
文章图片
文章图片

文章图片

文章图片
文章图片

文章图片
文章图片

文章图片
本文由半导体产业纵横(ID:ICVIEWS)编译自technews
谁能率先突破传输效率与延迟的限制 , 谁就有机会在下一波AI竞赛中夺得先机 。
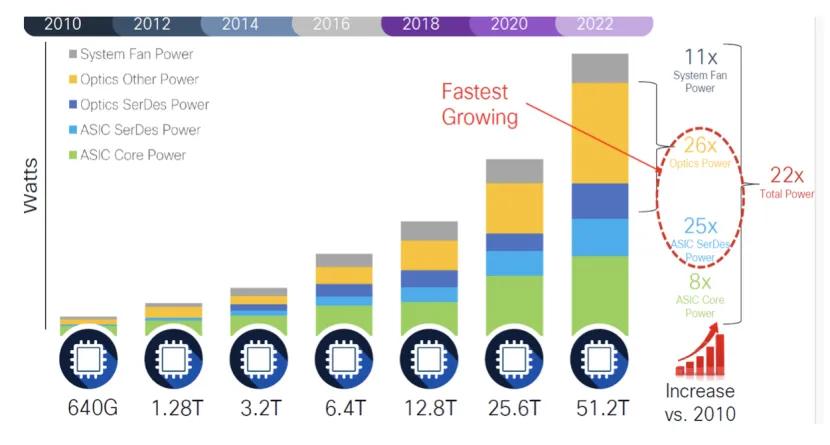
在人工智能(AI)、机器学习的推动下 , 全球数据流量正成倍增长 , 目前数据中心服务器与交换机之间的连线正从200G、400G快速迈向800G、1.6T , 甚至可能进入3.2T的时代 。
市场调研机构TrendForce预测 , 2023年400G以上的光收发模组全球出货量为640万个 , 2024年约2040万个 , 预计至2025年将超过3190万个 , 年增长率达56.5% 。 其中 , AI服务器的需求持续推升800G及1.6T的成长 , 而传统服务器也随着规格升级 , 带动400G光收发模组的需求 。
另据机构调查 , 2026年1.6T光模组需求将大幅超出预期 , 总出货量预计高达1100万支 , 主要动力来自NVIDIA与Google的强劲采购 , 以及Meta、微软、AWS的部分需求 。
光通信因为高带宽、低损耗与长距离特性 , 逐渐成为机柜内外互连的主要选择方案 , 使得光收发模组成为数据中心互连的关键 。 TrendForce指出 , 未来AI服务器之间的数据传输 , 都需要大量的高速光收发模组 , 这些模组负责将电信号转换为光信号 , 并通过光纤传输 , 以及将接收到的光信号转换回电信号 。
光收发模组、光通信和硅光子有何关系?根据下图的前两个示意图可知 , 目前市面上的可插拔光收发器传输速率可达 800G , 下一阶段的光引擎( Optical Engine, 简称OE) 已经可安装在ASIC芯片封装周围 , 这称为载板光学封装( On- Board Optics, 简称OBO) , 其传输能力可支援至1.6T 。
目前业界希望走向“CPO”(Co-packaged Optics , 共封装光学) , 即光学元件与ASIC能共同封装 , 通过这项技术实现超过3.2T、最高达12.8T的传输速度;而最终目标则是达到“Optical I/O”(光学I/O) , 实现类似全光网络的技术 , 推动传输速度超过12.8T 。
如果仔细观察上图 , 可以发现作为黄色方块的光通信模组(以前为可插拔形态)距离ASIC越来越近 , 这主要是为了缩短电信号的传输路径 , 从而实现更高的带宽 。 而硅光子制程技术 , 就是将光学元件整合到芯片上的技术 。
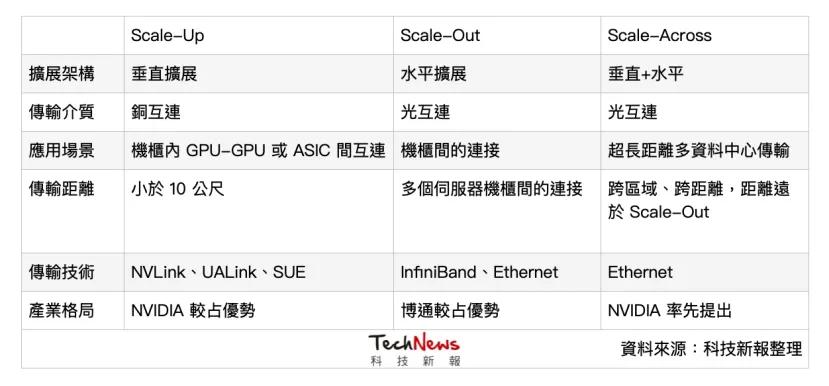
