文章图片
文章图片

文章图片

机器之心发布
机器之心编辑部
视频是信息密度最高、情感表达最丰富的媒介之一 , 高度还原现实的复杂性与细节 。 正因如此 , 视频也是编辑难度最高的一类数字内容 。 在传统的视频编辑流程中 , 若要调整或替换主体、场景、色彩或是移除一个物体 , 往往意味着无数帧的手动标注、遮罩绘制和精细调色 。 即使是经验丰富的后期团队 , 也很难在复杂场景中保持编辑内容的时间一致性 。
近年来 , 生成式 AI 尤其是扩散模型与多模态大模型的快速迭代 , 为视频编辑带来了全新的解题思路 。 从早期基于规则的特效工具 , 到目标识别与自动分割 , 再到基于文本指令的视频生成与重绘 , 尽管 AI 已经为视频编辑带来了效率与可控性的双重提升 , 但在精度要求较高的场景中仍存在一系列挑战 , 例如当前很多零样本方法在处理连续视频帧时容易造成画面闪烁;对于背景复杂或多目标场景 , 可能会出现错位、模糊或语义偏差 。
针对于此 , 北京大学相机智能实验室(施柏鑫团队)联合 OpenBayes贝式计算 , 以及北京邮电大学人工智能学院模式识别实验室李思副教授团队 , 共同提出了一种结合草图与文本引导的视频实例重绘方法 VIRES , 支持对视频主体的重绘、替换、生成与移除等多种编辑操作 。 该方法利用文本生成视频模型的先验知识 , 确保时间上的一致性 , 同时还提出了带有标准化自适应缩放机制的 Sequential ControlNet , 能够有效提取结构布局并自适应捕捉高对比度的草图细节 。 更进一步地 , 研究团队在 DiT(diffusion transformer) backbone 中引入草图注意力机制 , 以解读并注入细颗粒度的草图语义 。 实验结果表明 , VIRES 在视频质量、时间一致性、条件对齐和用户评分等多方面均优于现有 SOTA 模型 。
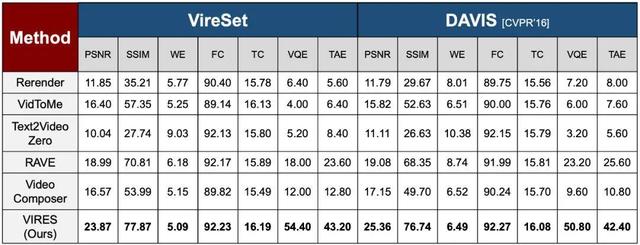
VIRES 与 5 种现有方法在不同数据集上的多类指标得分
相关研究以「VIRES: Video Instance Repainting via Sketch and Text Guided Generation」为题 , 已入选 CVPR 2025 。
- 论文主页:https://hjzheng.net/projects/VIRES/
- 项目开源地址:https://github.com/suimuc/VIRES
- Hugging Face地址:https://huggingface.co/suimu/VIRES
- 研究所用数据集下载地址:https://go.hyper.ai/n5pgy
为了实现精准的可控视频实例重绘 , 研究团队标注了大量视频实例的 Sketch 序列、Mask 以及文本描述 , 提出了一个配备详细注释的大规模视频实例数据集 VireSet 。 其中包含了 86k 视频片段、连续的视频 Mask、详细的草图序列 , 以及高质量的文本描述 。
此前 , Meta 曾开源了一个大规模视频分割数据集 Segment Anything Video dataset(SA-V 数据集) , 提供了 51k 个视频以及 643k 个实例 Mask 。 然而 , 其中实例 Mask 的标注是间隔 4 帧标注一次 , 因此 FPS 为 6 , 导致 Mask 非常不连贯 。 为了得到连贯的视频实例 Mask , 研究团队利用预训练的 SAM-2 模型 , 对中间帧进行标注 , 从而将 Mask 的 FPS 提高到 24 。 效果对比如下所示:
原视频
SA-V 提供的 Mask
研究团队标注的 Mask
随后 , 研究团队采用预训练的 PLLaVA 模型为每个视频片段生成文本描述 , 并利用边缘检测算法 HED 提取每个视频实例的 Sketch 序列 , 为每个实例提供结构上的指导信息 。
The video shows a small dark-colored goat with a blue and white striped cloth draped over its back. The goat is seen walking across a grassy area with patches of dirt. The background includes green vegetation and some sunlight filtering through the trees creating a serene outdoor setting. The goat appears to be moving at a steady pace.
