
文章图片

文章图片

文章图片
文章图片
文章图片
文章图片
文章图片
允中 发自 凹非寺
量子位 | 公众号 QbitAI
腾讯混元最新发布并开源原生多模态生图模型——混元图像3.0(HunyuanImage 3.0)!
模型参数规模高达80B , 是目前参数量最大的开源生图模型 。
同时 , HunyuanImage 3.0将理解与生成一体化融合 , 也是首个开源工业级原生多模态生图模型 , 效果对标业界头部闭源模型 , 堪称目前开源领域最强图像生成模型 。
效果上 , HunyuanImage 3.0支持多分辨率图像生成 , 具有强大的指令遵从、世界知识推理、文字渲染能力 , 出图具有极致的美学与艺术感 。
话不多说 , 具体来体验一下HunyuanImage 3.0的生成效果 。
得益于原生多模态架构的架构优势 , HunyuanImage 3.0继承了Hunyuan-A13B的世界知识 , 具有原生世界知识推理能力 。
因此 , 让它生成一张解方程的步骤图 , prompt“解方程组5x+2y=26 , 2x-y=5 , 给出详细过程” , 它也能把题目解出来并完成生成:
“用一幅图介绍堆排序算法流程 , 用小黄脸的表情包 , 来可视化 , 表情越开心 , 代表数值越大 , 并提供伪代码 , 手帐风格 , 小红书图片样式” , 就连这种特别复杂的prompt它都能驾驭:
它还具有强大的文字渲染能力 , 通过对文字渲染数据的定向补充和借助HunyuanOCR进行文字识别的能力提升 , 3.0版本实现了接近头部模型的文字渲染能力 , 让海报、表情包制作、更多创意玩法变得更加简单 。
同时 , HunyuanImage 3.0进行了充分的后训练打磨 , 在和设计师的配合下逐渐形成HunyuanImage自己的美学风格 , 打造极致的美学和艺术风格 。
四宫格图生成也可以 , 创作漫画 , 设计不同材质的兔子模型 , 亦或是制作素描画漩涡鸣人的教程 , 通通不在话下 。
技术方面 , 腾讯混元也公开了 。
核心技术方案新一代模型基于Hunyuan-A13B(总参数量80B , 激活参数量13B) , 原生多模态、统一自回归框架 , 将文本理解、视觉理解与高保真图像生成深度融合于同一大脑 , 带来前所未有的端到端图像生成一致性、可控性与推理能力 。
不同于将LLM仅作编码器的传统DiT路线 , 混元3.0的原生多模态设计以LLM为核心底座 , 天然继承强大的语言与推理能力 , 并在预训练阶段即深度混合LLM数据、多模态理解与多模态生成数据 , 形成“理解反哺生成、语言驱动视觉”的正反馈闭环 , 显著提升语义对齐、细节控制与复杂场景的创作稳定性 。
HunyuanImage 3.0面向社区完全开源 , 代码与权重同步释出 。
