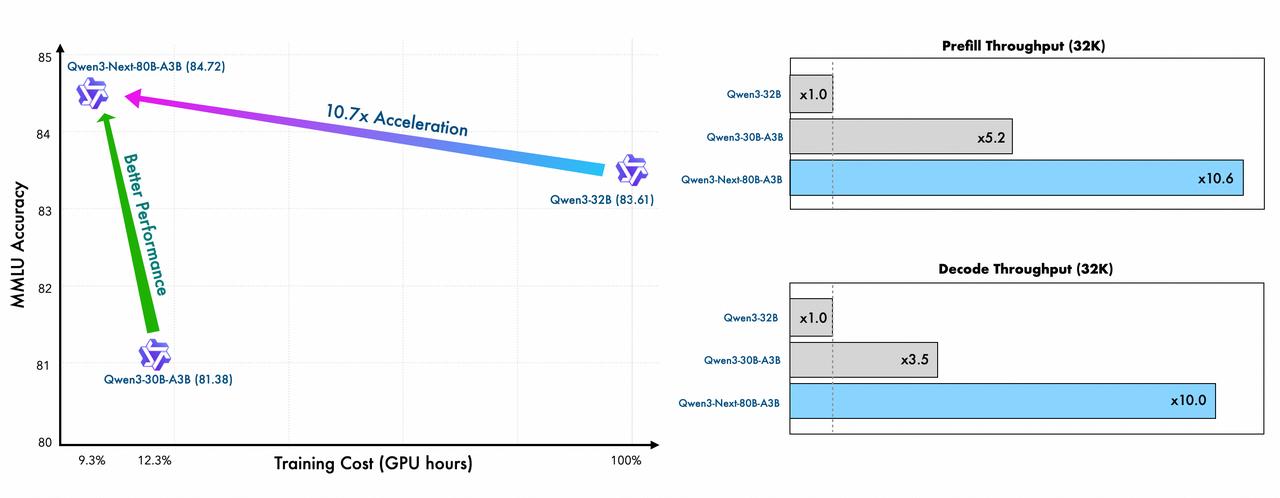
Qwen3-Next 训练效率和推理效率均得到大幅提升
而阿里的解法 , 就是用 Qwen3-Max 把性能的「天花板」捅破 , 再用 Qwen3-Next 把成本的「地板」砸穿 。
它通过高稀疏度 MoE、混合注意力等下一代架构创新 , 用 3B 的激活参数 , 达到了 235B 密集模型的性能, 相当于用一辆小轿车的油耗 , 跑出了跑车的性能 。 最终结果就是训练成本暴降 90% , 长文本推理效率提升十倍 。
【模型七连发刷新 SOTA ,中国正在诞生 AI 时代的 Android】Qwen3-Next 采用了全新的下一代模型架构 , 结合线性注意力和标准注意力 , Gated Delta Networks 的作者 Songlin Yang 转发 Qwen 推文
这种体系化的能力 , 让「人人都能用上 AI」的愿景从口号变为现实 , 也远比单纯发布一个高性能模型更具产业颠覆性 。
一桌硬菜:能想到的活它都包了
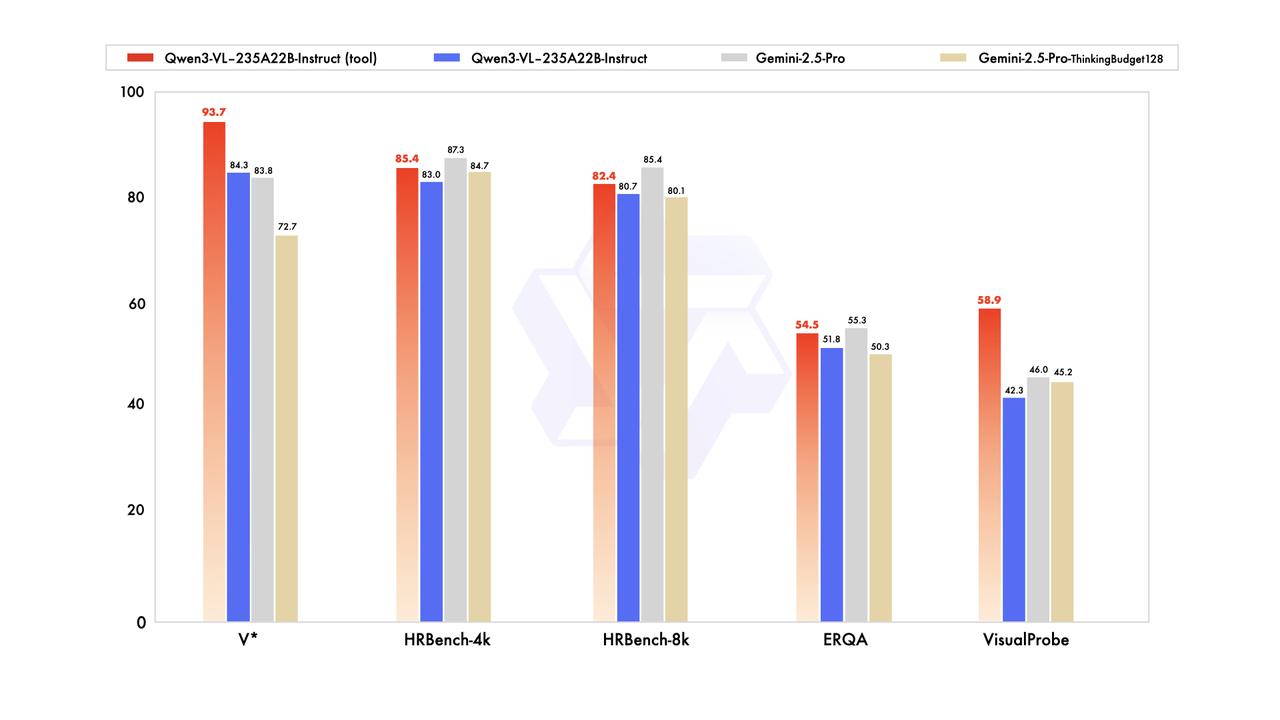
Qwen3-VL 视觉语言模型在多个基准测试中 , 性能表现超过 Gemini 2.5 Pro
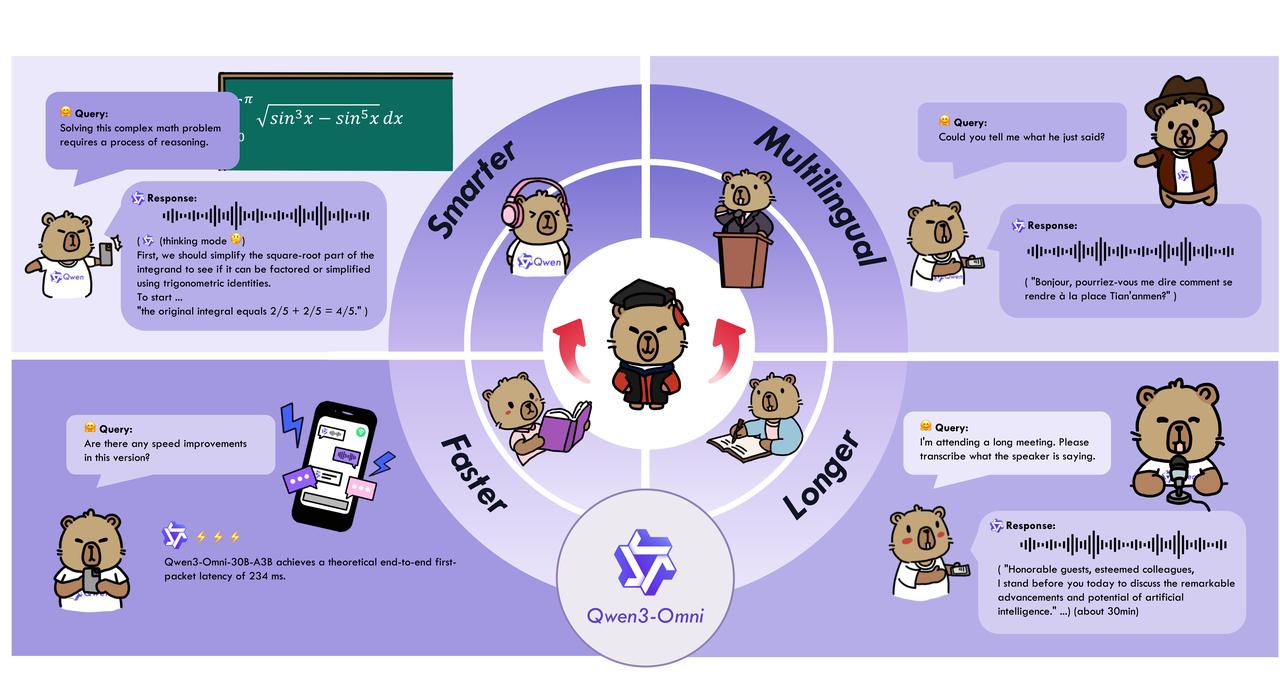
Qwen3-VL:视觉模型重磅开源 , 从「识图」进化到「推理与执行」 , 能操作电脑手机界面 , 也能把一张草图直接生成 HTML / CSS 代码 。 对很多产品经理来说 , 这意味着「所见即所得」真的成了现实 。 Qwen3-Omni:全模态选手 , 能同时处理文本、图像、音频和视频 。 在 36 项公开评测里拿下 32 项开源第一 , 22 项达到 SOTA 。 还能实时语音对话 , 甚至自定义人格 , 像是给你配了一个会讲十几种语言的随身助理 。 Qwen3-Omni 在全方位性能评估中 , 多项测试超越 Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe 等闭源模型
