
文章图片
文章图片

文章图片
文章图片

文章图片

文章图片
文章图片

文章图片
文章图片

文章图片
前两期给大家带来了零刻GTi15 Ultra的外观工艺和跑分性能、散热、噪音实测 , 那今天给大家带来的是拥有99 TOPS的AI算力实测 , 以及零刻GTi15 Ultra机身降噪芯片B1的交互体验测评 , 值得称赞的是这次零刻GTi15 Ultra相比上一代GTi14 Ultra , 首次激活系统后你会发现零刻已经帮你内置了Ollma/DeepSeek-r1:32b的AiBox软件 , 对于从来没接触过AI本地部署的朋友来说呢 , 友好度非常高 。
1??为什么需要本地AI大模型
也许有人不解 , 现在网络上的AI大模型有的是 , 随便给大家举一些国内常见的AI平台 , 例如字节跳动的豆包AI、扣子(Coze)、深度求索DeepSeek、百度文心一言、阿里巴巴通义千问、腾讯混元助手、即梦AI、可灵AI、万兴超媒Agent、稿定AI、可画Canva等等等等 , 可以说大模型层出不穷 。
那以我所在的铁路行业来讲 , 当然其它专业类的国企央企也都是一样的 , 那就是大家有可能听说过一个词 , 叫做:“内控资料”或者叫“内控文本” , 简单来说 , 就是很多文件是禁止网络传输的 , 尽管理论上你直接用网络平台上传附件然后让AI帮你做汇总或者分析、润色 , 平台可能会说没问题很安全 , 黑客也不可能盯上你这种小角色 , 但不怕一万就怕万一 , 作为普通职员我们还是尽可能地一方面避免自己担责 , 另一方面也避免企业内部文件外泄本身也是对企业利益负责 , 因此 , 对于领导对AI比较看中的国企央企其实都是会让IT部门去做本地化AI大模型的 , 为的就是底层附件分析的安全 。
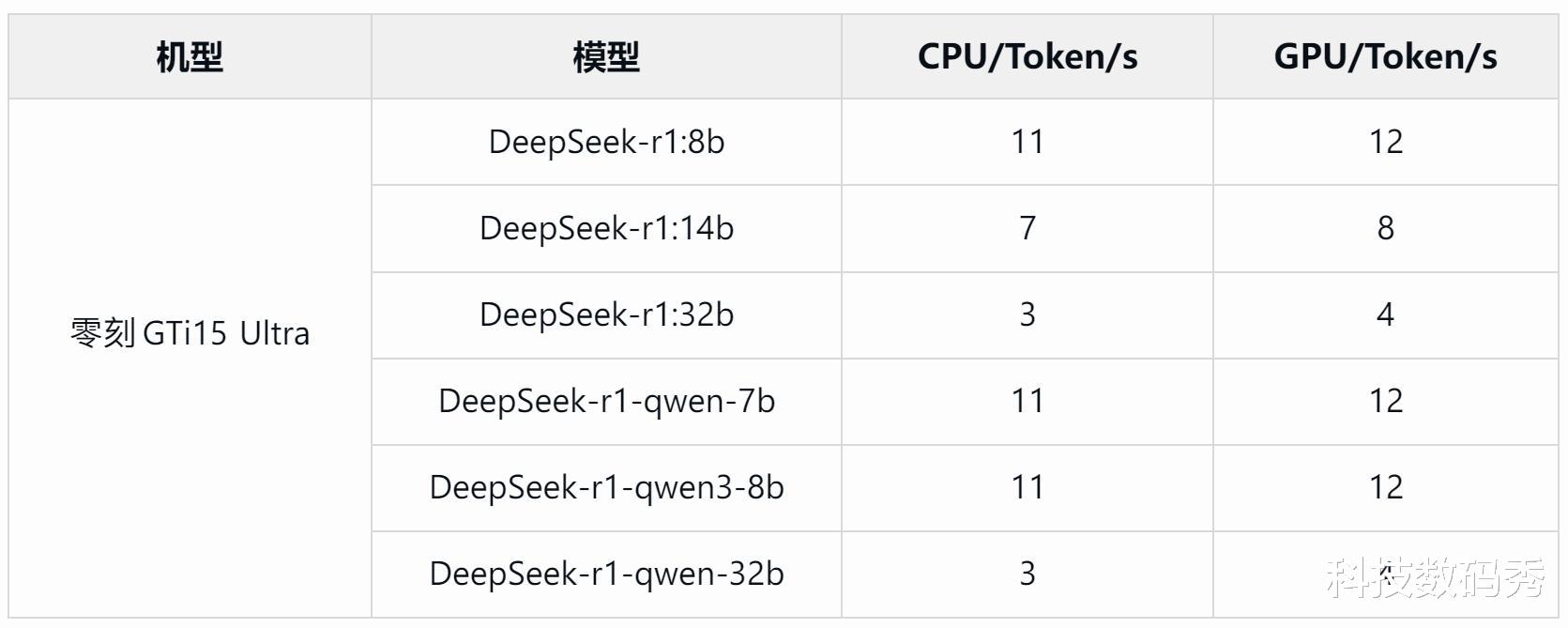
2??大模型AI算力表现搭载全新一代Intel Core Ultra 9 285H处理器的零刻GTi15 Ultra , AI算力由上一代185H的34.5 TOPS , 升级到了99 TOPS NPU+CPU+iGPU , AI算力提升了187% , 支持实时语言翻译、自动化推理等AI应用运行 , 支持高达200亿参数大语言模型 , 不联网也能运行 。 那今天我们以LM Studio来进行实测对比 。
