文章图片

文章图片

文章图片

文章图片

文章图片

机器之心报道
编辑:+0、张倩
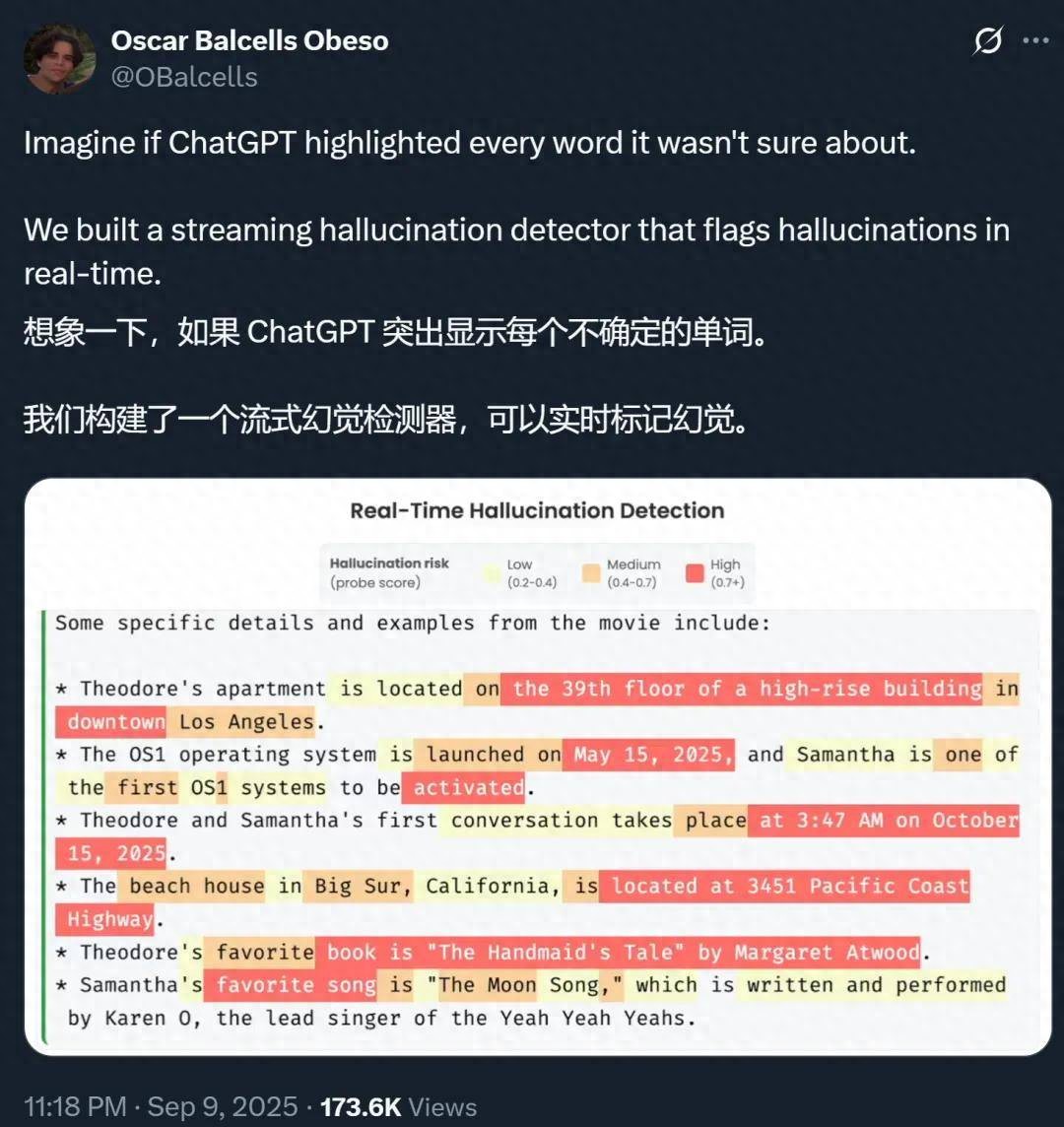
【AI胡说八道这事,终于有人管了?】想象一下 , 如果 ChatGPT 等 AI 大模型在生成的时候 , 能把自己不确定的地方都标记出来 , 你会不会对它们生成的答案放心很多?
上周末 , OpenAI 发的一篇论文引爆了社区 。 这篇论文系统性地揭示了幻觉的根源 , 指出问题出在奖励上 —— 标准的训练和评估程序更倾向于对猜测进行奖励 , 而不是在模型勇于承认不确定时给予奖励 。 可能就是因为意识到了这个问题 , 并找出了针对性的解法 , GPT-5 的幻觉率大幅降低 。
随着 AI 大模型在医疗咨询、法律建议等高风险领域的应用不断深入 , 幻觉问题会变得越来越棘手 , 因此不少研究者都在往这一方向发力 。 除了像 OpenAI 那样寻找幻觉原因 , 还有不少人在研究幻觉检测技术 。 然而 , 现有的幻觉检测技术在实际应用中面临瓶颈 , 通常仅适用于简短的事实性查询 , 或需要借助昂贵的外部资源进行验证 。
针对这一挑战 , 来自苏黎世联邦理工学院(ETH)和 MATS 的一项新研究提出了一种低成本、可扩展的检测方法 , 能够实时识别长篇内容中的「幻觉 token」 , 并成功应用于高达 700 亿(70B)参数的大型模型 。
论文标题:Real-Time Detection of Hallucinated Entities in Long-Form Generation 论文地址:https://arxiv.org/abs/2509.03531 代码地址:https://github.com/obalcells/hallucination_probes 项目地址:https://www.hallucination-probes.com/ 代码和数据集:https://github.com/obalcells/hallucination_probes该方法的核心是精准识别实体级幻觉 , 例如捏造的人名、日期或引文 , 而非判断整个陈述的真伪 。 这种策略使其能够自然地映射到 token 级别的标签 , 从而实现实时流式检测 。
通过 token 级探针检测幻觉实体 。 在长文本生成场景(Long Fact、HealthBench)中 , 线性探针的性能远超基于不确定性的基线方法 , 而 LoRA 探针则进一步提升了性能 。 该探针同样在短文本场景(TriviaQA)以及分布外推理领域(MATH)中表现出色 。 图中展示的是 Llama-3.3-70B 模型的结果 。