Qwen3-Coder:编程模型升级 , 速度更快 , 代码更安全 , 能直接帮你部署一个完整项目 , 修 bug 也不在话下 。 对开发者来说 , 它更像是一个随时在线的「结对编程伙伴」 。 Wan2.5-preview:AIGC 方向的杀手锏 。 文生视频、图生视频、文生图和图像编辑都更强了 , 最关键的是 , 第一次实现了「音画同步」的电影级视频生成 。 从 5 秒到 10 秒、1080P、24 帧 , 这已经不是玩具 , 而是一个可以让个人创作者拍短片的工具 。 此外 , 还有语音大模型通义百聆 Fun 家族 , 能提供上百种音色 , 覆盖客服、直播、电商和有声书等场景 。 以及基于 Qwen3 , 为全球实时 AI 安全构建的安全审核模型 Qwen3Guard;和实时多模态翻译模型 Qwen3-LiveTranslate-Flash 等 。
把这些放在一起看 , 你会发现阿里在传递一个很直接的信号:想要极致性能?有 Max 。 想要极致效率?有 Next 。 想要多模态探索?有 VL 和 Omni 。 想要代码和创作的生产力?有 Coder 和 Wan……
Qwen3-Omni 是新一代原生全模态大模型 , 能够无缝处理文本、图像、音频和视频等多种输入形式 , 目前已经可以在 Qwen Chat 中通过语音和视频聊天启用
这不是简单的「堆新品」 , 而是一整套全尺寸、全模态的生态拼图 。 阿里把它们一次性交到用户手里 , 像是在告诉所有企业、个人、还有开发者:不管你在做什么 , 通义模型家族 , 总有一块积木能搭得上 。
但这场「全家桶式发布」的意义 , 并不只在于产品层面的丰富 。 透过模型七连发的齐齐亮相 , 可以更清楚地看到 , 通义千问模型家族已经覆盖全尺寸、全模态 , 款款都在主流评测上立住了 SOTA 。
也正是基于这种厚实的路径 , 换来的是一种独特的行业地位 。 正如阿里巴巴集团 CEO 吴泳铭在今天发布会上所说:「通义千问 , 可以说是渗透全球计算设备最广泛的大模型 。 」
在全球最大的 AI 模型开源社区Hugging Face 上 , 输入关键字「qwen」 , 有超过 16 万相关的模型 , 且下载量均在百万级别 , 目前 Qwen 系列模型最高下载量达到 700 万(Qwen2.5-3B-Instruct) 。
截至目前 , 通义千问开源了三百多款模型 , 覆盖了全模态全尺寸 , 是中国应用最广泛而且最受全球开发者欢迎的开源模型 。 通义大模型全球下载量超过 6 亿次 , 衍生模型超过 17 万个 , 是全球第一的开源模型矩阵 。
