
文章图片

文章图片
文章图片

文章图片
文章图片
文章图片

文章图片
本研究由中科院自动化所和腾讯混元联合研发 , 团队成员包括 Qi Yang Bolin Ni Shiming Xiang Han Hu Houwen Peng Jie Jiang
背景:多模态大模型的思考困境
当前 , 业界顶尖的大模型正竞相挑战“过度思考”的难题 , 即无论问题简单与否 , 它们都采用 “always-on thinking” 的详细推理模式 。 无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换 , 还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换 。 它们距离真正意义上的“智能思考”仍有距离 。 这些方案或将判断压力转移给用户 , 或受限于复杂的系统架构和高昂的部署成本 。 因此 , 研发一款轻量化、支持多模态且能实现更智能自适应思考的大模型 , 将为用户提供更加流畅的交互体验 。
近期 , 由腾讯混元团队与中科院自动化所合作的一项最新研究推出 R-4B 多模态大模型 , 通过自适应思考(auto-thinking)机制 , 改变了这一现状 , 它让 AI 能像人类一样 “智能切换” 思维模式 。 简单问题直接响应 , 复杂问题深度推理 , 在最大化回答准确性的同时 , 最小化计算开销 。
论文标题:R-4B: INCENTIVIZING GENERAL-PURPOSE AUTOTHINKING CAPABILITY IN MLLMS VIA BI-MODE ANNEALING AND REINFORCE LEARNING 论文链接:https://arxiv.org/pdf/2508.21113这一 “按需思考” 的核心能力 , 为 4B 量级的多模态模型树立了全新的性能标杆 , 使其在评测性能指标上成功超越了 Keye-VL-8B、Kimi-VL-A3B-Thinking-2506 等更大规模的模型 。
【DeepSeek、GPT-5都在尝试的快慢思考切换,有了更智能版本】
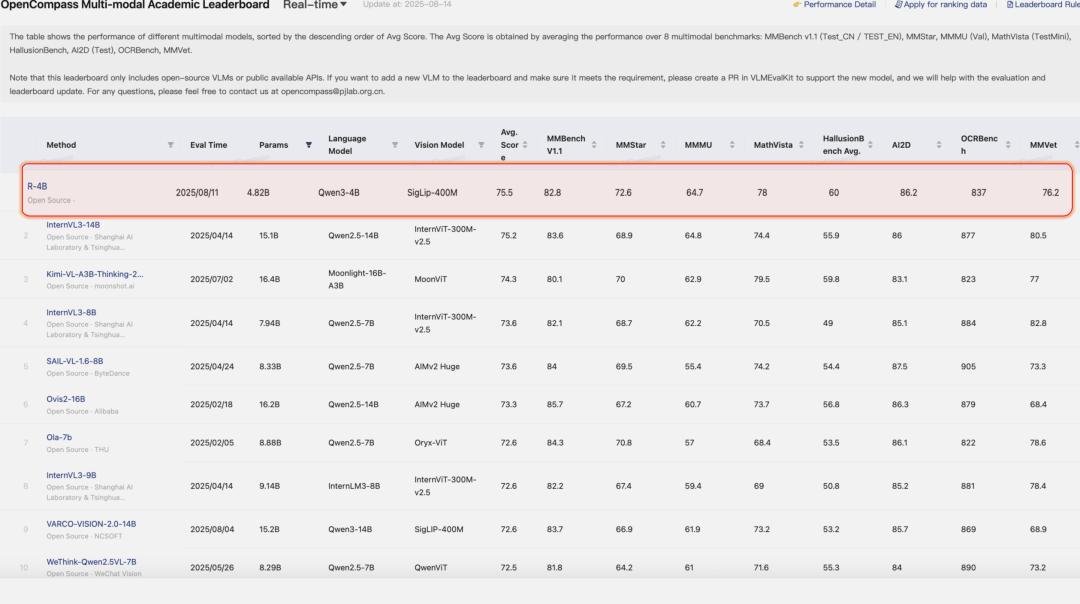
同时 , R-4B 在权威基准 OpenCompass 榜单上取得了优异成绩 。
登顶 OpenCompass 多模态学术榜单:在 20B 以内规模多模态大模型中 , 性能排名 Top 1!
位列 OpenCompass 多模态推理榜单开源榜首:在开源模型中 , 推理性能拔得头筹!
目前 , 该模型已在 GitHub 和 HuggingFace 上线 , 且支持 vLLM 快速部署 。 「消费级显卡即可运行 , 适用于笔记本电脑、智能座舱、智能家居等低功耗场景 , 支持垂直领域低成本微调 。 」截至目前下载量已破万 , 欢迎大家体验!
