
文章图片
文章图片
本工作来自北京大学智能学院贺笛老师课题组与蚂蚁集团武威团队 。 贺笛老师在机器学习领域获得过多项荣誉 , 包括 ICLR 2023 杰出论文奖与 ICLR 2024 杰出论文奖提名 。
扩散模型近年来在图像生成领域取得了令人瞩目的成就 , 其生成图像的质量和多样性令人惊叹 。 这自然引发了人们的思考:这种强大的生成范式能否迁移到文本领域 , 挑战甚至取代目前主流的自回归语言模型?扩散语言模型(Diffusion Language Models)凭借其并行生成多个词元的潜力 , 似乎预示着文本生成领域的一场效率革命 。 然而 , 这一前景是否真的如此美好?来自北京大学和蚂蚁集团的最新研究表明 , 答案远非简单的 “是” 或 “否” , 在某些关键场景下 , 结论甚至可能恰恰相反 。
- 论文标题:Theoretical Benefit and Limitation of Diffusion Language Model
- 论文链接:https://arxiv.org/pdf/2502.09622
扩散模型 vs. 自回归:效率神话面临拷问
自回归模型 , 作为语言生成领域的主流范式 , 以其逐词元(token-by-token)的顺序生成方式著称 。 尽管在生成质量上取得了巨大成功 , 但其固有的串行机制限制了推理速度 , 尤其是在处理长序列时 。 与之相对 , 扩散语言模型 , 特别是其中的掩码扩散模型(Masked Diffusion Models MDMs) , 允许在每个扩散步骤中并行采样多个词元 , 这从理论上为提升生成效率提供了可能 。
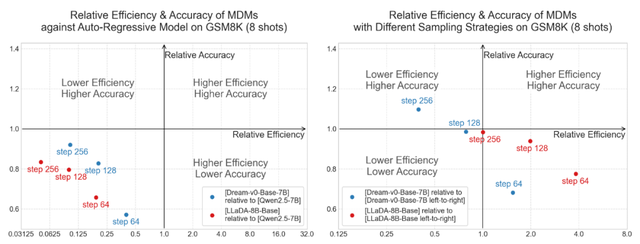
然而 , 理论上的优势在实践中似乎遭遇了 “效率悖论” 。 研究人员观察到 , 目前开源的扩散语言模型在某些任务上需要更多的采样步骤才能达到与自回归模型相当的准确率 , 导致了比自回归模型更高的推理成本 。 这一悖论在实验中得到了印证 。 下图直观展示了这一现象:在数学推理基准测试 GSM8K(8-shot)上 , 当与同等规模的自回归模型 Qwen2.5-7B 对比时 , 两款最近发布的大型掩码扩散模型 Dream-v0-7B 和 LLaDA-8B , 在不同的采样步数下 , 其性能和效率均落后于自回归基线 , 处于左图中的第三象限(代表更低效率和更低性能) 。
鉴于不同模型可能使用了不同的训练数据 , 研究人员意识到这可能对性能评估造成天然偏差 。 为消除该因素带来的影响 , 团队设计了更加客观、公平的对比实验:给定一个预训练好的扩散语言模型 , 我们强制约束其在推理中采用从左到右的逐词生成方式 , 并以这种\"伪自回归式\"的解码性能与效率作为基线 , 重新进行对比分析 。 理论上 , 在消除训练数据差异的前提下 , 相对这种伪自回归式的解码方式 , 扩散语言模型理应在效率与性能之间取得更优平衡 , 表现应进入第一象限 。 然而 , 实验结果却出人意料 —— 即使与这种被约束的模型对比 , 扩散语言模型仍未展现出任何优势 , 未能同时实现更高的生成效率与更优的输出质量 。
图 1:MDMs 在 GSM8K (8-shot) 上的效率和准确率 。 (左) MDMs 相对于 Qwen2.5-7B 的表现 。 (右) MDMs 相对于其自身自回归式解码的表现 。
这些观察结果引出了一个核心问题:“离散扩散模型是否真的能提供比自回归模型更好的权衡 , 即在保持高质量生成内容的同时实现更高的效率?” 这正是这项新研究试图解答的关键 。
北大团队新研究:拨开迷雾 , 关键在评估指标
针对上述疑问 , 研究团队对此进行了深入的理论剖析 。 他们的研究目标是 “对一种广泛采用的变体 —— 掩码扩散模型(MDM)进行严格的理论分析” , 以探究观测到的效率限制是否是其固有的缺陷 。
这项研究的核心结论是 , 关于扩散模型与自回归模型优劣的 “结论高度依赖于评估指标的选择” 。 研究团队采用了两种互补的评估指标来全面衡量 MDM 的性能:
词元错误率(TER):该指标量化了词元级别的准确性 , 通常与生成文本的流畅度相关 。 在实践中 , 困惑度(Perplexity)是衡量语言模型词元级别错误的常用指标 , 因此论文中 TER 由困惑度定义 。 较低的 TER 通常意味着模型能生成更流畅、连贯的文本 。