显而易见 , 在这个依然由国际巨头主导的大模型赛道上 , 一个来自中国的开源模型家族 , 正在以自己的方式刷着「存在感」 , 也在刷新国产 AI 的历史地位 。
大模型下半场 , 通义千问要成为 AI 时代的 Android2019 年 , 阿里在 M6 上试水 10 万亿参数模型时 , 整个行业对于「大模型」这个概念更多还停留在学术讨论的层面 , 距离产业化仍有距离 。 四年后 , 通义千问的正式发布标志着一个拐点的到来 。
从 Qwen-7B、14B 到 72B , 再到今天的万亿参数 , Qwen 走的路径并不花哨 , 就是不断扩大规模、优化、验证 , 把一个模型家族一点点撑开 。
2024 年的 Qwen2 与 Qwen2.5 以及今天发布的 Qwen3-Max 模型总参数超过 1T , 预训练使用了 36T tokens , 代码能力和智能体(agent)能力方面进一步提升 。
而在大模型逐渐走向下半场 , 开源模型也成为不可逆转的趋势 。 中国则几乎成为全球开源里最重要的角色 , 其中以阿里和 DeepSeek 两家公司的戏份最重 。
吴泳铭对此直言不讳:「在 LLM 时代 , 开源模型创造的价值和能够渗透的场景 , 将会远远大于闭源模型」 。
全球的大模型公司各有侧重 , 有的主要服务自家生态 , 有的为社交和广告业务添砖加瓦 。 有的聚焦于工具化和用户增长 , 有的强调全模态整合 , 绑定搜索 。 而阿里则想成为那个「AI 时代的 Android 系统」 。
Android 的成功 , 不在于它比 iOS 更强更完美 , 而在于它能适配从几百块的老人机到上万块的折叠屏 , 让智能手机市场真正百花齐放 。
Qwen 的逻辑如出一辙 。 从0.5B 到万亿参数的「全尺寸」Qwen3-Max , 从写代码的 Qwen3-Coder 到能「看图写代码」的Qwen3-VL , 再到能听会说、音画同步的通义万相和通义百聆 , 甚至那个像真人一样能实时语音对话的Qwen3-Omni , 阿里几乎把开发者能想到的所有工具都备齐了 。
这背后是一种思路的转变:阿里不再替你决定「应该用什么」 , 而是把选择权、定义权 , 乃至最终的成本控制权 , 都交还给了市场 。
而 Qwen 则去扮演那个最苦最累但又无可替代的角色——AI 时代的 Android 系统 , 让 AI 应用和场景落地提供基础「水电煤」 。
