文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
文章图片

文章图片

文章图片
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
没能等到GPT-5 , 但OpenAI在深夜却很突然地open了一下——
开源两个推理模型:gpt-oss-120b和gpt-oss-20b 。
要知道 , 上一次OpenAI开源模型还是6年前 , 也就是2019年的GPT-2 。
而这次的名字也是非常的直接 , gpt-oss , 即Open Source Series , 意思就是“开源系列” 。
它们的亮点如下:
gpt-oss-120b:1170亿参数(MoE架构 , 激活参数约51亿) , 可在单张80GB GPU上运行 , 性能接近闭源的o4-mini 。 gpt-oss-20b:210亿参数(Moe架构 , 激活参数约36亿) , 可在16GB内存的消费级设备上运行 , 性能接近o3-mini 。并且它俩均采用Apache 2.0许可证 , 允许商用无需付费或授权 。
从性能角度来看 , gpt-oss已经达到了开源模型里推理性能的第一梯队 , 但在代码生成和复杂推理任务中仍略逊于闭源模型(如GPT-o3和o4-mini) 。
在模型发布的第一时间 , Sam Altman在自己的社交平台上也道出了这俩模型的“价值”:
可以在本地笔记本(20b的可以在手机上)运行;耗资数十亿美元的研究成果 。
并且苏妈(Lisa Su)也是几乎同时出来为Altman站台 , 表示“很荣幸成为第0天的合作伙伴” 。
不过有意思的是 , 在官方HuggingFace介绍中 , 提及的却是英伟达的H100……
先看效果在开源动作一个小时后 , OpenAI官方还放出了一个实测效果的视频 。
这次讲解的人员 , 分别是在OpenAI负责开发者体验的Dom和Zhaohan:
他俩是在一台120G的Macbook Pro上进行的测试 , 借助Ollama在本地运行120B的gpt-oss(搭了2块H100) 。
二人先小试牛刀 , 测试了一下gpt-oss在思维链中调用工具的能力 , 即搜索+Python解释器 。
他们在开启Browser Tool和Python Tool后 , 在本地提问:
旧金山天气如何?
可以看到 , 本地的gpt-oss-120b稳稳地输出了正确的结果 。
在第二个测试例子中 , 他们让2个非常大的数字相乘 。
在这个过程中 , 可以看到gpt-oss一次又一次地调用Python工具 , 虽然中间有出错的情况 , 但最终给到了正确的答案 。
接下来 , 二人把网直接断掉 , 在本地搞了一个射击类的小游戏:
同样是在断网的情况下 , 他俩又经过一番操作 , 将游戏中的图标变成了草莓的样式:
整体来看 , 实测的体感还是比较丝滑的 , 并且生成速度达到了40-50 tokens/s 。
完整体验视频如下:
视频地址:https://mp.weixin.qq.com/s/bIaUXw9XWR2Sb4dy4i37_Q
再看性能除了实测效果之外 , OpenAI也一道发布了gpt-oss相关的技术博客 。
整体来看 , 这两个模型在工具使用、少样本函数调用、链式思考推理(如Tau-Bench智能评估套件的结果所示)以及HealthBench上表现强劲 , 甚至超越了包括OpenAI o1和GPT?4o在内的专有模型 。
预训练与模型架构
gpt-oss模型使用的OpenAI最先进的预训练和后训练技术进行训练 , 特别关注推理、效率和在广泛部署环境中的实际可用性 。
虽然OpenAI已经公开了包括Whisper和CLIP在内的其他模型 , 但gpt-oss模型是自GPT?2以来的第一个开放权重语言模型 。
每个模型都是一个Transformer , 利用专家混合(MoE)来减少处理输入所需的活跃参数数量 。
gpt-oss-120b每个token激活5.1B个参数 , 而gpt-oss-20b激活3.6B个参数 。 这些模型分别具有117b和21b的总参数 。
这些模型使用类似GPT?3的交替密集和局部带状稀疏注意力模式 。
为了提高推理和内存效率 , 模型还使用分组多查询注意力 , 组大小为8 。 团队使用旋转位置嵌入(RoPE)进行位置编码 , 并原生支持最长128k的上下文长度 。
团队在主要由英语文本组成的数据集上训练这些模型 , 重点关注STEM领域、编程和通用知识 。
OpenAI使用一个超集(superset)分词器对数据进行分词 , 该分词器基于OpenAI o4-mini和GPT?4o使用的分词器:o200k_harmony , 今天也将开源这一分词器 。
后训练阶段
这些模型采用与o4-mini相似的流程进行了后训练 , 包括有监督微调阶段和高算力的强化学习阶段 。
