【告别铜缆,英伟达CPO光互连明年落地】
文章图片
本文由半导体产业纵横(ID:ICVIEWS)编译自tomshardware
英伟达的CPO能够以更低的功耗实现更快的连接 。
当前AI技术高速迭代 , 大规模GPU集群在训练与推理过程中产生的海量数据交互需求呈指数级增长 , 传统互连方式已难以满足低延迟、高带宽的通信要求 , 这一趋势正推动行业加速向光通信技术转型 , 以突破跨网络层数据传输的性能瓶颈 。
今年早些时候 , 英伟达率先布局这一领域 , 宣布其下一代机架级AI平台将融合两大关键技术——硅光子互连技术与共封装光学器件(CPO) 。 其中 , 硅光子技术凭借光子传输的高速特性提升数据交互效率 , CPO则通过将光学引擎与芯片封装集成 , 减少信号损耗 , 两者结合旨在同时实现更高的传输速率与更低的功耗 , 为AI集群的高效运行提供底层支撑 。
在今年举办的Hot Chips大会(国际高性能芯片领域重要会议)上 , 英伟达进一步披露了该方向的技术落地细节 , 重点发布了下一代Quantum-X和Spectrum-X两款光子互连解决方案的更多参数与功能信息 。 同时 , 官方明确了这两款解决方案的上市时间节点——计划于2026年正式推向市场 , 标志着英伟达在AI集群光互连领域的技术布局已进入商业化落地的关键阶段 。
英伟达的路线图很可能与台积电的 COUPE 路线图紧密相关 , 后者分为三个阶段 。 第一代是用于 OSFP 连接器的光学引擎 , 可提供 1.6 Tb/s 的数据传输率 , 同时降低功耗 。 第二代将采用 CoWoS 封装技术 , 并采用同封装光学器件 , 在主板级别实现 6.4 Tb/s 的数据传输率 。 第三代的目标是在处理器封装内实现 12.8 Tb/s 的数据传输率 , 并进一步降低功耗和延迟 。
为什么是CPO?在大规模 AI 集群中 , 数千个 GPU 必须像一个系统一样运行 , 这给这些处理器的互连方式带来了挑战:每个机架不再拥有自己的一级(架顶式)交换机 , 并通过短铜缆连接 , 而是将交换机移至机架末端 , 以便在多个机架之间创建一致、低延迟的结构 。 这种迁移极大地延长了服务器与其第一个交换机之间的距离 , 这使得铜缆在 800 Gb/s 这样的速度下变得不切实际 , 因此几乎每个服务器到交换机以及交换机到交换机的链路都需要光纤连接 。
图片来源:英伟达
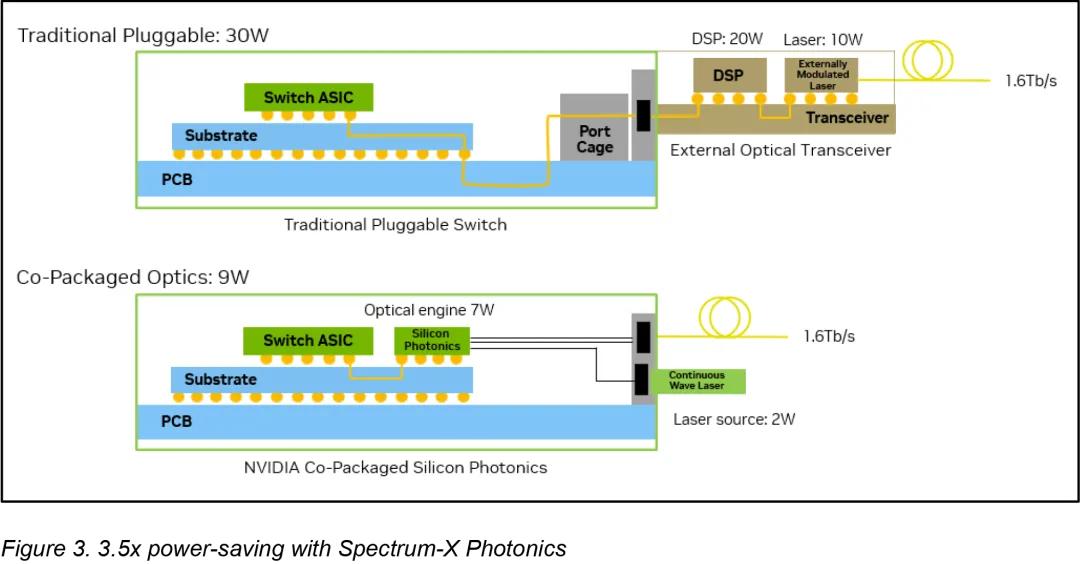
在这种环境下使用可插拔光模块存在明显的局限性:此类设计中的数据信号离开ASIC , 穿过电路板和连接器 , 然后才转换为光信号 。 这种方法会产生严重的电损耗 , 在200 Gb/s通道上损耗高达约22分贝 , 这需要使用复杂处理进行补偿 , 并将每个端口的功耗增加到30W(这又需要额外的冷却并造成潜在的故障点) 。 据英伟达称 , 随着AI部署规模的扩大 , 这种损耗几乎变得难以承受 。
图片来源:英伟达
CPO 通过将光转换引擎与交换机 ASIC 并排嵌入 , 避免了传统可插拔光模块的缺点 , 信号无需通过长距离电气线路传输 , 而是几乎立即耦合到光纤中 。 因此 , 电气损耗降低至 4 分贝 , 每端口功耗降至 9W 。 这种布局省去了众多可能出现故障的组件 , 并大大简化了光互连的实施 。