GitHub 代码仓库:https://github.com/yannqi/R-4B Hugging Face 模型下载:https://huggingface.co/YannQi/R-4B突破:R-4B 的自适应思考引擎
R-4B 的智慧之处在于其自适应思考能力:
遇到简单问题(简单实体识别、简易问答) , 它选择直接、高效地响应 。 面对复杂任务(如数学计算、图表分析) , 它则自动切换到深度思考模式 , 生成详细的思考过程 。R-4B 的核心创新在于其独特的两阶段训练策略 。 为实现模型在通用领域的自适应思考 , 研究团队首先提出双模退火(bi-mode annealing)训练策略 , 促使模型同时掌握通用领域的思考与非思考能力 。
该阶段可以理解为对模型进行 “思考” 启蒙 , 即同时喂给它两种范式数据:一种需要直接回答(非思考模式 , 像日常对话) , 另一种需要详细推理(思考模式 , 像解数学题) 。 通过这种训练 , 模型同时掌握了思考和非思考这两种响应模式 , 为后续的自适应思考模式训练打下坚实基础 。 该阶段的核心是通用领域推理和非推理模式的数据构建策略:针对客观题 , 用模型采样的答案一致性来衡量题目的难易程度;针对主观题目 , 用提示工程的方式去区分解决问题是否需要进一步思考 。
推理模式数据:涵盖图表分析、逻辑推理等需多步推理的任务(如科学图解或数学问题) 。 非推理模式数据:针对直接事实响应的查询(如实体识别或简单问答) 。
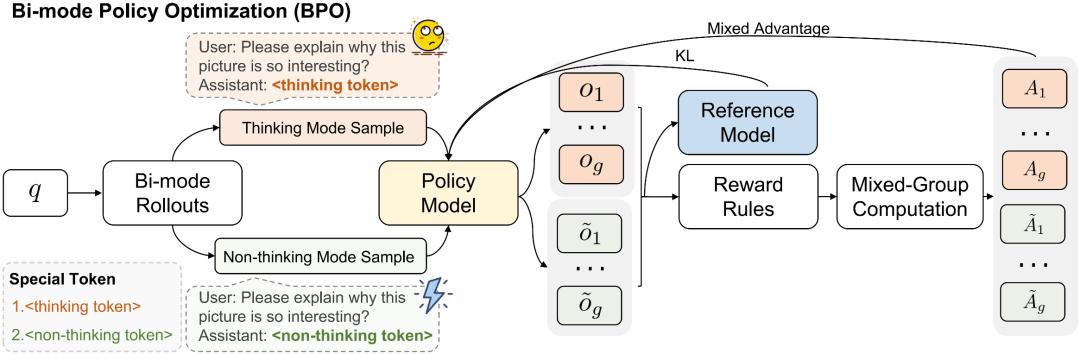
经过退火训练 , 得到一个同时精通思考与非思考模式的基础模型 R-4B-Base, 为后续自适应思考强化训练奠定基础 。 基于此 , 团队开发了双模策略优化(Bi-mode Policy Optimization BPO)强化学习算法 。 它无需依赖精心设计的奖励函数或特定数据 , 而是仅依赖基于规则的奖励信号 , 从数学数据出发 , 并可泛化到通用领域 。 其核心是混合双模 rollout 机制 , 通过强制模型在训练中同时探索思考模式和非思考模式轨迹 , 从而避免模型陷入对单一模式的响应偏好 。 在此基础上 , 通过同时奖励两种思考模式的策略 , 使模型自己学会判别何时应该思考 。
性能表现:小模型 , 大能量
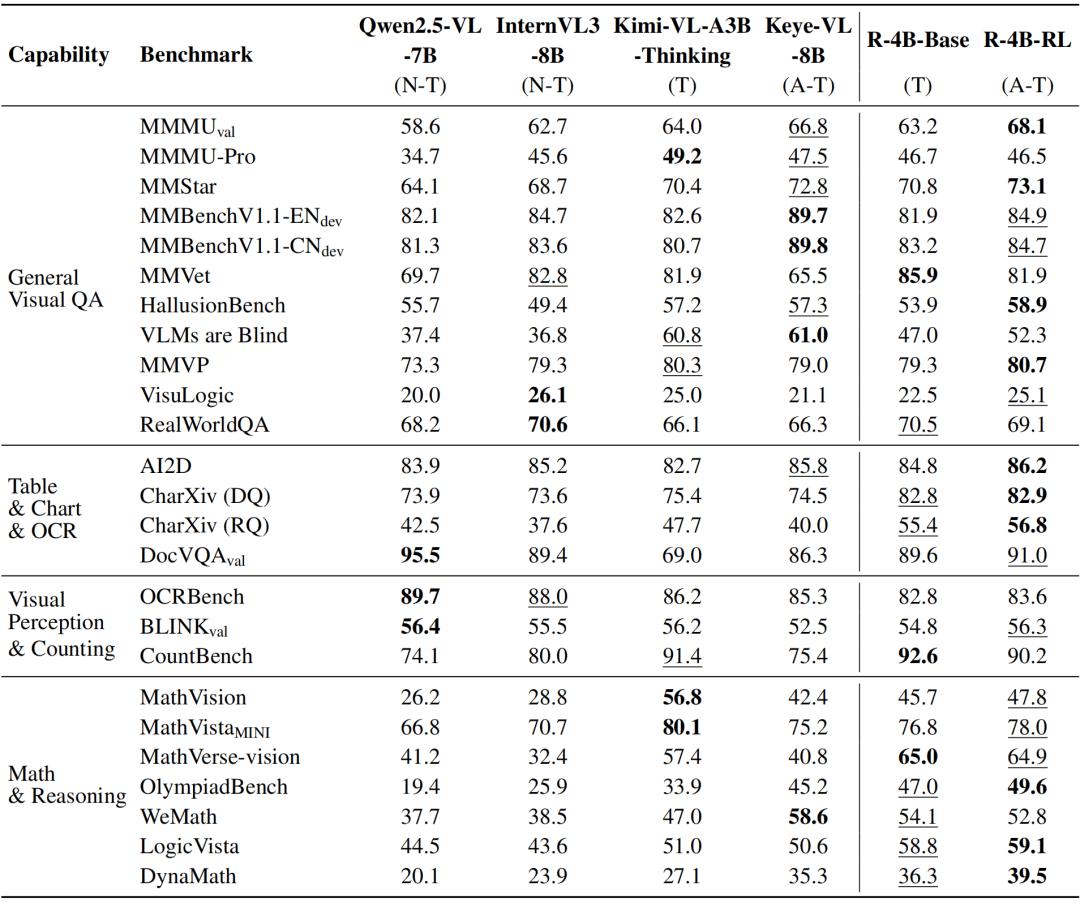
