
文章图片
本文由半导体产业纵横(ID:ICVIEWS)综合
效率最高可达现有旗舰机架的7.5倍 。
英伟达于9月9日正式发布了一款专为处理海量上下文而打造的新型GPU——NVIDIA Rubin CPX , 旨在“以前所未有的速度和效率 , 赋能百万级Token的软件编码、生成式视频等复杂AI任务 。 ”
这款专用处理器将与NVIDIA Vera CPU及下一代Rubin GPU协同工作 , 共同构成全新的NVIDIA Vera Rubin NVL144 CPX集成平台 。 该平台在单个机柜内即可提供高达8 exaflops的AI算力 , 性能是当前NVIDIA GB300 NVL72系统的7.5倍 , 并配备100TB高速内存和每秒1.7 PB的内存带宽 , 为AI推理设定了全新基准 。
NVIDIA创始人兼首席执行官黄仁勋在发布会上表示:“Vera Rubin平台将标志着AI计算前沿的又一次飞跃 。 正如RTX彻底改变了图形和物理AI , Rubin CPX是首款专为海量上下文AI打造的CUDA GPU , 在这种场景下 , 模型可以一次性对数百万token的知识进行推理 。 ”
为解决推理瓶颈而生:分解式推理架构与专用加速英伟达表示 , 推理已成为人工智能复杂性的新前沿 。 现代模型正演变为能够进行多步推理、拥有持久内存和长上下文的智能体系统 , 使其能够处理软件开发、视频生成和深度研究等领域的复杂任务 。 这些工作负载对基础设施提出了前所未有的要求 , 在计算、内存和网络方面引入了新的挑战 , 需要我们从根本上重新思考如何扩展和优化推理 。
在这些挑战中 , 为特定类别的工作负载处理海量上下文变得日益关键 。 例如 , 在软件开发中 , AI系统必须对整个代码库进行推理 , 维护跨文件的依赖关系 , 并理解代码仓库级别的结构——这正将编码助手从自动补全工具转变为智能协作者 。 同样 , 长视频和研究应用要求在数百万token中保持持续的连贯性和记忆 。 这些需求正在挑战当前基础设施所能支持的极限 。
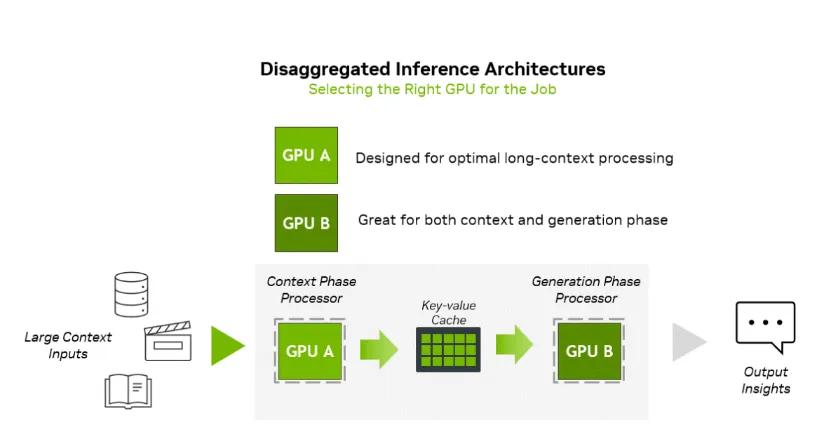
英伟达认为 , AI推理主要分为两个阶段:上下文阶段(Context Phase)和生成阶段(Generation Phase) 。 前者是计算密集型 , 需要高吞吐量处理海量输入数据;后者是内存带宽密集型 , 依赖高速数据传输逐个生成token 。 为优化效率 , NVIDIA采用了“分解式推理”架构 , 将两个阶段交由最适合的硬件独立处理 。
而NVIDIA Rubin CPX正是为加速计算密集的“上下文阶段”而设计的专用解决方案 。 它采用高成本效益的单片式芯片设计 , 提供高达30 petaflops的NVFP4精度算力 , 配备128GB GDDR7内存 , 并将注意力(attention)功能速度提升至GB300 NVL72的三倍 。 此外 , 它还在单芯片上集成了视频编解码器和长上下文推理处理功能 , 极大地提升了视频搜索、高清视频生成等应用的性能 。
NVIDIA指出 , 通过这种专用硬件 , 企业能够以前所未有的规模创造价值 , 预计每投入1亿美元资本 , 即可带来高达50亿美元的token收入 。
行业领导者积极拥抱 , 软件生态全面支持新平台已获得行业创新者的广泛关注 。 AI代码编辑器开发商Cursor表示 , Rubin CPX将带来“闪电般的代码生成速度” , 改变软件开发模式 。 生成式AI公司Runway认为 , 新平台是“性能上的一次重大飞跃” , 将帮助创作者在视频工作中获得前所未有的速度与真实感 。 致力于软件工程自动化的AI研究公司Magic也指出 , Rubin CPX能极大地加速其处理亿级token上下文模型的计算工作负载 。
Rubin CPX将得到NVIDIA AI技术栈的全面支持 , 包括可高效扩展AI推理的NVIDIA Dynamo平台、NVIDIA Nemotron多模态模型系列以及包含NIM微服务的NVIDIA AI Enterprise企业级软件平台 。
NVIDIA Rubin CPX平台预计将于2026年底正式上市 。
GB300 NVL72系统基准最新测试结果公布在发布未来架构的同时 , NVIDIA于9月9日公布的最新MLPerf Inference v5.1行业基准测试结果中 , 再次彰显了其在当前AI推理领域的领导地位 。
本轮测试中 , NVIDIA首次提交了基于全新Blackwell Ultra架构(通过GB300 NVL72系统)的成绩 , 并立即刷新了所有新增基准测试的性能记录 , 包括Llama 3.1 405B和Whisper等 。
尤其是在处理高达6710亿参数的混合专家模型DeepSeek-R1时 , Blackwell Ultra的单GPU性能达到了上一代Hopper架构的约5倍 , 实现了巨大的性能飞跃 。 这一成就得益于NVIDIA的全栈优化能力 , 包括:广泛应用NVFP4四位浮点格式进行加速、通过TensorRT-LLM等软件库实现先进的模型和KV缓存量化 , 以及为复杂模型开发的全新并行技术 。
*声明:本文系原作者创作 。 文章内容系其个人观点 , 我方转载仅为分享与讨论 , 不代表我方赞成或认同 , 如有异议 , 请联系后台 。
【英伟达深夜突放大招,全新GPU为长上下文推理而生】想要获取半导体产业的前沿洞见、技术速递、趋势解析 , 关注我们!
推荐阅读













- NVIDIA突然官宣下代新GPU!多达128GB显存
- 唱衰ASIC惨遭博通打脸,英伟达称自家GPU更具性价比!
- 博通ASIC来势汹汹,英伟达无惧!
- OpenAI携手博通自研芯片,科技巨头围攻英伟达
- 苹果良心了:iPhone 17系列支持40W快充 最高或达60W
- 已有2大国产PC操作系统,能替代windows了,生态数达1000万
- 上半年全球折叠屏手机市场:华为份额高达48%,是三星的2.4倍!
- 三星将向英伟达大量供应GDDR7,传将用于对华特供的B30芯片
- 思科联手英伟达和VAST推出安全AI工厂解决方案
- 小红书「种草直达」向全行业品牌开放,组合投放策略提升进店效率76%