英伟达声称 , 通过放弃传统的可插拔收发器 , 并将光学引擎直接集成到交换机芯片中(得益于台积电的 COUPE 平台) , 其在效率、可靠性和可扩展性方面实现了显著提升 。 英伟达表示 , 与可插拔模块相比 , CPO 的改进非常显著:功率效率提高了 3.5 倍 , 信号完整性提高了 64 倍 , 由于有源设备减少 , 弹性提高了 10 倍 , 并且由于服务和组装更简单 , 部署速度提高了约 30% 。
以太网和InfiniBand的CPO英伟达宣布将推出基于 CPO 的光互连平台 , 该平台可兼容支持以太网与 InfiniBand 两大主流互连技术 , 应用场景涵盖数据中心、高性能计算等领域 。
Quantum-X InfiniBand 交换机是该平台的首发产品之一 , 英伟达计划于 2026 年初推出该设备 。 从性能指标来看 , 每台 Quantum-X InfiniBand 交换机的整机吞吐量为 115 Tb/s , 可用于大规模数据集群的数据传输 , 对数据拥塞问题有缓解作用 。 在端口配置上 , 该交换机支持 144 个端口 , 单个端口速率为 800 Gb/s , 其端口密度与单端口速率的配置 , 可适配不同规模数据中心的组网需求 。
在功能配置方面 , 该交换机集成了专用 ASIC(专用集成电路) , 该 ASIC 的网络内处理能力为 14.4 TFLOPS , 可在网络层面完成数据计算、处理任务 , 无需将数据回传至服务器 CPU , 对数据处理延迟及整体系统运算效率存在影响 。 同时 , 该交换机支持英伟达第四代可扩展分层聚合缩减协议(SHARP) , 该协议可优化集体操作的处理流程 , 对分布式计算场景下的延迟及系统协同工作效率产生作用 。
针对设备运行中的散热需求 , Quantum-X InfiniBand 交换机采用液冷散热方案 。 与传统风冷散热相比 , 液冷散热在散热效率、噪音控制、空间占用方面存在差异 , 可将设备内部热量导出 , 使交换机在高吞吐量、高负载运行状态下维持工作温度 , 为系统运行提供散热支持 。
*声明:本文系原作者创作 。 文章内容系其个人观点 , 我方转载仅为分享与讨论 , 不代表我方赞成或认同 , 如有异议 , 请联系后台 。
想要获取半导体产业的前沿洞见、技术速递、趋势解析 , 关注我们!
推荐阅读












- 英伟达B30A,一旦对中国倾销,国产AI芯片将面临大麻烦
- 被黄仁勋说准了,华为AI芯片,迟早取代英伟达芯片
- 能效跃升3.5倍、信号完整性提高64倍!英伟达AI GPU光通信方案曝光
- 性能大幅阉割!英伟达中国特供B30亮相!黄仁勋:获批前景不明
- 美芯片解禁内幕曝光,难怪英伟达不承认有后门,搬起石头砸自己脚
- 揭秘小鹏机器人:挖来英伟达大牛,产线已落地几百台|智能涌现独家
- 华为开源CANN,要跨过英伟达又一条护城河?
- 腾讯:不买英伟达H20,GPU芯片够用了,未来转向国产
- 英伟达暂停生产H20芯片 新型B30A或成中国市场新选择
- 英伟达 CUDA 重大更新!