结合草图与文本引导的视频实例重绘方法 VIRES
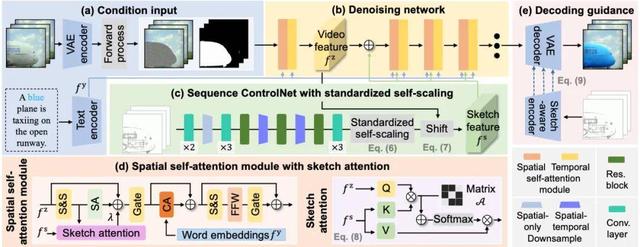
VIRES 主要由 3 大模块组成:带有标准化自适应缩放的 Sequential ControlNet , 带有草图注意力机制的 DiT backbone , 以及用于改进解码过程的草图感知编码器 , VIRES 的工作流程如下图所示 。
VIRES 的工作流程
如图 a 所示 , 输入视频首先被 VAE 压缩 64 倍空间纬度和 4 倍时间纬度 , 变成潜码 , 噪声会根据 Mask 序列被选择性地添加到潜码中 。 随后 , 该噪声潜码被送入去噪网络(Denoising network)进行去噪 , 如图 b 所示 。 该网络由多个具有时间和空间注意力机制的 Transformer 块堆叠组成 。
为了实现对实例属性的精确控制 , 研究团队提出了 Sequential ControlNet , 从 Sketch 序列中提取结构布局 , 如图 c 所示 。 为了自适应地捕捉 Sketch 序列中的细节 , 团队引入了 Standardized self-scaling 来增强 Sketch 序列中黑色边缘线与白色背景之间的高对比度过渡 。 此外 , 为了确保稳定且高效的训练 , 其根据视频潜码特征的均值 , 对齐处理后的 Sketch 特征与视频潜码特征 , 确保 Sketch 特征和视频潜码特征具有相似的数据分布 。
为了在潜在空间中解释和注入细粒度的草图语义 , 研究团队设计了 Sketch Attention 来增强去噪网络的空间注意力块 , 如图 d 所示 , Sketch Attention 结合了一个预定义的二进制矩阵 A, 以指示视频潜码与 Sketch 序列之间的对应关系 。
最后 , 为了在潜空间内将编辑结果与 Sketch 序列进一步对齐 , 团队引入了草图感知编码器 , 提取多级 Sketch 特征来指导解码过程 , 如图 e 所示 。
VIRES 的 4 个应用场景:
重绘 , 替换 , 生成与消除
文本指令可以传达一般的视频编辑目标 , 但在用户意图解释方面仍留有相当大的进步空间 。 因此 , 最近的研究引入了额外的引导信息(例如 , 草图)以实现更精确的控制 。
部分现有的方法 , 如 RAVE , 利用 Zero-Shot 的方式 , 将图片编辑模型扩展成视频编辑模型 , 但由于依赖预训练的文本到图像模型 , 该方法在时间一致性上表现不佳 , 不可避免地导致画面闪烁 。
A light orange and white fish swimming in an aquarium
VIRES 通过利用文本到视频模型的生成先验 , 保持了时间一致性并生成了令人满意的结果 。
A light orange and white fish swimming in an aquarium
另外一些方法 , 如 VideoComposer , 在文本到图像模型中引入时间建模层并微调 , 但该方法对组合性的关注限制了编辑视频与提供的 Sketch 序列之间的准确对齐 , 导致细粒度编辑效果不佳 , 如下图所示效果 , 人物衣服的袖子消失 。
A players wears a light green jersey with the white number 1 on the back
VIRES 提出 Sequential ControlNet 和定制的模块来有效处理 Sketch 序列 , 将编辑视频与提供的 Sketch 序列准确对齐 , 实现细粒度编辑 。 效果如下图所示:
【北大施柏鑫团队、贝式计算CVPR研究:视频里轻松换衣服、加柯基】
A players wears a light green jersey with the white number 1 on the back
对于每个视频实例 , 提供重绘的控制条件 , 包括 Sketch 序列、Mask 序列和相应的文本描述 , VIRES 能够生成与条件一致的编辑视频 。
如下所示 , VIRES 有 4 个主要应用场景 , 首先是视频实例重绘 , 例如更换人物身着衣服的材质和颜色;其次是视频实例替换 , 例如将视频中的红色皮卡替换成黑色 SUV 。
第三是定制实例生成 , 如演示视频中在户外雪地增加一只柯基;最后一个场景是指定实例消除 , 例如删除视频中的足球 。
VIRES 在多项指标上超越现有 SOTA 模型
研究团队将 VIRES 与 5 种目前最先进的方法进行了比较 , 包括 Rerender(SIGGRAPH Asia’23) , VidToMe(CVPR’24) , Text2Video-zero(ICCV’23) , RAVE(ICCV’23) , VideoComposer(NeurIPS’24) 。
