文章图片
文章图片

文章图片
文章图片
文章图片
文章图片
机器之心发布
机器之心编辑部
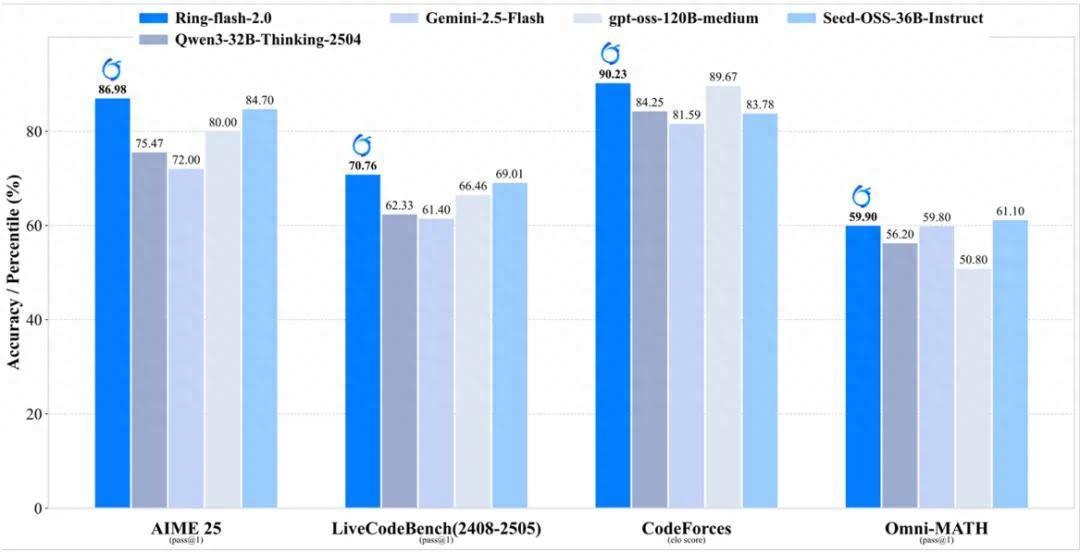
“MoE+Long-CoT(长思维链)+RL(强化学习)” 这条技术路线存在难以兼顾训练稳定性和效果的难题 。 9 月 19 日 , 蚂蚁百灵大模型团队把 “难啃的骨头” 直接做成开源礼包 ——Ring-flash-2.0 。 100B 总参、6.1B 激活 , 数学 AIME25 拿下 86.98 分 , CodeForces elo 分数 90.23 , 128K 上下文实测 200+token/s 。
更关键的是 , 他们通过独创的棒冰(icepop)算法和长周期的 RL 训练 , Ring-flash-2.0 在多项推理榜单上(数学、代码和逻辑推理)取得了显著突破 , 性能达到了 40B 以内 dense 模型的 SOTA 水平 , 甚至可与参数量更大的 MoE 模型相媲美 。
Ring-flash-2.0 性能表现
机器之心深度拆解 , 这一开源项目 , 为什么可能改写下一阶段大模型的竞争节奏 。
一、从 “不能用” 到 “敢开源”:MoE 长思考的临界点
2025 年 , 业内流行一张 “死亡曲线”:在长思维链场景下 , MoE 模型 RL 训练存在奖励崩溃的问题 。 于是大家只能把学习率调小、任务提前终止 , 无法继续训练 。
棒冰(icepop)算法:让 RL 进行长周期的稳定训练
Ring-flash-2.0 的破冰点在于 “棒冰(icepop)”:双向截断 + 掩码修正 , 一句话总结 ——“把训推精度差异过大的 token 当场冻住 , 不让它回传梯度” 。
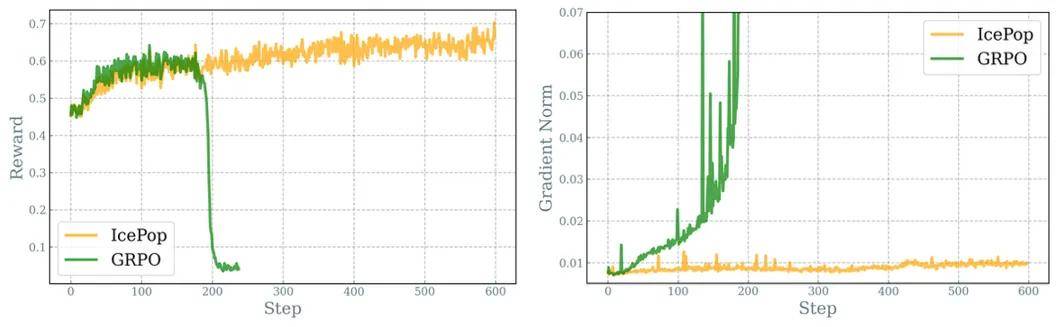
最终 , icepop 能够保持稳定的强化学习训练过程 , 避免了 GRPO 出现的训练崩溃问题 。
左图为 GRPO 训练到 180-200 步开始崩溃 , icepop 能实现持续稳定提升; 右图为 GRPO 训练不久出现梯度爆炸 , icepop 能持续稳定在合理范围 。
与 GRPO 相比 , icepop 还将训推精度差异约束在合理范围内 , 显示出对于控制训推精度差异有效性 。
左图为 GRPO 训推精度差异随着训练成指数上升 , icepop 较为平稳;右图为训推精度差异最大值 , GRPO 随着训练上升非常明显 , icepop 维持在较低水位 。
效果肉眼可见:训练再也不崩 , 百灵团队内部笑称 , “终于不用担心训练无法长跑的问题” 。
详细的棒冰(icepop)算法介绍参考技术博客:https://ringtech.notion.site/icepop
Two-staged RL:先 “算对” , 再 “像人”
百灵大模型团队首先采用 Long-CoT SFT , 采用包含数学、代码、逻辑和科学四大领域为主体的多学科高质量推理数据集 , 让模型 “学会思考”;第二步 , 通过可验证奖励的 RLVR(Reinforcement Learning with Verifiable Rewards) , 把推理逼到极限;随后 , 加入 RLHF , 用高质量人类偏好数据 , 把格式、安全、可读性拉回舒适区 。
百灵团队验证了直接融合 RLVR+RLHF 的联合训练和 Two-staged RL , 两种方式在实验中效果差异不大 。但由于 RLVR 和 RLHF 的问题难度不一致 , RLHF 的思维链长度相对较短 , 放在一起训练会有较多等待长尾现象 , 从工程效率角度 , 使用了 Two-staged RL 方案 。
