Claude不让我们用!国产平替能顶上吗?

文章图片

文章图片
文章图片

文章图片

文章图片
机器之心报道
作者:冷猫、杜伟
这几天 , 全球 AI 代码生成的竞争格局 , 迎来了新的拐点 。
【Claude不让我们用!国产平替能顶上吗?】在编程领域 , 曾被视为王者的 Anthropic , 似乎正在一步步失去昔日的锋芒 , 地位开始动摇 。
这一方面源于 OpenAI GPT-5 系列模型的强势崛起 , 在与 Claude Code 的对战中大有「后来者居上」之势 , AI 大神 Karpathy 现身说法并开始安利 GPT-5 Pro 的强大代码能力 。
另一方面则是 Anthropic 自身的一系列迷之操作 , 先是放任并承认自家模型(包括 Claude Opus 4.1 和 Opus 4)降智 , 本周又宣布向包括中国在内的部分地区限制其 AI 产品和服务的使用 。
在这个微妙的时间节点 , 多家国产大模型厂商向 Anthropic 发起了一波正面狙击 。 月之暗面发布了 Kimi-K2-0905 版本、阿里发布了超万亿参数的 Qwen3-Max-Preview 。
前者作为 Kimi-K2 系列模型的最新版本 , 将上下文长度扩展到了 256k , 针对前端开发等实际编程任务做了优化 , 长代码生成中的正确性、稳定性和逻辑一致性较以往版本有了提升 。 后者是阿里迄今最大的模型 , 同样提升了通用知识、数学推理、编程等多种任务的表现 。
可以看到 , 国产大模型厂商近来集中在代码生成任务上发力 。 Kimi-K2-0905 强调了工具调用能力 , 并提升了模型与 Agent 框架(如 Roo Code)的集成性 。
在使用该模型调用外部工具时 , 格式正确率现在可以达到 100% , 不再需求人工修正 。 它还完全兼容 Anthropic API , 方便接入与迁移 。 对 WebSearch Tool 的支持 , 可以通过实时信息检索提升任务效果 。
随着 0905 版本的发布 , 近 30 天 Kimi-K2 系列模型在 Hugging Face 中的下载量超过了 39 万 。
对于最新的 Kimi-K2-0905 , 有人直言「终于不用再为处理复杂的长任务而感到挫败了 。 」
此消彼长 , 随着国产大模型在代码生成领域持续发力 , 全球竞争的格局也许真的要变一变了 。
能力、价格双优势 , 让国产大模型更能打
作为 Kimi K2 系列中最新的版本 , Kimi-K2-0905 与其他国产大模型厂商的新模型(如 Qwen3-Max-Preview)一样 , 向曾经的王者 Claude 的传统优势区间发起挑战 , 强调智能编程领域的性能提升 。
从技术细节上来看 , Kimi-K2-0905 沿用了目前主流的 MoE 架构 , 参数规模为万亿级别 , 在推理时实际被激活的参数为 320 亿 。
参数概览
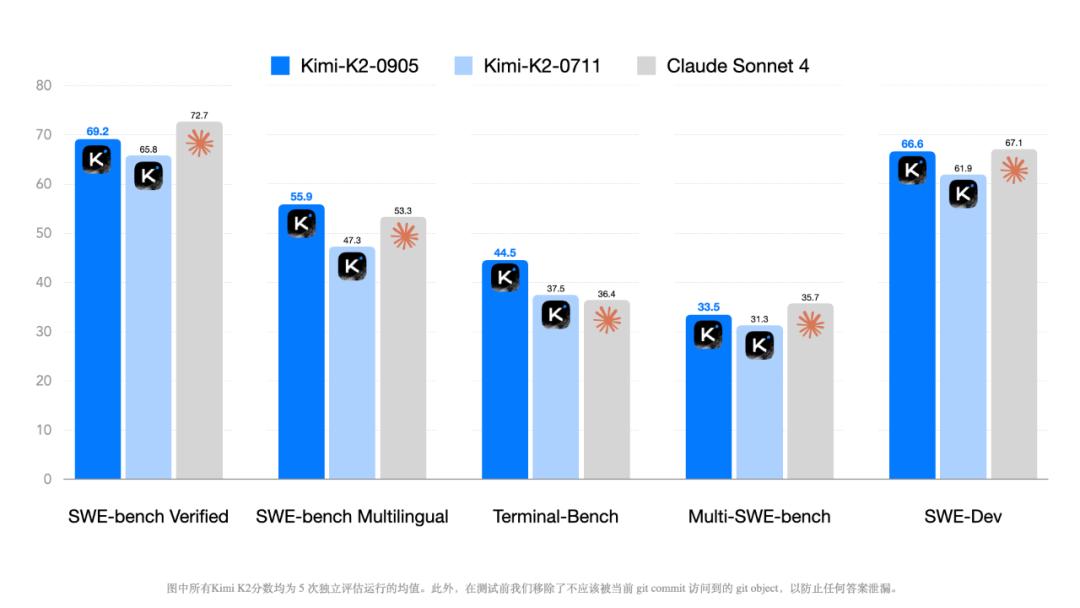
从该模型与 Claude Sonnet 4 在 SWE-bench Verified 等真实编程基准的对比中发现 , Kimi-K2-0905 在部分测试中(如多语言环境、命令行 / 终端交互)甚至超过了这个竞争对手 。
实战表现究竟如何?我们用它做了个经典小游戏 。
指令很简单:「制作一个和微信打飞机类似的网页小游戏 , 需要美观 , 好玩 , 功能齐全 。 」
Kimi-K2-0905 生成游戏代码(部分截图)
在网页端实现的效果堪称惊艳 , 不仅实现了浩瀚星空的背景 , 高速移动的拖影 , 概率出现的回血道具 , 还有不同颜色的敌人爆炸效果 , 甚至玩得好的话还有连击加分 。
