
文章图片
文章图片

文章图片

文章图片
论文第一作者谭宇乔来自中国科学院自动化研究所的自然语言处理和知识工程研究组 , 导师为何世柱老师 。 目前研究方向主要在利用大语言模型参数知识增强大模型能力 。
1 跨规模参数知识迁移 PKT 的全面分析
【传统符号语言传递知识太低效?探索LLM高效参数迁移可行性】人类的思维是非透明的 , 没有继承的记忆 , 因此需要通过语言交流的环境来学习 。 人类的知识传递长期依赖符号语言:从文字、数学公式到编程代码 , 我们通过符号系统将知识编码、解码 。 但这种方式存在天然瓶颈 , 比如信息冗余、效率低下等 。
现如今 , 大语言模型(LLM)就主要模仿这一套范式来学习和传递知识 。 然而 , 与人脑不可知和不透明的特性不同 , 开源 LLM 的可访问参数和信息流则像一个透明的大脑 , 直接编码了事实知识 , 已有的研究对其进行了系统分析、精确定位和有效转移 。 因此研究人员提出疑问:大模型能否像《阿凡达》中的人类和纳威人之间建立传递知识的练习?其中在天然存在的较大 LLM 和较小 LLM 对之间展开 , 将参数知识作为媒介 。
最近 , 中国科学院自动化所提出对 Parametric Knowledge Transfer (PKT , 参数知识迁移) 的全面分析 。 一句话总结:跨规模大模型之间的表现相似和参数结构相似度都极低 , 这对实现有效的 PKT 提出了极大的挑战 。
- 论文标题:Neural Incompatibility: The Unbridgeable Gap of Cross-Scale Parametric Knowledge Transfer in Large Language Models
- 论文地址:https://arxiv.org/abs/2505.14436
- Github 地址:https://github.com/Trae1ounG/Neural_Incompatibility
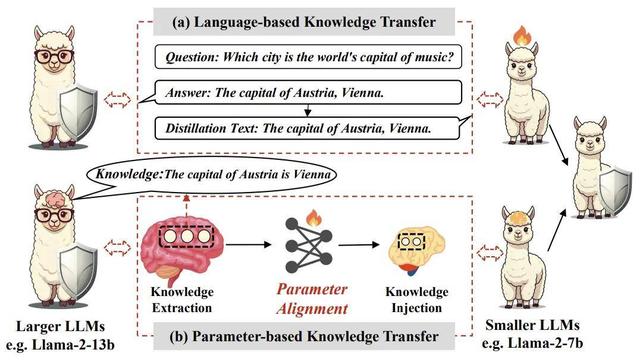
论文首先通过简单的前置实验 , 挖掘出参数空间的对齐是实现参数知识迁移的必要条件 。 现有的参数对齐方法 Seeking 通过梯度定位部分较大 LLM 参数以适配较小 LLM 张量形状 , 将其初始化为 LoRA 矩阵通过后续微调实现迁移 , 称之为后对齐参数迁移方法(Post-Align PKT) 。 论文为了更全面探索 PKT 是否可行 , 根据对齐时机提出先对齐知识迁移(Pre-Align PKT)新范式 , 采用定位后对齐(Locate-then-Align , LaTen)方法实现参数对齐 。
图表 1:展示了基于语言的知识迁移和基于参数的知识迁移范式的差异
该方法的核心理念是首先通过神经元级别的归因分析 , 识别出与特定任务相关的参数 , 然后利用训练得当的超网络 , 将较大 LLM 的知识映射到较小 LLM 上 。
具体而言 , LaTen 方法分为两个阶段:
- 知识提?。 和ü治龃竽P偷牟问?, 识别出与目标任务相关的知识 。 这一过程利用静态神经元归因方法 , 计算出每个神经元在任务中的重要性 , 从而选择出最具信息量的参数进行迁移 。
- 参数对齐:一旦确定了重要参数 , 接下来通过轻量级的超网络进行对齐 , 确保这些参数能够有效整合到小型模型中 。
- 参数注入:这一过程强调在对齐后直接注入参数 , 减少了后续训练所需的资源和时间 。
3 对齐实验分析
在实验部分 , 研究者针对多个基准数据集 , 涵盖世界知识(MMLU) , 数学推理(GSM8K)和代码能力(HumanEval 和 MBPP)进行了详细评估 。
图表 2:展示 Post-Align PKT 和 Pre-Align PKT 在不同数据集上的性能表现
实验结论:
- 对于 Post-Align PKT , 论文将其同利用 SVD 从模型自身获取 LoRA 的 PiSSA 方法对比 , 结果发现 PiSSA 在相同设置下优于 Seeking , 证明从较大模型抽取的参数知识不如利用模型自身知识作为 LoRA 初始化 , 进一步怀疑其可行性 。