二、6.1B 激活打平 40B Dense , 成本曲线出现 “拐点”
大模型竞争进入 “第二幕” , 核心指标不再是 “谁参数多” , 而是 “谁性价比高” 。
Ring-flash-2.0 架构图 。
继承 Ling 2.0 系列的高效 MoE 设计 , 通过 1/32 专家激活比、MTP 层等架构优化 , Ring-flash-2.0 仅激活 6.1B (non-embedding 4.8B) 参数 , 即可等效撬动约 40B dense 模型的性能 。
得益于小激活、高稀疏度的设计 , Ring-flash-2.0 在 4 张 H20 部署下实现 200+ token/s 的吞吐 , 大幅降低高并发场景下 Thinking 模型的推理成本 。 同时 , Ring-flash 借助 YaRN 外推可支持 128K 长上下文 , 随着输出长度的增加 , 其相对加速比最高可达 7 倍以上 。
【攻克大模型训推差异难题,蚂蚁开源新一代推理模型Ring-flash-2.0】生成速度对比
竞赛数学视频
贪吃蛇case
arcprize case
冒泡排序可视化
粒子烟花模拟
生成搜索引擎首页 query:请仿照 Perplexity , 设计并生成一个搜索引擎首页 , 网站名称为 “想搜” , slogan 为 “想搜 , 才会赢” 。 请实现基本的搜索界面、风格化 Banner 和搜索输入区 。
生成搜索引擎首页
结语:大模型竞争进入 “高性价比” 时代
从 2022 年 ChatGPT 点燃生成式 AI , 到 2024 年长思考成为新战场 , 行业一直在等一个 “既聪明又便宜” 的推理模型 。 Ring-flash-2.0 用 100B 总参、6.1B 激活、200+token/s 的速度 , 把「Long-CoT + RL」做到工程可落地 , 还顺手把训练稳定性、推理成本、开源生态一次性打包 。
如果说 GPT-4 开启了 “大模型可用时代” , 那 Ring-flash-2.0 或许正式拉开了 “MoE 长思考高性价比时代” 的帷幕 。 剩下的问题只有一个:你准备用它做什么?
开源地址:
HuggingFace:https://huggingface.co/inclusionAI/Ring-flash-2.0 ModelScope:https://modelscope.cn/models/inclusionAI/Ring-flash-2.0 GitHub: https://github.com/inclusionAI/Ring-V2 技术博客: https://ringtech.notion.site/icepop文中视频链接:https://mp.weixin.qq.com/s/GP6SkIP0Pq1j08XL0XccoQ
推荐阅读















- 海淀105款大模型背后:看这些AI玩家如何抢占内容生产制高点
- IDC:2025年上半年大模型公有云市场 火山引擎占比49.2%排名第一
- 梁文锋在《自然》发表封面论文,DeepSeek成首个严格学术审查大模型
- iPhone18ProMax或迎来黑色回归?苹果终于攻克掉漆魔咒!
- 降低大模型幻觉、让企业AI输出更靠谱,亚马逊云科技掏出10年家底
- MachineLearningLM给大模型上下文学习装上「机器学习引擎」
- 大模型碰到真难题了,测了500道,o3 Pro仅通过15%
- KV Cache预算降至1.5%!他们用进化算法把大模型内存占用砍下来了
- 上海AI“北斗七星”矩阵再添成果,斑马智行元神AI大模型完成备案
- 机器人交互、金融大模型轮番上阵 服贸会上银行展出满满科技感