我们试着玩了好一会儿 , 困难模式真的挺难的 。
根据知名博主「karminski - 牙医」的测试 , Kimi-K2-0905 前端水平有了显著的提升 , 空间理解能力和召回能力都有所增强 。
在需要生成超过一千行代码的「鞭炮连锁爆炸测试」中 , Kimi-K2-0905 表现优秀 。
原贴地址:https://x.com/karminski3/status/1963834619276709933?s=46
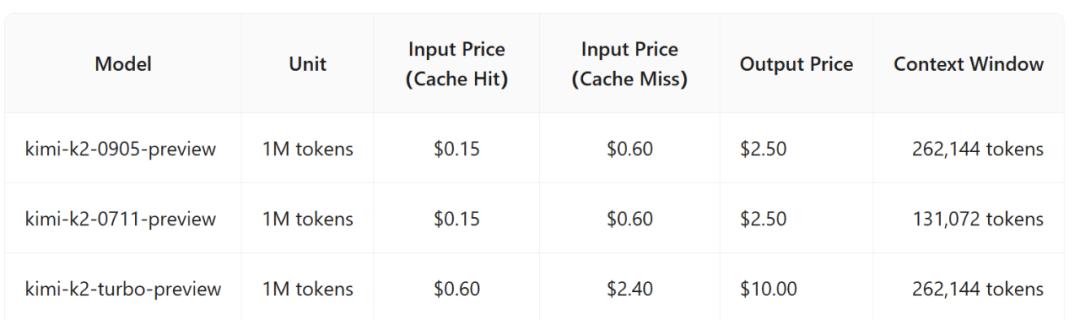
Kimi-K2-0905 此次还在 API 定价上打出了竞争性优势 。
据我们了解 , Kimi 开放平台上架的 kimi-k2-0905-preview 模型 API , 定价与上一代一致 , 计费方案为缓存未命中时每百万输入 tokens/4 元 , 缓存命中时每百万输入 tokens/1 元 , 每百万输出 tokens/16 元 。 详细的定价策略参考下图:
以美元计价的价格与国内价格比较接近 。
相较于 Anthropic 堪称夸张的定价 , Kimi 等国产编程模型称得上是「开源 Claude 平替」 , 并且能够实现全方位兼容 Anthropic API 和 Claude Code , 延续开发者曾经的使用习惯 。
尤其是在 Anthropic 对国内和其他地区「断供」的大背景下 , 让现有项目和工作流平稳落地的重要性不言而喻 。
结语
在 AI 编程领域 , 国内的 AI 厂商都有自己的理解 。 大概分为两个方向 , 一部分厂商在产品和用户体验侧发力;另一部分则是打磨基础模型 。
例如腾讯和字节对自家编码产品的更新主要集中在产品侧 , 字节更新 Trae Solo 版本、腾讯发布 CodeBuddy IDE 等等 , 都是试图超越 Cursor 核心竞争力的尝试 。
与之对应 , 以月之暗面为代表的 AI 新势力 , 选择了一条更为直接的发展道路:通过技术创新与极限性能打磨 , 力求在大模型核心能力上与国际一线厂商(如 Anthropic)一较高低 。
无论是上下文窗口的持续扩展 , 还是针对真实编程任务、Agent 工具调用等的专门优化 , 国内玩家正在取得逼近甚至超越海外同类产品的表现 。
同时 , 主流 AI 编程工具 , 如 Cursor、Windsurf、Trae、Cline 等 , 以及第三方 Agent 产品 , 如 flowith 和 Genspark 等 , 也都在主动接入国内优秀的大模型 , 中国 AI 新势力已深度融入主流开发与应用生态 。
如今 , 国产大模型不仅能在性能参数上赶超国际领先者 , 也能在实际开发体验上获得更多认可 。 这样的「正反馈循环」一旦形成 , 则有望快速积累开发者口碑 , 创建更繁荣的应用生态 , 进一步撬动更广阔的市场 。
推荐阅读












- 突发!Anthropic “封杀”中国控股公司,禁止其使用Claude等AI服务
- 中国控股企业使用Claude遭禁 智谱:推出“搬家计划”
- 为什么我们的家的宽带越用越憋屈?
- 直指2nm 要领先中国!印度:我们正在研制世界上最先进的芯片
- 华为郭平:鸿蒙是我们不得不打的一场“战争”
- 最后通牒!Claude聊天/代码默认全喂AI训练,你的隐私能被用5年
- Anthropic推出实验性Claude AI插件可控制Chrome浏览器
- 手机直连卫星业务加速普及 会给我们带来哪些便利?
- OpenAI和Anthropic罕见互评模型:Claude幻觉明显要低
- 剖析苹果邀请函后,我们发现了些没人聊过的新功能