序列错误率(SER):该指标评估整个序列的正确性 , 这对于需要逻辑上完全正确的序列的推理任务(如解决数学问题、代码生成)至关重要 。
研究团队首先分析了扩散语言模型以词元错误率(TER)为主要衡量标准时的效率 , 即评估的重点在于生成文本的流畅度和连贯性 。 研究团队证明目标是接近最优的困惑度时 , MDM 可以在与序列长度无关的恒定采样步数内实现这一目标 。 换而言之 , 为了达到理想的困惑度 , MDM 所需的采样步数并不随序列长度的增加而增长 , 而是一个常数 。 这与自回归模型形成了鲜明对比 , 后者必须执行序列长度的次数才能生成整个序列 。 因此 , 在生成长篇流畅文本等任务中 , MDM 具备显著的效率提升潜力 。
这一定程度上解释了为何 MDM 在 GSM8K 这类数学推理基准测试中表现不佳(如图 1 所示) 。 数学推理要求思维链条的每一步都完美正确 。 SER 与 MDM 解决数学问题的准确性密切相关 , 因为错误的思维链通常会导致错误的答案 。 因此 , MDM 难以在这类数学推理任务上取得效率优势 , 从而解释了观察到的实验现象 。
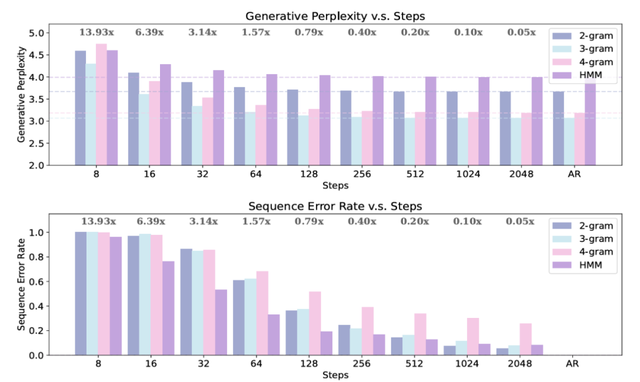
除了理论分析 , 研究团队又进一步在一些形式语言上验证了这些理论结果 , 如下图 2 所示 。 这些实验结果再一次证明 , 当考虑词元级别的错误率时 , MDM 能够展现出效率优势 , 然而当使用序列级别错误率作为衡量指标时 , MDM 则不如 AR 模型高效 。
图 2:MDMs 在形式语言上的表现 。 (上) MDMs 的困惑度与采样步数的关系 。 (右) MDMs 序列错误率与采样步数的关系 。
结论:扩散语言模型 , 何时才是更优?。 ?
那么 , 回到最初的问题:扩散语言模型真的会比自回归模型更好吗?这项研究给出的答案是:视情况而定 , 关键在于用什么样的指标去衡量 。基于这项研究的理论分析和实验结果 , 我们可以为实践者提供以下的指导方针。
当任务优先考虑生成文本的流畅性、高吞吐量 , 并且能够容忍一定程度的序列级别不完美时 , 例如:长篇幅的创意写作 , 其中整体的可读性和连贯性比每一句话的绝对事实准确性更重要 , 在这些场景下 , 扩散语言模型能够展现出效率的优势 。 然而 , 当任务对序列级别的准确性和逻辑正确性有极高要求时 , 扩散语言模型为达到低 SER 所需的采样步数随序列长度线性增长 , 这抵消了其潜在的并行效率优势 , 甚至可能因单步计算成本更高而变得更慢 。 此时 , 自回归模型是更好的选择 。
这项研究为理解 MDM 的比较优势和局限性奠定了首个坚实的理论基础 。 当然 , 研究团队也指出了当前工作的一些局限性 , 例如分析主要集中在形式语言上 , 未来需要将其扩展到更复杂的现代大语言模型;同时 , 分析主要针对掩码扩散模型 , 其他类型的扩散模型的表现仍有待探索 。
【扩散语言模型真的会比自回归好?理论分析结果可能恰恰相反】总而言之 , 扩散技术在图像生成领域的巨大成功 , 并不意味着其优势可以直接、简单地平移到语言领域 。 语言的离散性和序列性带来了独特的挑战 , 需要更细致和针对性的评估 。 这项研究以其严谨的理论和清晰的实验 , 为我们揭示了扩散语言模型在效率与质量权衡上的复杂性 , 为整个领域的发展注入了重要的理性思考 。 对于追求特定目标的模型部署而言 , 理解这种权衡对于成本控制和用户体验都至关重要 , 错误的选择可能导致用户体验不佳或不必要的计算资源浪费 。 最终 , 没有绝对 “最好” 的模型 , 只有最适合特定任务和特定评估标准的模型 。
推荐阅读












- AI模型的耗电量惊人 下一步是建设太空数据中心?
- 大模型「躲在洞穴里」观察世界?强化学习大佬吹哨提醒LLM致命缺点
- 苹果WWDC掀AI重构风暴!端侧模型全开放、AI版Siri却成最大鸽王
- SSM+扩散模型,竟造出一种全新的「视频世界模型」
- 大模型智能体如何突破规模化应用瓶颈,核心在于Agentic ROI
- 传统符号语言传递知识太低效?探索LLM高效参数迁移可行性
- 最新发现!每参数3.6比特,语言模型最多能记住这么多
- 多模态扩散模型开始爆发,这次是高速可控还能学习推理的LaViDa
- 刷新世界记录,40B模型+20万亿token,散户组团挑战算力霸权
- 美国人又来搞事,“华为式”的制裁又要扩散了?