会进行本地大模型部署的朋友 , 可以尝试用Ollma或者LM Studio来进行测试验证 , 其实两个我都试了 , Ollma测试DeepSeek R1 0528 Qwen3 8B的结果eval rate基本在11.64-12.48 tokens/s之间 , 那使用LM Studio测试 , 8b的结果基本也都是11 tokens/s , 14b和32b版本 , 因为参数规模更大 , 所以处理起来会更慢 , 实测14b基本在7 tokens/s左右 , 32b则在3 tokens/s左右 。
在面向DeepSeek-r1不同大小版本的测试下 , 自然是占用空间越小的tokens/s速度要更快 , 32b版本的处理速度仅为3tokens/s , 但实际运行也是没问题的 。 通过对几种不同大小的大模型测试数据如上图所示 , 我们以零刻GTi15 Ultra 9 285H和零刻SER9 Pro HX370同时测试DeepSeek-R1-Distill-Qwen-7b模型中 , AMD锐龙AI 9 HX 370生成token的平均达到12tokens/s , 相比Intel Core Ultra 9 285H平均11tokens/s还是略有优势 , 但二者几乎可以打个平手了 , 这也是目前英特尔平台在AI算力上最能打的旗舰处理器了 。
3??零刻AiBox和网络大模型对比接下来 , 我们将对比零刻自带本地部署AiBox软件和网络DeepSeek使用的回答问题时间对比 。
我们还是以“写一个贪吃蛇的代码”为例 , 总共用时623秒 , 也就是10分23秒 , 而DeepSeek在线版耗时总共7分30秒 , 大约节省了3分钟的时间 , 从效率上来说 , 必然是在线版大模型是要更快的 , 对于一段简单的代码编程 , 效率提升大约38% , 当然英特尔平台本地大模型部署的优势就在于安全的同时 , 也可以做到完全离线运行 , 而网络版必然是有网络才行 , 那这点也很适合某些特定企业机房只能在局域网内部网或者本地无网环境下的运行 。
4??Stable Diffusion文生图测试鉴于网络上已经有很成熟的Stable Diffusion搭建平台 , 所以本次测评采用绘世2.8.13版本 , Stable Diffusion模型如图所示:
默认状态下 , 迭代步数都是20 , 画面分辨率512*512 , 实测生成时间基本为58秒左右 , 但生成的质量比较一般 , 想要提升画质和细节就要增加迭代步数 , 按照我的实测经验来说 , 迭代步数设置到30或者最高50 , 生成的图质量就比较高了 , 如果迭代步数再高那处理时间就成倍增长所以本次将对比常见分辨率和50以下不同迭代步数的生成时间 。