双编码器结构混元3.0采用VAE+ViT的联合特征作为图像理解输入 , 模型在统一序列中对图像内容进行精准解析与应答;在图像生成侧 , 沿袭Transfusion思路将Diffusion建模无缝嵌入LLM架构 , 实现文本和图像的灵活交互 , 覆盖从创作到编辑的完整链路 。
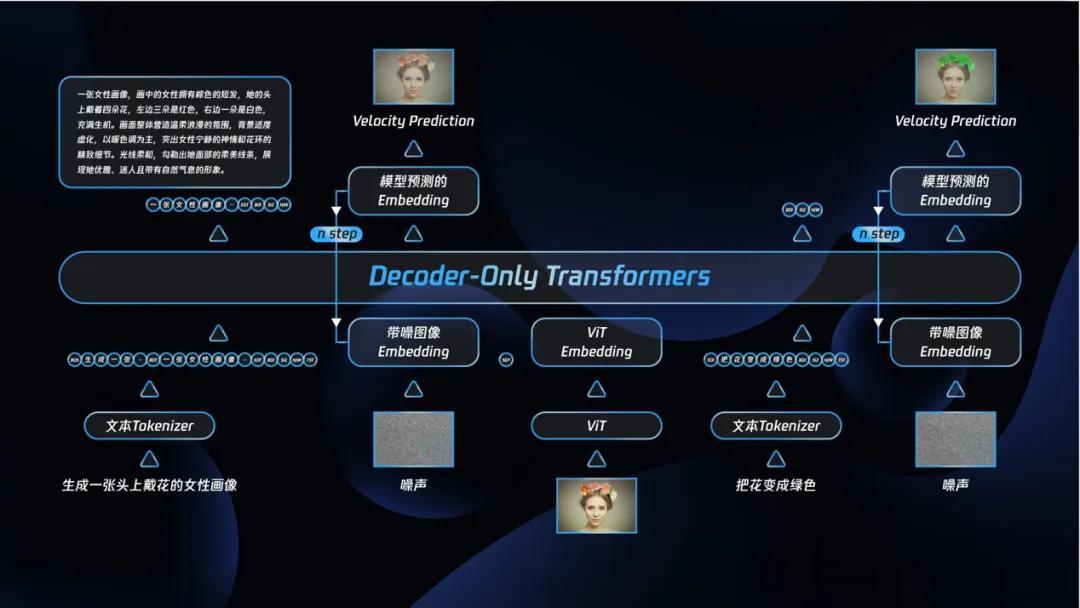
广义因果注意力广义因果注意力 , 让“一体化理解与生成”真正落地:
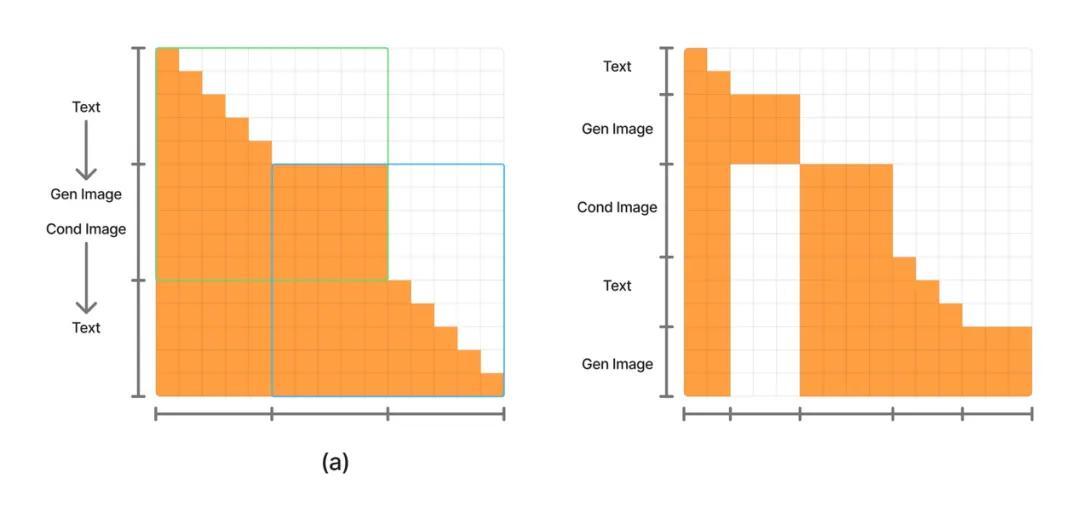
为适配原生多模态的多任务需求 , HunyuanImage 3.0引入Generalized Causal Attention(广义因果注意力) 。 其核心思路是在保持文本token依旧遵循LLM的因果型(下三角)注意力的同时 , 对图像token赋予全局注意力能力 , 形成兼顾“语言因果推理”与“图像全局建模”的注意力矩阵 。
由此 , 文生图场景对应绿色框(图a)关注形式 , 图文理解场景对应蓝色框(图a)关注形式 , 统一于同一架构内 , 既不削弱语言链式推理 , 又充分释放扩散生成对全局依赖的需求 。
图文交织训练 , 长上下文对齐训练—推理闭环:
为提升长上下文理解与生成能力 , 模型采用“图文交织”的训练范式 。 训练序列中可包含多个用于扩散建模的加噪图像;而在推理阶段 , 一旦某张图像完成去噪即转化为“干净的条件图” , 因此推理过程中最多仅存在一个加噪图 。
为保证训练与推理的一致性 , 模型在交织数据上使用图b所示的专用attention mask:它禁止序列中部的加噪图被其后的token访问 , 同时为每个加噪图紧随配置一个干净条件图 。 该机制确保了多图训练的有效性与单图推理的稳定性 , 显著增强了跨段落、跨回合的上下文保持与生成连贯性 。
二维位置编码HunyuanImage 3.0是基于一个Hunyuan-A13B的LLM引入图像模态训练而来;因此LLM中的一维位置编码(1D RoPE)扩展为二维位置编码(2D RoPE) 。
同时 , 为了保证扩展时完全兼容原来文本token的一维编码 , 文本的位置坐标从123…扩展为(11)(22)(33)…记不同维度上的频率为θ0θ1θ2…那么位置n的文本token的位置编码可以表示为[cos(nθ0)cos(nθ1)cos(nθ2)…[sin(nθ0)sin(nθ1)sin(nθ2)…
。
在此基础上 , 二维坐标(xy)的位置编码为[cos(xθ0)cos(yθ1)…sin(xθ0)sin(yθ1)…