为实现这一目标 , 研究人员开发了一种高效的标注流程 。 他们利用网络搜索来验证模型生成内容中的实体 , 并为每一个 token 标注是否有事实依据 。 基于这个专门构建的数据集 , 研究人员通过线性探针(linear probes)等简洁高效的技术 , 成功训练出精准的幻觉分类器 。
在对四种主流模型家族的评估中 , 该分类器的表现全面超越了现有基准方法 。 尤其是在处理长篇回复时 , 其效果远胜于语义熵(semantic entropy)等计算成本更高的方法 。 例如 , 在 Llama-3.3-70B 模型上 , 该方法的 AUC(分类器性能指标)达到了 0.90 , 而基准方法仅为 0.71 。 此外 , 它在短式问答场景中也展现出优越的性能 。
值得注意的是 , 尽管该分类器仅使用实体级标签进行训练 , 它却能有效识别数学推理任务中的错误答案 。 这一发现表明 , 该方法具备了超越实体检测的泛化能力 , 能够识别更广泛的逻辑错误 。
虽然原始数据集的标注成本高昂 , 但研究发现 , 基于一个模型标注的数据可被复用于训练针对其他模型的有效分类器 。 因此 , 研究团队已公开发布此数据集 , 以推动社区的后续研究 。
方法概览
用于 token 级幻觉检测的数据集构建
为了训练能够在 token 级别检测幻觉的分类器 , 研究者需要一个对长文本中的幻觉内容有精确标注的数据集 。 这个过程分为两步:(1) 生成包含事实与幻觉内容的混合文本 ;(2) 对这些文本进行准确的 token 级标注 , 以识别哪些 token 属于被捏造的实体 。 下图展示了该标注流程 。
token 级标注流水线 。
数据生成研究者在 LongFact 数据集的基础上 , 创建了一个规模扩大 10 倍、领域更多样化的提示集 LongFact++ 。
LongFact++ 包含主题查询、名人传记、引文生成和法律案件等四类提示 , 旨在诱导大语言模型生成富含实体的长文本 , 作为后续标注的原材料 。
token 级标注与传统方法将文本分解为 atomic claims 不同 , 该研究专注于标注实体(如人名、日期、引文等) , 因为实体有明确的 token 边界 , 易于进行流式检测 。 他们使用带有网络搜索功能的 Claude 4 Sonnet 模型来自动完成标注流程 。
该系统会识别文本中的实体 , 通过网络搜索验证其真实性 , 并将其标记为「Supported」(有证据支持)、「Not Supported」(被证实是捏造的)或「Insufficient Information」(信息不足) 。