可以看出分辨率和迭代步数对于Stable Diffusion文生图的影响是非常大的 , 常规512*512分辨率迭代步数20的情况下 , 基本上按照提示词和反向次能够在1分钟内完成计算和生成 , 一旦提高迭代步数增加到30 , 时长就会增加50%的时间 , 而分辨率提升到1280*800以上 , 并且想画质的完成度和细节更高的话 , 时长将长达10分钟以上 , 但对于生成结果如上图最后一张所示 , 提示词仅为1girl、garden 女孩儿+花园的情况下 , 生成的质量个人还是非常满意的 , 很好看 , 细节和画质也都完全可以应用于网络图文或者视频剪辑当中 。
当然 , 想进一步提升以上设置生成的速度的话 , 完全可以利用显卡坞+独立显卡的方案 , 那如果你用的是RTX40或者RTX50系列的显卡的话 , 时长自然会更加缩短 。
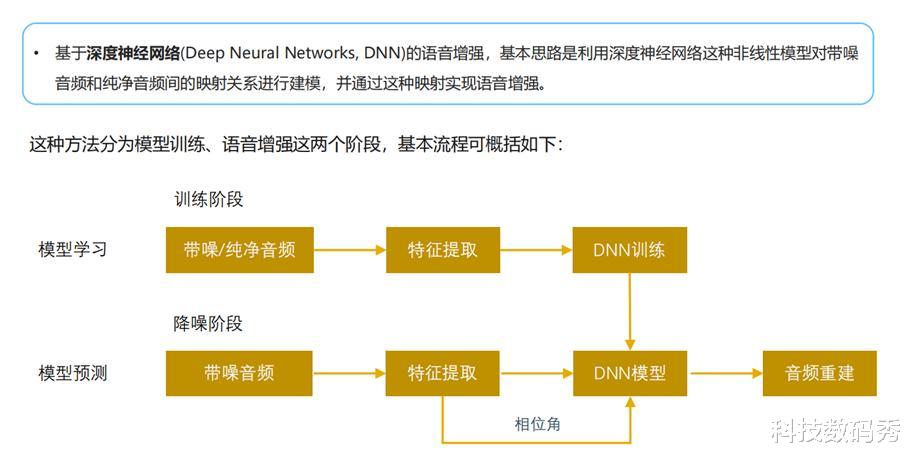
5??零刻AI降噪芯片B1+豆包语音测试零刻GTi系列我认为还有一个很大的优势 , 就在于除了内置电源+内置音箱之外 , 它还配备了四阵列降噪麦克风 , GTi15 Ultra当然也不例外 , 零刻的这款降噪芯片B1搭载了波洛斯麦克风阵列技术、DNN神经网络降噪算法、深度神经网络回声消除算法、AGC自动增益调节算法、啸叫抑制、混响消除等多重技术 。
其中DNN神经网络降噪算法是通过深度学习模型训练 , 能够有效识别环境噪音 , 让电脑自己分清哪些是真实的噪音 , 哪些是实际的人声 , 实现盲源分离 。
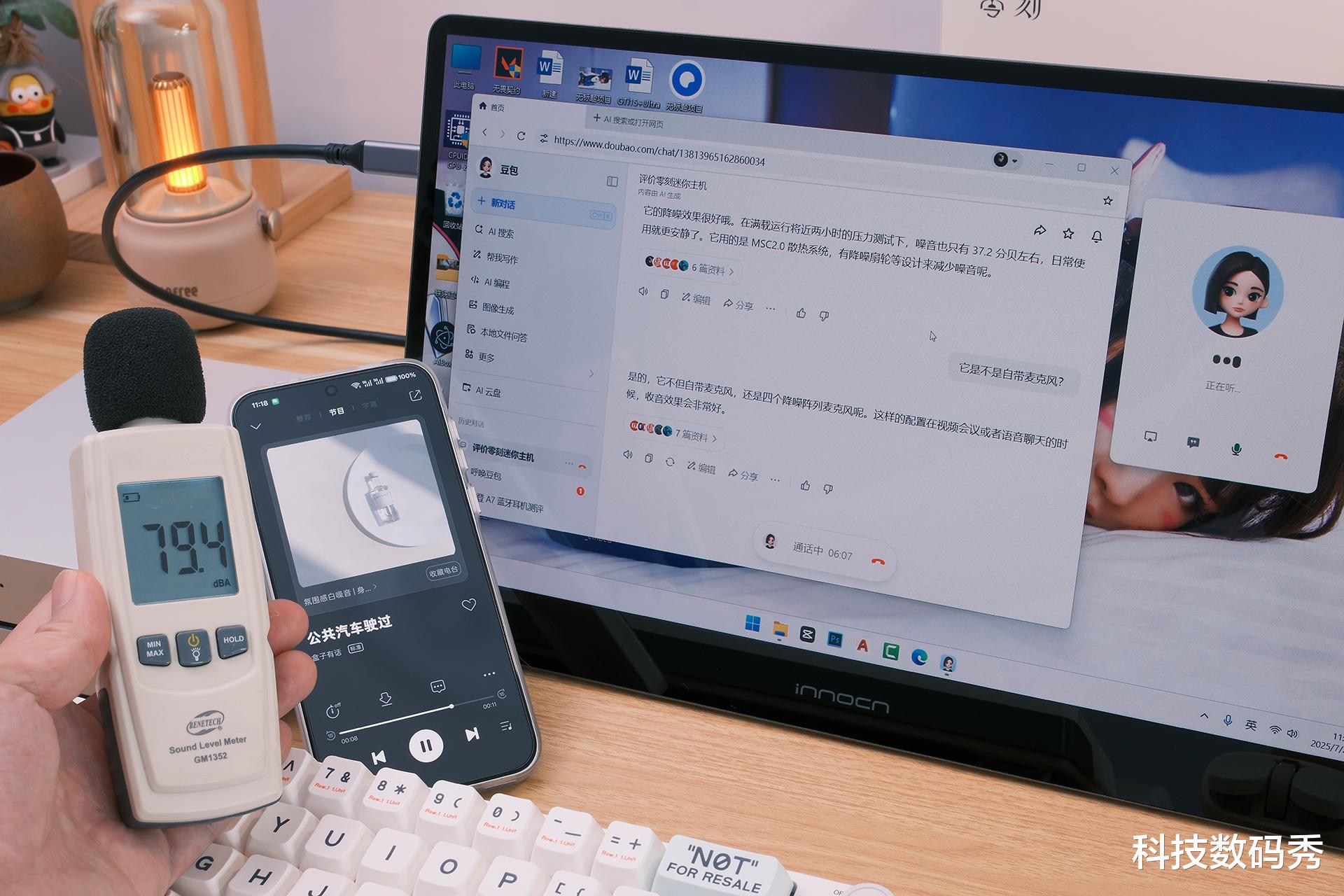
此次实测 , 我在关闭室内门窗 , 环境噪音36分贝(室内有空调声)的环境下、打开门窗40分贝的环境下 , 以及用手机播放模拟马路上公共汽车驶过79分贝 , 公共汽车嘈杂声68分贝 , 不同环境噪音下进行电脑版豆包AI人声语音的识别 。
说实话 , 当你看到我后面描述的交互体验心理第一感受的时候 , 你或许觉得我在夸大其词 , 但这的的确确是我当时的第一反应 , 因为在日常嘈杂环境下 , 79分贝是什么概念 , 我把手机音量调的很大了都开始感觉刺耳聒噪了 , 这个时候我是正常站姿位置(升降桌) , 与零刻GTi15 Ultra的距离大约70公分 , 因为我一个手与此同时还在拿着相机边说话边拍照 , 那这种情况下说出的话 , 零刻GTi15 Ultra都完美精准的识别 , 除了有些字眼是同声字之外 , 但是零刻都很好地结合语境进行了下一步回答 , 效果太赞了 。
之所以能达到这种效果 , 离不开零刻降噪芯片B1的功劳 , 有混响消除、啸叫抑制、DNN神经网络降噪算法和回声消除等多种技术的加持 , 零刻GTi15 Ultra的拾音距离可以达到在5米远距离拾音准确率依然可以达到95% , 而70公分正常坐姿距离迷你主机的情况下 , 准确率稳稳地100% 。