OpenAI的目标是使模型符合OpenAI 模型规范的要求 , 并在生成答案之前学会使用链式思维(CoT)和工具调用 。
在后训练过程中 , 团队采用了与OpenAI最先进专有推理模型相同的技术 , 使这些模型展现出了卓越的能力 。
与API中OpenAI o系列推理模型类似 , 这两个开源权重模型支持三种推理强度——低、中、高——在延迟与性能之间实现权衡 。
开发者可以通过系统提示语中的一句话 , 轻松设定所需的推理强度 。
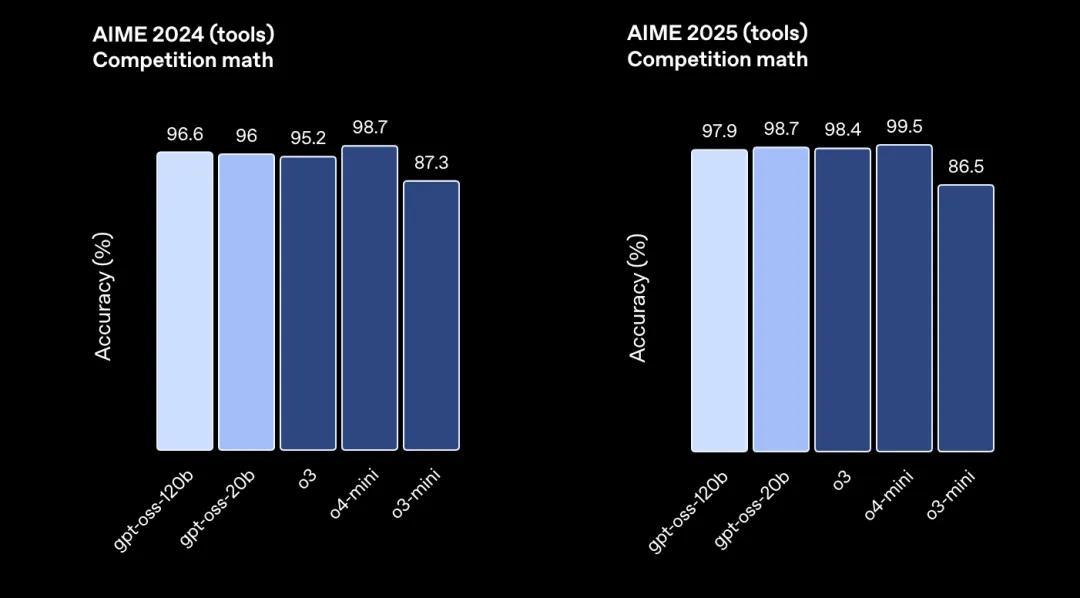
评估结果团队对gpt-oss-120b和gpt-oss-20b进行了标准学术基准测试评估 , 衡量它们在编程、竞赛数学、健康问答和Agent工具使用等方面的能力 , 并与OpenAI的其他推理模型(包括 o3、o3-mini 和 o4-mini)进行了对比 。
在竞赛编程(Codeforces)、通用问题解决(MMLU和HLE)以及工具调用(TauBench)方面 , gpt-oss-120b的表现优于OpenAI的o3-mini , 并达到或超过了o4-mini的水平 。
在健康相关问答(HealthBench)和竞赛数学(AIME 2024 与 2025)上 , gpt-oss-120b的表现甚至超越了o4-mini 。
尽管体积较小 , gpt-oss-20b在同样的评估中也达到了或超过了OpenAI o3-mini的水平 , 尤其在竞赛数学和健康问答方面表现更加出色 。
思维链
OpenAI最近的研究表明 , 在模型的链式思维(CoT)未经过直接监督对齐训练的前提下 , 监测其推理过程的CoT有助于识别不当行为 。
遵循自发布OpenAI o1-preview以来的一贯原则 , 团队在gpt-oss模型上并未对CoT进行任何形式的直接监督 。
OpenAI认为 , 这一点对于监测模型的不当行为、欺骗行为及滥用情况至关重要 。
团队希望 , 通过发布一个未经过监督对齐的开源模型 , 能够为开发者和研究人员提供机会 , 自主研究并实现各自的 CoT 监测机制 。
开发者不应在其应用中将模型的链式思维内容直接展示给用户 。
因为这些内容可能包含虚构或有害信息 , 其中的语言可能不符合OpenAI的安全标准 , 甚至可能泄露模型被明确指示不得在最终输出中包含的信息 。
OpenAI为什么要开源?在技术博客的最后 , OpenAI也对今天开源的动作 , 做出了解释 。
在OpenAI看来 , gpt-oss-120b和gpt-oss-20b的发布 , 是开源权重模型向前迈出的重要一步 。
以其体量 , 这两款模型在推理能力和安全性方面都实现了实质性提升 。
开源模型是对OpenAI托管模型的重要补充 , 为开发者提供了更丰富的工具选项 , 加速前沿研究 , 推动创新 , 并支持更安全、透明的AI开发 , 适用于更广泛的使用场景 。
这些开源模型还降低了新兴市场、资源受限行业以及中小型组织进入AI的门槛——这些组织可能缺乏采用专有模型所需的预算或灵活性 。
如今 , 全球更多人可以借助这些强大、易获取的工具进行建设、创新 , 并为自己和他人创造新的机会 。 开放获取这些在美国开发的高能力模型 , 有助于推动AI发展走向更加民主化 。
一个健康的开源模型生态 , 是实现AI普及并惠及全人类的重要维度之一 。
One More Thing:虽然但是……网友们最最最最关心的似乎还是——
GPT-5呢????
【OpenAI开源2个推理模型:笔记本/手机就能跑,性能接近o4-mini】
技术博客地址:https://openai.com/index/introducing-gpt-oss/
HuggingFace地址:https://huggingface.co/openai/gpt-oss-120b
GtiHub地址:https://github.com/openai/gpt-oss
— 完 —
量子位 QbitAI · 头条号
关注我们 , 第一时间获知前沿科技动态
推荐阅读












- 就是阻击OpenAI,Claude抢先数十分钟发布Claude Opus 4.1
- 华为重要官宣:全面开源!与英伟达上演“龙虎斗”?
- 手机也能跑,腾讯混元一口气开源4款小模型
- 阿里开源两款4B小模型:手机电脑都能用,比GPT-4.1-nano还强
- OpenAI或在周五凌晨发布GPT-5 有望较现有模型好得多
- 美国不甘落后!启动ATOM计划:直指中国“千问”开源AI领先地位
- OpenAI被“断供”,AI圈也搞起了以邻为壑
- 为更好与英伟达CUDA竞争,华为CANN全面开源
- 腾讯AI Lab开源可复现的深度研究智能体,最大限度降低外部依赖
- 刚刚,OpenAI发布2款开源模型!手机笔记本也能跑,北大校友扛大旗