R-4B-RL 模型在多项公开基准测试中性能表现卓越 , 刷新了现有记录 , 其性能超过 Keye-VL-8B、Kimi-VL-A3B-Thinking-2506 等更大规模的模型 。
更关键的是 , R-4B-RL 在自适应思考模式下实现了推理效率的提升 , 在简单任务下模型无需消耗更多的 Token 。 这证明了 BPO 算法的有效性 , 即无需通用领域的强化学习数据或额外的奖励函数设计 , 模型也能实现自适应思考 。
应用前景:从科研到产业的智能化浪潮
R-4B 的突破不止于技术 , 更开启了广阔应用场景:
应用智能 :在日常问答分析中 , 自动切换简单查询(如文档内容提?。 ┖透丛油评恚ㄈ缤急矸治觯┑乃嘉J?, 提升自动化处理效率 。 科学研究 :在处理科学图表时 , R-4B 的深度推理模式可解析多步关系 , 精准解读数据 , 提高研究效率 。 消费级 AI :边缘设备部署中 , R-4B 凭借更少的参数和自适应思考模式降低延迟和能耗 , 适用于即时问答系统 。(1) 文档内容提?。 虻ゲ檠?
(2) 图表分析(复杂推理)
结语:自适应思考 , 探索 AI 发展新道路
从双模退火训练到 BPO 优化 , R-4B 不仅解决了 MLLMs 的思考困境 , 更在小尺寸模型上探索了自适应思考的可行性。 自适应思考不仅是技术优化 , 更是对效率与普惠平衡的追求 。 在 AI 计算与推理成本飙升的今天 , R-4B 的轻量化、智能化设计 , 为大模型可持续发展注入绿色动力 。
R-4B 模型已全面开源 , 支持 vLLM 高效推理 。 下载量火速破万 , 诚邀体验与共建!
推荐阅读












- 百度地图被指打车插广告、关闭键太隐蔽,回应:有明显按钮,可随时手动关闭
- 豆包千问DeepSeek,没上苹果先“上车”
- OriginOS 6 Beta版已推送:通知堆叠、直驱供电,你收到了吗?
- 用户扒出三星三折叠演示动画,能反向充电、NFC支付
- 大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等开源
- 混乱、内耗、丑闻:Meta考虑向Google、OpenAI低头
- 完全意想不到!三星三折叠手机折叠方式曝光:不是Z、G字型
- 小米16正式进场!性能、快充和续航均为满分,高端稳了
- DeepSeek、GPT-5带头转向混合推理,一个token也不能浪费
- 1.4nm芯片,4.5万美元一片,苹果、英伟达都用不起?别扯淡了