, 注意这样的位置编码对于坐标的x维度和y维度是不对称的 , 不过由于图片数据本身在两个维度上也是不对称的 , 因此这不会带来负面影响;而这样的不对称性允许二维位置编码可以完全兼容一维位置编码 , 这可以最大程度地保持原始LLM的语言能力 。
数据处理流程数据处理方面 , 采用了一个全面的三阶段过滤流程 , 从超过100亿张原始图像中筛选出近50亿张高质量、多样化的图像 , 移除了包括低分辨率、水印、AI生成内容在内的低质量数据 , 并补充了知识增强、文本相关等专业数据集 。
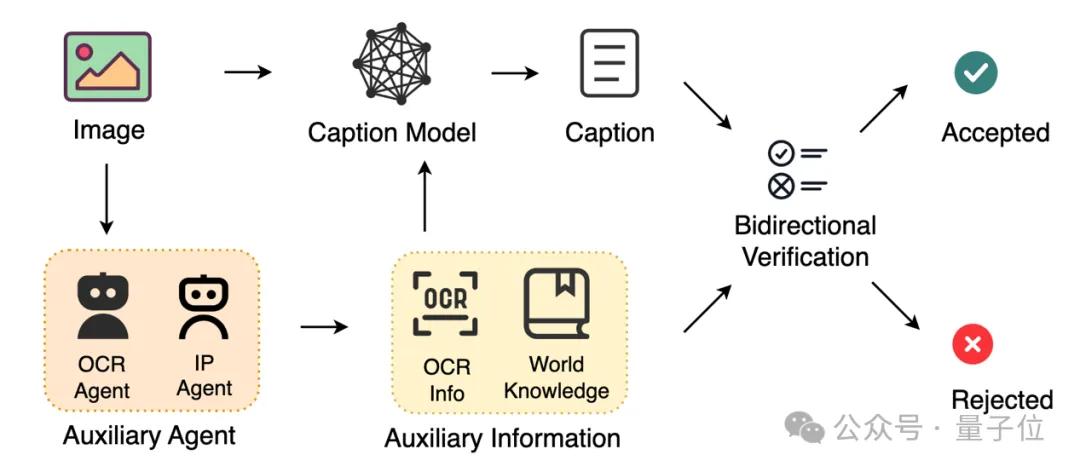
在图像描述上 , 构建了一套新颖的中英双语、分层级的描述体系 , 将图像内容分解为从简到详的描述、风格属性和事实实体等多个维度 , 并利用组合式合成策略来动态生成长度和模式各异的标题 , 以增强数据多样性 。
为保证描述的真实性 , 该系统集成了专门的OCR(文字识别)和命名实体识别代理来提供事实依据 , 并通过双向验证循环进行核对 , 此外还针对成对的图像数据开发了差异描述功能 , 用以生成描述变化的文本 。
推理数据构建方面 , 为了激活模型的“思维链”(Chain-of-Thought)能力 , 团队还专门构建了推理数据集 , 包括用于增强逻辑推理的“文本到文本”(T2T)数据 , 以及将图像与推理过程和详细描述配对的“文本到文本到图像”(T2TI)数据 , 旨在训练模型自主地完成从理解用户意图、进行概念优化到最终生成图像的全过程 。
多阶段训练策略训练始于一个渐进式的四阶段预训练 , 该过程从较低的256像素图像分辨率和基础的图文对与纯文本数据开始 , 逐步将VAE处理的分辨率提升至512像素乃至1024像素 , 并在高分辨率阶段引入了如图像编辑、多图融合等更复杂的交错图文数据(INTL)以及用于激发推理能力的思维链数据(CoT) 。
预训练之后 , 模型进入指令微调阶段 , 此时训练数据的类型从海量的多任务数据转变为使用特定模板格式化的、更聚焦于文本到图像生成任务的指令数据 , 旨在专门强化模型遵循用户具体创作意图的能力 。
最后 , 在多阶段的后训练中 , 数据类型进一步演变为人类偏好数据 , 包括用于监督微调(SFT)的精选高质量样本、用于直接偏好优化(DPO)的优劣图像对 , 以及为多种强化学习算法(MixGRPOSRPOReDA)提供指导的奖励模型信号 , 从而实现对生成结果的精细打磨 。
模型测评效果HunyuanImage 3.0采用了机器指标(SSAE)和人工评测(GSB)两种方式评估模型效果 。
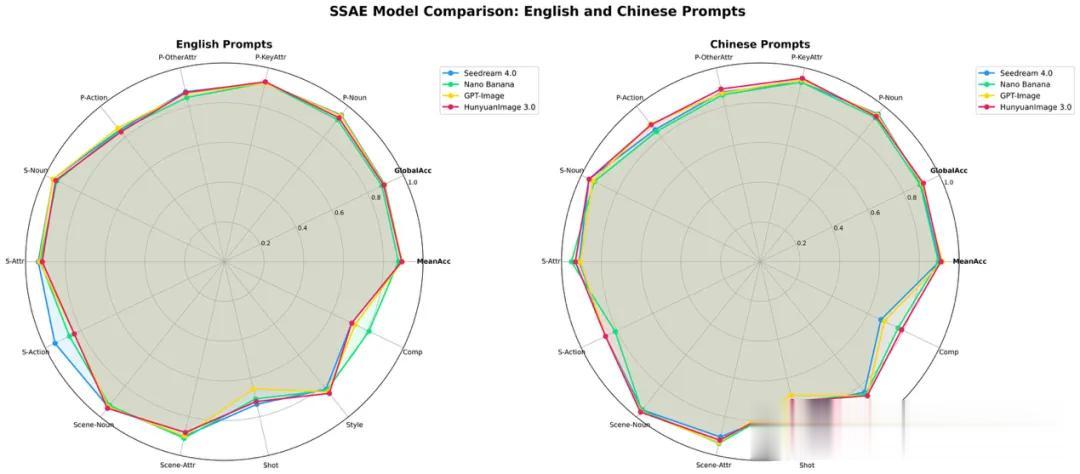
