文章图片

文章图片

文章图片

文章图片
文章图片

文章图片
编辑:元宇 好困
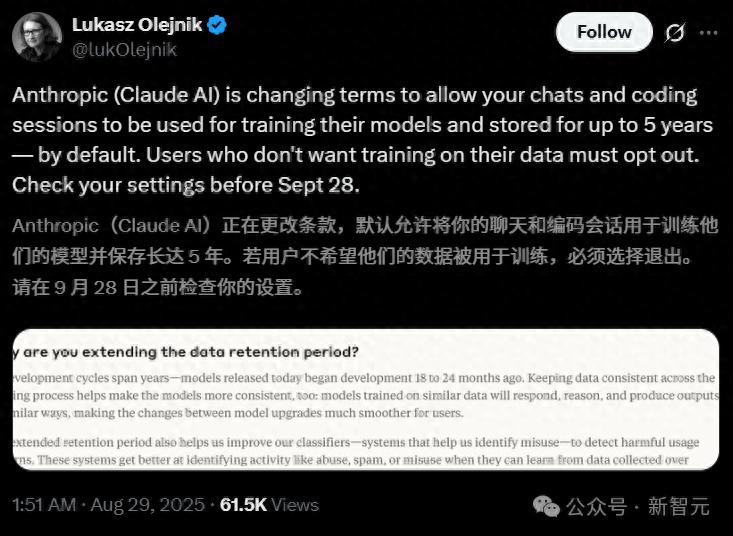
【新智元导读】近日 , Anthropic更新了它的消费者条款 , 没想竟把网友惹怒了 , 有的还把以往的「旧账」都翻了出来 。 这次网友的反应为啥这么激烈?大家可能还记得在Claude上线之初 , Anthropic就坚决表示不会拿用户数据来训练模型 。 这次变化不仅自己打脸 , 还把以往一些「背刺」用户的往事都抖搂出来了 。
近日 , Anthropic的一项关于消费者条款的更新政策 , 把网友惹怒了 。
在这次条款更新中 , Anthropic一改往日坚决不使用用户数据来训练模型的承诺 , 让现有用户二选一:是否接受自己的数据被用于模型训练 。
表面上 , Anthropic是把「选择权」交给了用户 , 但只留了一个月的期限 。
Claude的新用户 , 自然是要在注册时做出选择的;现有用户 , 必须在9月28日前作出决定:
- 9月28日之前 , 如选择接受便立刻生效 。 这些更新仅适用于新的或重新开始的聊天和编程会话 。
- 9月28日之后 , 必须在模型训练设置中做出选择 , 才能继续使用 Claude 。
- 如果用户选择将数据用于模型训练 , 数据保留期将被延长到5年 。 用户删除与Claude的对话时 , 该对话将不会用于未来的模型训练;
- 如果用户未选择加入模型训练 , 公司现行的30天数据保留期仍然适用 。
而使用Claude Gov、Claude for Work、Claude for Education , 或通过API接入的商业客户则不受影响 。
对于Anthropic的这种做法 , 网友们纷纷怒斥离谱!
不仅是政策 , 就连界面的UI , 也被设计成了那种一不小心就会上套的类型 。
这种所谓的「文字游戏」 , 早年间在电脑上装过软件的朋友 , 想必都不会陌生 。
而且 , Anthropic的奇葩操作还不止这些 。
网友「Ahmad」就在自己的推文里 , 盘点了一波Anthropic迄今为止的「背刺」行为:
- 所有对话和代码都保留5年 , 而且全部要拿去训练模型
- 白天偷偷给用户换成1.58 bit的「缩水版」量化模型
- Plus会员在Claude Code里用不了最强的Opus 4模型
- 6周前 , Max套餐的用量限制被直接砍半 , 而且没有任何通知
- 每周的用量限制到底是多少 , 从来不说具体数字
- 宣传的5倍/20倍用量套餐 , 实际给的量只有Plus套餐的3倍/8倍
- 胡乱发DMCA通知 , 下架了许多跟Claude Code相关的代码仓库 , 我自己的一个项目也因此遭殃
- Windsurf用户无法使用Claude 4
- 切断了对OpenAI API的访问权限
用户数据 , 是大厂「金矿」
在Anthropic那篇关于此次政策更新的博客中 ,它将变化包装成用户具有选择权的样子 , 声称:
