DeepSeek V3.1 Base突袭上线,击败Claude 4编程爆表,全网在蹲R2和V4

文章图片

文章图片
文章图片

文章图片

文章图片
【DeepSeek V3.1 Base突袭上线,击败Claude 4编程爆表,全网在蹲R2和V4】
文章图片

文章图片

文章图片

文章图片
文章图片

文章图片

文章图片

就在昨晚 , DeepSeek官方悄然上线了全新的V3.1版本 , 上下文长度拓展到128k 。
本次开源的V3.1模型拥有685B参数 , 支持多种精度格式 , 从BF16到FP8 。
综合公开信息和国内大咖karminski3的实测 , V3.1此次更新亮点有:
编程能力:表现突出 , 根据社区使用Aider测试数据 , V3.1在开源模型中霸榜 。
性能突破:V3.1在Aider编程基准测试中取得71.6%高分 , 超越Claude Opus 4 , 同时推理和响应速度更快 。
原生搜索:新增了原生「search token」的支持 , 这意味着搜索的支持更好 。
架构创新:线上模型去除「R1」标识 , 分析称DeepSeek未来有望采用「混合架构」 。
成本优势:每次完整编程任务仅需1.01美元 , 成本仅为专有系统的六十分之一 。
值得一提的是 , 官方群中强调拓展至128K上下文 , 此前V3版本就已经支持 。
对于这波更新 , 大家的热情可谓是相当高涨 。
即便还未公布模型卡 , DeepSeek V3.1就已经在Hugging Face的趋势榜上排到了第四 。
DeepSeek粉丝数已破8万
看到这里 , 网友们更期待R2的发布了!
混合推理 , 编程击败Claude 4这次最明显的变化是 , DeepSeek在官方APP和网页端上 , 把深度思考(R1)中的「R1」去掉了 。
同时 , 与V3-base相比 , DeepSeek V3.1新增了四个特殊Token:
(id: 128796)
(id: 128797)
(id: 128799)
对此 , 有推测认为 , 这可能暗示推理模型与非推理模型的融合 。
在编程方面 , 根据网友曝出的结果 , DeepSeek V3.1在Aider Polyglot多语言编程测试中拿下了71.6%高分 , 一举击败了Claude 4 Opus、DeepSeek R1 。
而且 , 它的成本仅1美元 , 成为非推理模型中的SOTA 。
最鲜明的对比 , V3.1编程性能比Claude 4高1% , 成本要低68倍 。
在SVGBench基准上 , V3.1实力仅次于GPT-4.1-mini , 远超DeepSeek R1的实力 。
在MMLU多任务语言理解方面 , DeepSeek V3.1毫不逊色于GPT-5 。 不过在 , 编程、研究生级基准问答、软件工程上 , V3.1与之有一定的差距 。
一位网友实测 , 模拟六边形中小球自由落体的物理测试 , DeepSeek V3.1理解力明显提升 。
一手实测第一时间 , 我们对V3.1进行了实测 , 首先是此次模型更新的重点:上下文长度 。
假设对于中文而言 , 1个token ≈ 1–1.3个汉字 , 那么这128K tokens ≈ 100000–160000汉字 。
相当于整本《红楼梦》正文(约80–100万字)的1/6–1/8 , 或者一篇超长博士论文/大部头学术专著 。
实际测试也很准确 , DeepSeek告诉我们它只能阅读差不多9% , 也就是大约十分之一 。
由于总结内容太长 , 我们截取了前三回 , 你觉得这个总结的怎么样?
在128K上下文测试中 , DeepSeek-V3.1输出速度相比以往获得较大提升 , 并且在工程上做了一些优化 。
此次更新 , DeepSeek重点强调了对上下文的支持 。
整个活 , 给DeepSeek-V3.1上点压力 , 让它根据「梦」这个字 , 输出尽可能多的内容 , 尽量达到上下文极限 。
不过最后 , 差不多只输出了3000字左右 , 模型就停止了输出 。
再来看下推理能力 。
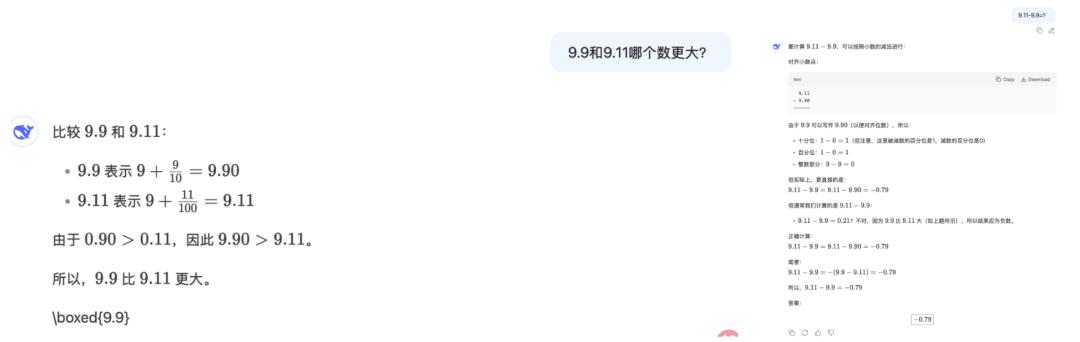
经典的9.11和9.9比大小问题 , 两种询问方式都能正确做答 。
这次更新的一大体感还是速度变快了很多 。
最后再来看看编程能力 。
DeepSeek的上一个模型是R1-0528 , 主打的是编程能力 。
看看这次V3.1是否有更大的提升 。
最终结果只能说 , 打个80分吧 , 基本要求都满足了 , 但是画面风格和颜色变换功能并没有完美实现 。
并且和R1-0528的结果相比 , 两者之间还是有些差距的 , 但孰好孰坏还需看个人偏好 。
以下是开启思考模式后的结果 , 你觉得哪个更好?
接下来 , 看看DeepSeek V3.1能否复刻出GPT-5发布会上的法语学习小程序 。
我们再来让V3.1画一个自己的SVG自画像 , 两种效果着实有些抽象 。
参考资料:HYX
https://weibo.com/2169039837/Q0FC4lmeo
https://x.com/karminski3/status/1957928641884766314
https://github.com/johnbean393/SVGBench/
https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
推荐阅读
















- 核心模型被曝蒸馏DeepSeek?前女友一纸控诉曝出Mistral塌房真相
- 传英伟达将自研HBM Base Die:3nm制程,最快2027年试产
- 被曝蒸馏DeepSeek还造假!欧版OpenAI塌方了
- DeepSeek的GRPO会导致模型崩溃?看下Qwen3新范式GSPO
- 一个模型超了DeepSeek R1、V3,参数671B,成本不到350万美元
- DeepSeek创始人梁文锋:拿下国际顶会最佳论文奖!
- 摩尔线程技术分享日干货!原生支持FP8、DeepSeek R1推理加速150%
- DeepSeek下载量骤降72.2%:背后真相揭秘与市场趋势分析
- 还在用 URL 传小图片?Base64 才是 API 设计的性能利器
- “流量波动”下的DeepSeek:东南亚机遇显现,但观望心态未解