实际上已经有超过 100 万家企业通过阿里云接入通义大模型的服务 。 就像接入水电一样 , 把 AI 当作最基础的生产力 。 而苹果国行 AI 虽然一再推迟 , 但也基本已经确定与 Qwen 合作 , 这是中国大模型第一次进入 iPhone 。
今天云栖大会上吴泳铭也宣布 , 未来三年阿里将投入超 3800 亿元 , 用于云和 AI 硬件基础设施建设 , 并计划追加更大的投入 。 根据远期规划 , 为了迎接 ASI 时代的到来 , 对比 2022 年的 GenAI 元年 , 2032 年阿里云全球数据中心的能耗规模将提升 10 倍 。
这也是阿里云从 2022 年开始坚持的「模型即服务」(MaaS) 。 它将大模型定位为生产力的核心要素 , 依托阿里云的算力和基础设施 , 为企业提供高性能、低成本的 AI 能力 。
当一个平台尝试去降低整个社会的创新门槛 , 其所能托举的 , 就不仅仅是自身的商业价值 。
对于在「用谁家的模型」这个问题上纠结的开发者和企业来说 , 一个开放、便宜、还好用的「AI Android」系统的出现 , 就相当于回到大航海时代 , 有人为你建好了出海的港口 , 还顺手把全世界的航海图都开源了 。
除了扬帆起航 , 似乎也别无他选 。
作者:李超凡、张子豪、莫崇宇
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr) , 更多精彩内容第一时间为您奉上 。
爱范儿|原文链接· ·新浪微博
推荐阅读














- LightVLA可微分token剪枝,首次实现VLA模型性能和效率的双重突破
- 西湖大学发布世界模型WorldForge,普通视频模型秒变「世界引擎」
- IDC:2025年上半年大模型公有云市场,火山引擎占比49.2%排名第一
- 为什么大模型要骗你?
- 北大与字节团队提出BranchGRPO,「树形分叉 + 剪枝」重塑扩散模型
- 全自研芯片计算!百度智能云Qianfan-VL系列模型重磅开源
- Mini-Omni-Reasoner:实时推理,定义下一代端到端对话模型
- 马斯克新模型:9折价格实现Gemini 2.5性能,支持2M上下文
- 攻克大模型训推差异难题,蚂蚁开源新一代推理模型Ring-flash-2.0
- 海淀105款大模型背后:看这些AI玩家如何抢占内容生产制高点