标签质量为验证标注质量 , 研究者进行了两项检查 。 首先 , 人类标注员的标注结果与大模型自动标注结果的一致性为 84% 。 其次 , 在一个包含已知错误(人工注入)的受控数据集中 , 该标注流程的召回率为 80.6% , 假阳性率为 15.8%。
训练 token 级探针
实验结果
在长文本设置中(LongFact 和 HealthBench) , token 级探针在两个主要模型上的表现都显著优于基线方法(表 1) 。 简单的线性探针始终实现了 0.85 以上的 AUC 值 , 而 LoRA 探针进一步提升了性能 , 将 AUC 推高到 0.89 以上 。
相比之下 , 基于不确定性的基线方法表现均不佳 , AUC 值均未超过 0.76 。 在短文本设置中(TriviaQA) , 基线方法比长文本设置中表现更强 , 但探针仍然领先 。 LoRA 探针始终实现了超过 0.96 的 AUC 值 , 线性探针也表现良好 。 值得注意的是 , 本文提出的探针在 MATH 数据集上也取得了强劲的结果 。 这种分布外的性能表明 , 本文提出的方法捕获了正确性的信号 , 这些信号的泛化性超出了其最初针对的虚构实体 。
作者在三个次要模型上复制了长文本结果 , 每个模型仅使用 2000 个其自身长文本生成的注释样本进行训练 。 结果是相似的:LoRA 探针再次优于线性探针 , 在 LongFact 生成上的 AUC 值在 0.87-0.90 之间 。 次要模型的完整结果显示在表 5 中 。
虽然 LoRA 探针的 AUC 值在多个设置中接近或超过 0.9 , 但长文本上的 R@0.1 最高约为 0.7 , 即在 10% 假阳性率下 , 检测器能够识别出大约三分之二的幻觉实体 。 这些结果既突出了相对于标准基于不确定性基线方法的实际收益 , 也表明在这类方法能够广泛应用于高风险场景之前 , 仍有进一步改进的空间 。
更多细节请参见原论文 。
推荐阅读














- 魅族22终于定档!直接公布外观,官方继续深表歉意
- 国行版iPhone AI,终于要发
- 1.5cm!新 iPhone 灵动岛终于变了
- 0.01%参数定生死!苹果揭秘LLM「超级权重」,删掉就会胡说八道
- 终于不再藏着掖着,时隔4年,余承东能公开华为麒麟芯片了
- 8.8英寸+SIM卡,华为新机定价3899元,你们要的通话平板终于来了
- 余承东公布麒麟9020,终于不藏着掖着了
- 麒麟9020+鸿蒙5.1,定价17999元起,华为新机终于硬气了
- iPhone 17 Pro Max 史诗级更新,终于来了
- 麒麟终于明牌!上一款公开麒麟芯的华为旗舰,还是“万象双环”