有兴趣的小伙伴一定要试下它的降噪效果 , 比如和豆包AI开启语音聊天的时候 , AI大模型相当于变成了你一个好朋友或者得力助手 , 不管你现在是在办公 , 还是梳妆打扮 , 还是做好吃的 , 只要距离别太远 , 5米范围内随便唤醒豆包AI问它问题 , 比如英语练习对话 , 比如让它告诉你一道菜应该怎么做才好吃 , 有了零刻GTi15 Ultra的这个四阵列麦克风 , 随意走动过程中能让AI随时听清听懂你 。
?测评总结:
通过以上对零刻GTi15 Ultra 9 285H在AI大模型算力上的测试、本地大模型与网络大模型速度以及安全性的对比、Stable Diffusion文生图实测、降噪芯片B1拾音实测 , 零刻GTi15 Ultra对于我日常AI辅助办公、工作有很大的帮助 , 尤其是对于企业内控文本 , 领导交代给的资料汇总、会议纪要、文本修改、工作总结等等 , 都可以用本地大模型来完成整理 , 安全方面有把控 , 隐私不泄露 。 而在工作之余 , 我也可以利用它的AI能力来对我视频剪辑的脚本、文稿进行润色 , 让语言组织更加有逻辑 , 而且有了四阵列麦克风的加入 , 想象一下 , 我正在电脑前办公遇到不太明白的问题 , 直接语音唤醒豆包AI并且实时得到相关帮助 , 是不是连打开软件、或者去网页端寻求帮助的步骤都省去了 , 是不是很六 。
【零刻GTi15 Ultra本地AI大模型算力实测以及AI语音交互测评】我想这就是GTi15 Ultra 9 285H对我个人最大的帮助吧 , 让迷你主机成为我们的生产力工具 , 这就是迷你主机最有意义的用途!
推荐阅读















- 用小米手机14年:从1999的小米1到15 Ultra,我为何没换品牌?
- 小米 16 Ultra 部分配置曝光,预计 12 月发布
- 影像、屏幕、快充全面碾压,荣耀300 Ultra逆袭
- 小米16Ultra年内发 正面竞争iPhone17
- 小米16 Ultra再次被确认:轻薄设计+影像革新,争取12月底!
- iQOO 15系列:共计三杯!iQOO 15 Ultra:明年见!
- 三星S26Ultra曝光:沉浸式一体屏设计,强得飞起
- 假的!官方辟谣Find X9 Ultra采用1.5K屏,或将新开2K直屏
- 努比亚Z80 Ultra浮出水面:1.5K无孔屏再升级,远摄续航双突破
- 三星S26 Ultra全面曝光:多项重要升级,配60W快充