- 对于 Pre-Align PKT , 结果显示 , 只需要极少的训练步数和数据开销 , LaTen 能有效取得性能提升 。 但是 Pre-Align PKT 通过训练实现参数对齐的方式受到极大限制 , 无法超越较大 LLM 的能力上界 , 同时训练不太稳定 , 没有明显收敛 。
图表 3:基于更强的较大 LLM 向较小 LLM 传递知识 , 左图为 Post-Aligh PKT 实验结果 , 右图为 Pre-Align PKT 实验结果
实验结果证明了两种 PKT 在这种设置下的失败 , 让人疑惑为什么跨规模 PKT 无法有效实现?
4 为什么跨规模 PKT 失败?
PKT 的核心任务在于对齐(Align) , 不管是通过后续训练还是提前通过超网络实现 , 是否能有效实现对齐是 PKT 成功的关键 。 从现有实验结果来看 , PKT 并没有有效实现对齐 , 那么阻碍的关键在哪?
论文从表现相似度(representation similarity)和参数相似度(parametric similarity)出发 , 分析跨规模大模型在行为方式和内部参数结构的相似度是否会导致跨规模 PKT 的失败 , 称为神经不兼容性(Neuron Incompatibility) 。
图表 4:跨规模大模型之间的表现相似度分析
对于表现相似度的分析 , 论文采用了中心核对齐(Centered Kernel Alignment CKA)方法 , 该方法基于 Hilbert-Schmidt 独立性准则(HSIC) , 用于计算神经网络中特征表示的相似性 。 该指标评估了两个模型之间行为的相似性 , 可以视为大语言模型的行为相似性 。
如图 4 所示 , Llama2-7B 和 13B 之间的相似性较低 , 尤其是在多头自注意力(MHSA)模块中 , 该模块在信息整合中扮演着至关重要的角色 。 有趣的是 , 上投影层的相似性较高 , 这可能是因为它们作为关键记忆 , 捕捉特定的输入模式 , 而这些模式通常在不同模型间是一致的 。 跨规模大模型之间的低相似性也解释了为何从同一模型衍生的 LoRA 表现更好 , 因为它与模型的内在行为更为贴合 。 证明跨规模大语言模型之间的表示相似性较弱是导致神经不兼容性的关键因素之一 , 这使得理想的参数知识转移成功变得困难 。
5 总结与展望:理想的 PKT 尚待实现
人类从牙牙学语到学贯古今 , 通过语言和文字在历史长河中不断汲取知识 , 通过吸收和迭代实现知识的传承 。
然而 , 我常幻想能实现 , 类似科幻小说中三体人直接通过脑电波传递所有知识 , 或利用一张链接床就能把人类的意识输入到纳威人体内 , 这是一种更理想的知识传递方式 , 而开放的大模型参数正有可能实现这一点 。
通过将 PKT 根据 Align 进行划分 , 我们完成了对现有阶段 PKT 的全面研究 , 找出了实验结果欠佳的背后是不同规模大模型之间参数知识本质上的行为和结构的差异 。
但仍期望 , 在未来大模型之间的交流不再局限于语言这种有损的压缩方式 , 而去尝试更高效直接的迁移方法 。
语言 , 或许是人类知识的起点 , 但不一定是大模型的终点 。
推荐阅读
















- 最新发现!每参数3.6比特,语言模型最多能记住这么多
- 实测 8 种编程语言内存消耗:选对语言能省一半服务器成本!
- 小米汽车从传统车厂挖来的高管文飞离职,出任奇瑞汽车副总裁
- 抛开传统固化思维,索尼、佳能、尼康三家微单相机优劣之分与选择
- C++创始人:需要改变的不是语言,而是开发者的思维方式!
- 中国造出无CPU计算机
- Meta、Cisco 将开源大语言模型置于下一代 SOC 工作流核心
- REDMITurbo4Pro:彻底颠覆了人们对千元机的传统认知!
- 海豚语言被谷歌模型破译!实现跨物种交流,哈萨比斯:下一个是狗
- 雷军宣布小米SU7产能翻倍!传统车企高管集体沉默,网友:狼来了