用户如果不选择退出 , 将帮助我们提升模型安全性 , 使我们检测有害内容的系统更准确 , 并减少标记无害对话的可能性 。
而且 , 这些接受了新政策的用户 , 用Anthropic的话说:
这将帮助未来的Claude模型提升编码、分析和推理等技能 , 最终为所有用户带来更好的模型 。
这套冠冕堂皇的说辞背后 , 真相远非如此简单 。
而且 , 从整个行业看 , Anthropic的此次消费者条款更新 , 也并非孤例 。
大模型只有在接受更多真实用户数据训练后 , 才会变得更聪明 。 因此 , 各家大模型公司 , 也总是在如何争取用户数据 , 以改进其模型上大伤脑筋 。
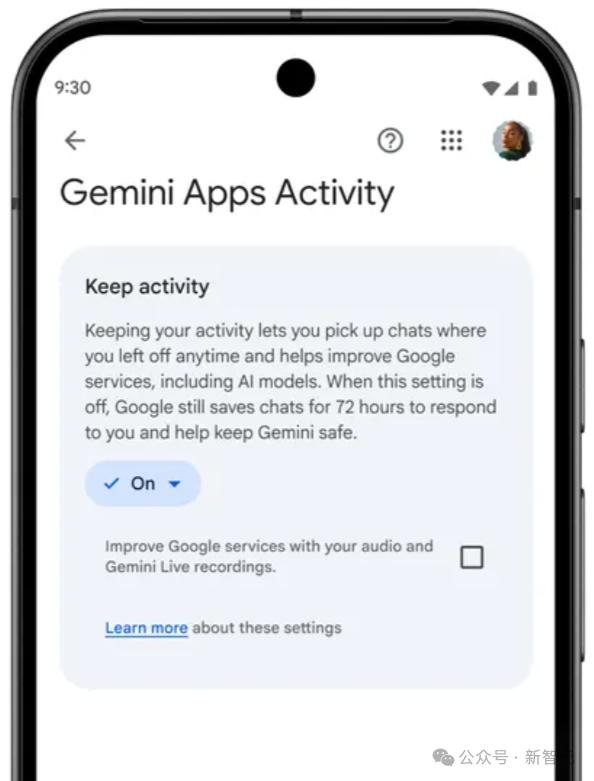
比如 , 谷歌最近也做了类似调整 , 将「Gemini Apps Activity」重命名为「Keep Activity」 。 谷歌称 , 当该设置开启时 , 自9月2日起 , 用户的部分上传样本将用于「帮助为所有人改进谷歌服务」 。
和谷歌、OpenAI等所有其他大模型公司一样 , Anthropic对数据的渴求 , 同样也远胜于它对于维护用户品牌好感度的需求 。
能够访问数百万次Claude用户的交互 , 能为Anthropic提供更多来自真实编程场景的语料 , 从而提升其大模型相对于OpenAI、谷歌等竞争对手的优势地位 。
所以 , 不难想象 , Anthropic此次条款更新的真实用意 , 恐怕还是直指用户数据背后的「金矿」 。
Anthropic「背刺」惹众怒
以往 , Anthropic对用户最大的一个吸引力 , 在于它承诺对消费者数据隐私的严格重视 。
从Claude上线之初 , Anthropic就坚决表示不使用用户数据来训练模型 。
此前 , Anthropic的消费级产品的用户被告知 , 他们的提示词和对话内容会在30天内从公司后端自动删除——除非「法律或政策要求保留更长时间」 , 或者其输入内容被标记为违规(在这种情况下 , 用户的输入和输出最多可能被保留两年) 。
而现在 , Anthropic要求新用户和现有用户 , 必须在是否同意其使用他们的数据训练模型上 , 做出选择 。
而且还规定现有用户必须在一个月内作出决定 。 此外 , 还把用户数据的保留期 , 延长到了5年 。
这些可能被用来训练模型的用户数据包括:
整个相关对话 , 以及任何内容、自定义风格或会话偏好 , 以及使用Claude for Chrome时收集的数据 。
这些数据 , 不包括来自连接器(例如Google Drive)的原始内容 , 或远程和本地MCP服务器 , 但如果它们是被直接复制到你与Claude的对话中 , 则可能会被包含 。
谁来保护用户隐私?
这些大厂在「悄悄」改变政策 , 谁来保护用户隐私?
它们不断变化的政策 , 也为用户带来了巨大的困惑 。
而且 , 这些公司在政策更新时 , 也似乎会刻意淡化这一点 。
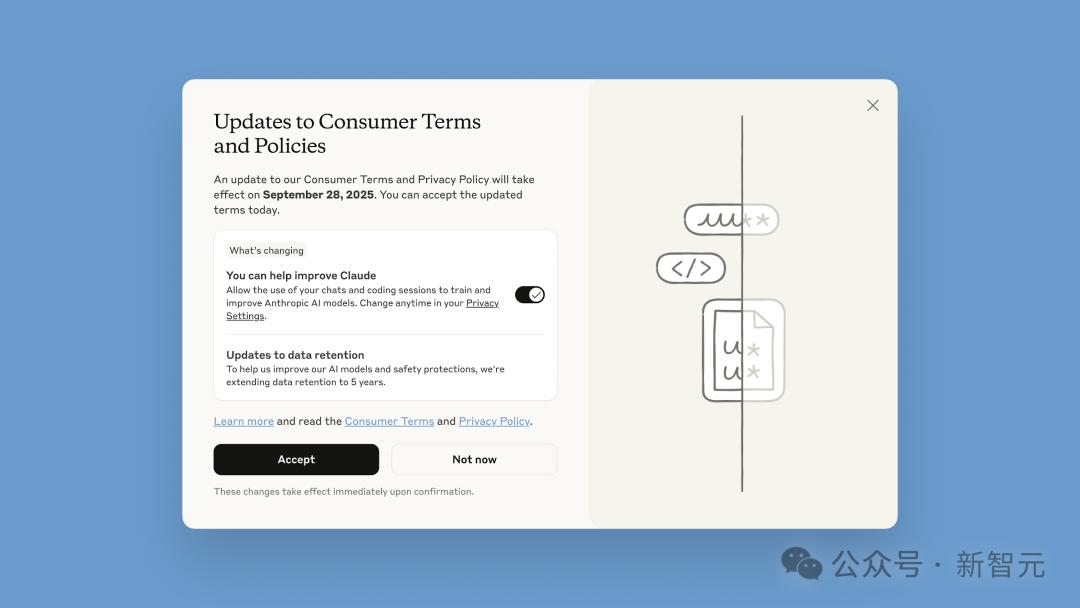
以Anthropic的这次更新界面为例 。