为了确保详细的比较 , 其不仅在 VireSet 数据集上进行测试 , 还在业内广泛使用的 DAVIS(CVPR’16)数据集上进行了测试 。 实验结果显示 , VIRES 在客观评价指标:视觉感知质量(PSNR)、空间结构一致性(SSIM)、帧运动准确性(WE)、帧间一致性(FC)和文本描述一致性(TC)方面均取得了最佳结果 。
此外 , 团队还进行了两项用户调研 , 其一是视觉质量评估(VQE) , 参与者会看到由 VIRES 和对比编辑方法生成的编辑结果 , 需要选择最具视觉吸引力的视频片段 。 其二是文本对齐评估(TAE) , 给定一个对应的文本描述 , 要求参与者从同一组编辑后的结果中选择最符合该描述的视频片段 。 在用户调研中 , VIRES 均取得了最佳结果 。
VIRES 与 5 种现有方法在外观编辑上的表现对比:
VIRES 与 5 种现有方法在结构编辑上的效果对比:
另外值得一提的是 , 在 Sketch 引导视频生成方面 , VIRES 还支持根据文本描述直接从 Sketch 序列生成完整视频 。 在稀疏帧引导视频编辑方面 , VIRES 支持只提供第一帧的 Sketch 来编辑视频 。 效果如下所示 。
可控视频生成领域的持续探索
总结来看 , VIRES 在草图与文本引导下实现了实例结构一致性 , 而从某种角度来看 , 其也是面向「如何让空间结构信息在视频生成中稳定传递」这一重要挑战 , 给出了一种可靠的解决方案 。 与此同时 , 该研究团队步履不停 , 在突破这一类目标级控制之后 , 还将目光投向了全景级别的可控视频生成 。
该研究团队提出了一种能够以最小改动 , 有效将预训练文本生成视频模型扩展至全景领域的方法 , 并将其命名为 PanoWan 。 该方法采用了纬度感知采样(latitude-aware sampling)以避免纬度方向的图像畸变 , 同时引入旋转语义去噪机制(rotated semantic denoising)和像素级填充解码策略(padded pixel-wise decoding) , 以实现经度边界的无缝过渡 。 实验结果表明 , PanoWan 在全景视频生成任务中的表现达 SOTA 级别 , 并在零样本下游任务中展现出良好的泛化能力 。 相关论文现已发布于 arXiv:https://arxiv.org/abs/2505.22016 。
聚焦该研究团队 , 北京大学相机智能实验室(http://camera.pku.edu.cn) , 负责人施柏鑫 , 北京大学计算机学院视频与视觉技术研究所副所长 , 长聘副教授(研究员)、博士生导师;北京智源学者;北大 - 智平方具身智能联合实验室主任 。 日本东京大学博士 , 麻省理工学院媒体实验室博士后 。 研究方向为计算摄像学与计算机视觉 , 发表论文 200 余篇(包括 TPAMI 论文 30 篇 , 计算机视觉三大顶级会议论文 92 篇) 。 论文获评 IEEE/CVF 计算机视觉与模式识别会议(CVPR)2024 最佳论文亚军(Best Paper Runners-Up)、国际计算摄像会议(ICCP)2015 最佳论文亚军、国际计算机视觉会议(ICCV)2015 最佳论文候选 , 获得日本大川研究助成奖(2021)、中国电子学会青年科学家奖(2024) 。 科技部人工智能重大专项首席科学家 , 国家自然科学基金重点项目负责人 , 国家级青年人才计划入选者 。 担任国际顶级期刊 TPAMI、IJCV 编委 , 顶级会议 CVPR、ICCV、ECCV 领域主席 。 APSIPA 杰出讲者、CCF 杰出会员、IEEE/CSIG 高级会员 。
主要合作者 OpenBayes贝式计算作为国内领先的人工智能服务商 , 深耕工业研究与科研支持领域 , 通过为新一代异构芯片嫁接经典软件生态及机器学习模型 , 进而为工业企业及高校科研机构等提供更加快速、易用的数据科学计算产品 , 其产品已被数十家大型工业场景或头部科研院所采用 。
双方共同在可控视频生成领域的探索已经取得了阶段性成果 , 相信在这一校企合作模式下 , 也将加速推进高质量成果早日落地产业 。
推荐阅读















- 特斯拉推出Robotaxi服务,马斯克:耗时10年 从零开始在公司内部建团队
- 北大教授谈小米自研3nm芯片:带动中国整个芯片行业进步
- 陈立武重整英特尔高管团队 从外部引入多名高管
- 美7000万人或被取代,Agent光速卷入职场,北大校友、杨笛一新作
- 36氪首发|中科院团队创业,全球首款RISC-V DSP芯片再获数千万融资
- 前智源团队创业,联想、智谱AI投了一家人形机器人大模型公司|硬氪首发
- 李飞飞团队DiT设计新思路:不重训直接「嫁接」,质量还提高了
- 中国团队让AI拥有「视觉想象力」,像人类一样脑补画面来思考
- 全面撤离!裁掉中国团队赴越南建研发中心,外媒:美企开始反抗了
- 阿里通义技术大牛再出走,应用视觉团队负责人薄列峰已低调离职