光通信需求暴增 , 业界聚焦三种扩展服务器架构由于AI应用大爆发 , 对于高速光通信的需求急剧提升 , 目前服务器主要聚焦Scale Up(垂直扩展)、Scale Out(水平扩展)两种扩展方向 , 分别对应不同的传输需求与技术挑战 , 而近期NVIDIA又新宣布“ScaleAcross”这个概念 , 为业界增添一个思考方向 。
Scale-Up
Scale-Up主要作为机柜内高速互连(上图黄色部分) , 传输距离通常在10公尺以内 , 由于对延迟的要求极低 , 内部仍主要采用“铜互连”(Copper Interconnects) , 避免光电转换造成延迟与能耗 。 目前解决方案主要有NVIDIA的NVLink(封闭架构)及AMD等其他公司主导的UALink(开放架构) 。
有趣的是 , 今年NVIDIA推出NVLink Fusion , 首度开放NVLink技术给外部芯片厂商 , 将NVLink从单一服务器节点延伸至整个机柜级(Rack-Scale)架构 , 不排除是为了因应UALink的竞争 。
另一个值得关注的是 , 原本主要专注于Scale-Out的博通 , 正尝试通过“以太网”(Ethernet)进军Scale-Up市场 。 该公司近期推出多款可用于Scale-Up、符合SUE(Scale-Up Ethernet)标准的芯片 , 后续可以关注NVIDIA与博通在这方面的竞争 。
Scale-Out
Scale-Out则是横跨服务器的大规模并行运算(上图中蓝色部分) , 用于解决数据高吞吐量问题并实现无限扩充 。 这以“光通信”为主 , 主要的网络互联技术依靠InfiniBand或者以太网(Ethernet) , 也将带动光通信模组市场 。
InfiniBand和Ethernet又可以分成两大阵营 , 前者较受NVIDIA 、微软等大厂的青睐 , 而后者则以博通、 Google 、 AWS为主 。
谈到InfiniBand , 不得不提领先厂商Mellanox , 它在2019年被NVIDIA收购 , 是提供端到端Ethernet与InfiniBand智能互连解决方案的供应商 。 而中国近期裁定NVIDIA违反反垄断法 , 就是针对这起收购案 。 另一个关注点是 , 虽然NVIDIA推出许多InfiniBand产品 , 但也针对以太网推出相关产品如NVIDIA Spectrum-X , 可以说是两种市场兼吃 。
作为另一大阵营如英特尔、AMD、博通等大厂于2023年7月集结组成“超以太网联盟”(Ultra Ethernet Consortium, 简称UEC) , 合作发展改进的以太网传输堆栈架构 , 成为挑战InfiniBand的力量之一 。
TrendForce分析师储于超认为 , Scale Out所带动的光通信模组市场 , 正是未来数据传输的核心战场 。
Scale-Across
作为新兴的解决方案 , NVIDIA近期提出“Scale-Across”的概念 , 即跨数据中心的“远距连接” , 距离能超过数公里 , 并推出以以太网为基础、串接多座数据中心的Spectrum-XGS以太网 。