SSAE(Structured Semantic Alignment Evaluation)是一项基于多模态大语言模型(MLLM)的自动化评测指标 , 用于评估文生图模型的语义一致性 。 该指标精心构建了500道评测题目 , 并将每道题目按12个细分要点进行拆解 , 最后借助MLLM自动比对生成的图像内容与是否与拆解的要点匹配 。
最终输出两个结果:平均图像准确率(图像层级的平均分数 MeanAcc)和全局准确率(所有要点的平均得分 GlobalAcc) 。 可以看到 , HunyuanImage 3.0在最终结果和各细分要点上都媲美甚至超越业界领先的模型 。
在人工评测GSB(Good/Same/Bad)中 , HunyuanImag 3.0相较于Seedream 4.0胜率为1.17% , 相较于Nano Banana胜率为2.64% , 相较于GPT-Image胜率为5.00% , 相较于目前最好的上一版本模型HunyuanImage 2.1胜率为14.10% , 这表明HunyuanImage 3.0是足以媲美业界领先闭源模型的开源模型 。
开源仓库:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0HF:https://huggingface.co/tencent/HunyuanImage-3.0提示词手册:https://docs.qq.com/doc/DUVVadmhCdG9qRXBU技术报告:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0/blob/main/assets/HunyuanImage_3_0.pdf官网:https://hunyuan.tencent.com/image/zh?tabIndex=0
— 完 —
量子位 QbitAI · 头条号签约
【可能是目前效果最好的开源生图模型,混元生图3.0来了】关注我们 , 第一时间获知前沿科技动态
推荐阅读












- 7500mAh+双屏显示+骁龙8Elite Gen5,这可能是今年最爽的手机
- 目前“最值得捡漏”的华为手机,16G+512G降价4600元,价格大跳水
- 别被参数骗了!手机这几个“高配置”里面可能有大坑
- 罗永浩为小米辩护:宣传小字是行业通病,非小米独创
- 不是很懂,雷总掏空家底做出来的芯片为什么没有大规模铺货在小米17系上?
- iPhone 17e再次被确认:60Hz屏幕+A19芯片,会是性价比之选吗?
- 一加Ace 6参数被确认:骁龙8 Elite+165Hz高刷,或是同档唯一!
- ??“刻意做烂”的真相:手机非主业,传感器才是赚钱利器
- 阿里云是AI 时代的“安卓” 谁是 AI 时代的“苹果”
- 强抗反画质王者TCL T7L Ultra,简直是追剧党的最佳拍档!