现有用户在面临政策更新弹窗时 , 首先映入眼帘的是一行大号字体标题——「消费者条款和政策更新」 , 左侧是一个显眼的黑色「接受」按钮 , 按钮下方则是一行小字和一个更小的切换开关 , 用于授予训练许可——而且这个开关默认就设置在「开启」位置 。
这种设计引发了一些普遍的担忧:
很多用户 , 很可能在没有注意到自己同意了数据共享的情况下 , 就迅速点击了「接受」 。
Anthropic政策的调整 , 似乎也反映了整个行业在数据政策上的普遍转变 。
观察国外AI行业 , 诸如Anthropic、OpenAI、谷歌这样AI大厂 , 正因其数据保留的做法 , 而面临日益严格的审视 。
比如 , 近日 , 为了应对《纽约时报》的版权诉讼 , OpenAI首次公开承认自5月中旬以来 , 一直在悄悄保存1用户已删除和临时的聊天记录 。
事件曝光后 , 网友们都惊了:
合着那些被删掉的ChatGPT聊天记录 , 都被你存了档 , 然后等着法官来查?
再回到此次Anthropic更改消费条款这件事上 , 背后折射出公众对于AI隐私的日益关注和担忧 。
当「用户数据」成为大模型竞争的关键性因素 , 如何在保持模型竞争优势的同时 , 保护好用户数据隐私 , 成了所有大模型厂商必须应对的一项重要挑战 。
参考资料:
https://www.zdnet.com/article/anthropic-will-start-training-claude-on-user-data-but-you-dont-have-to-share-yours/%20%20
https://www.theverge.com/anthropic/767507/anthropic-user-data-consumers-ai-models-training-privacy%20%20
【最后通牒!Claude聊天/代码默认全喂AI训练,你的隐私能被用5年】https://www.businessinsider.com/anthropic-uses-chats-train-claude-opt-out-data-privacy-2025-8%20%20
推荐阅读










- Anthropic推出实验性Claude AI插件可控制Chrome浏览器
- ChatGPT后遗症来了,人类日常聊天越来越AI化
- OpenAI和Anthropic罕见互评模型:Claude幻觉明显要低
- 「开发者私下更喜欢用GPT-5写代码」,Claude还坐得稳编程王座吗
- 红杉资本押注的新赛道,要“入侵”你的聊天机器人
- 为见AI「女友」,76岁老人命丧途中!Meta聊天机器人酿成惨剧
- 为见AI「女友」,76岁老人命丧途中,Meta聊天机器人酿成惨剧
- 研究揭示大语言模型聊天机器人易被恶意利用窃取用户隐私数据
- DeepSeek V3.1 Base突袭上线,击败Claude 4编程爆表,全网在蹲R2和V4
- 突破Claude-4编程上限!自进化Agent框架拿下新SOTA,已开源