Spectrum-XGS以太网将作为AI运算中Scale-Up和Scale-Out以外的第三大支柱 , 主要用来扩展Spectrum-X以太网的极致效能与规模 , 可连接多个分散式数据中心 。 NVIDIA介绍 , NVIDIA Spectrum-X以太网除了提供Scale-Out的架构 , 连接整个集群、将多个分散式数据中心进行互连 , 快速将大量数据集串流至AI模型 , 还可在数据中心内协调GPU与GPU之间的通信 。
换言之 , 这个解决方案结合Scale-Out与跨域扩展 , 能根据跨域距离灵活调整负载平衡、动态调整算法 , 因此概念更类似“Scale-Across” 。
NVIDIA创办人暨执行长黄仁勋表示 , “我们在Scale-Up与Scale-Out能力之上 , 进一步加入Scale-Across , 把跨城市、跨国家乃至跨洲际的数据中心联结起来 , 打造庞大的超级AI工厂 。 ”
如果从目前产业走向来看 , Scale-Up和Scale-Out都是必争之地 , 可以看出NVIDIA和博通如何从对方手中夺取多一分领地 。 而NVIDIA新喊出的Scale-Across则是聚焦横跨数公里乃至于数千公里的跨数据中心传输 , 有趣的是 , 博通也有推出相关的解决方案 。
事实上 , 现在AI产业的竞争除了芯片间的竞争外 , 更是扩大到系统间解决方案的竞争 。
博通与NVIDIA的第一个交集就是“定制化AI芯片”(ASIC) 。 由于NVIDIA GPU价格高昂 , 包括Google、Meta、亚马逊、微软等云端服务供应商(CSP)都在开发自家AI芯片 , 而博通的ASIC能力成为这些公司的首要选择 。
除了自研芯片的竞争外 , 另一个更关键技术是“网络连接技术” , 这也是博通与 NVIDIA 的第二个交集 。
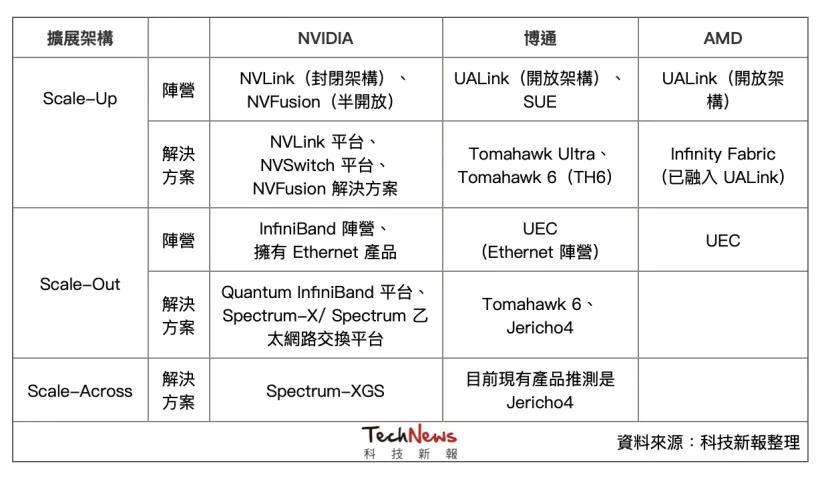
首先是在Scale-Up部分 , 在NVLink和CUDA这两大护城河守护下 , 博通酝酿了多时 , 终于在今年推出最新的网络交换机芯片Tomahawk Ultra(战斧) , 有机会切入Scale-Up市场 , 目标挑战NVIDIA NVLink的主导地位 。
Tomahawk Ultra是博通一直推动的“纵向扩展以太网”(Scale-Up Ethernet , 简称SUE)计划的一部分 , 这个产品也被视为NVSwitch的替代方案 。 博通表示 , Tomahawk Ultra一次可串联的芯片数量是NVLink Switch的四倍 , 将交由台积电5纳米制程 。
值得注意的是 , 博通虽然身为UALink联盟成员之一 , 但它也积极推广基于以太网SUE架构 , 因此市场也相当关注博通与UALink的竞合关系 , 以及如何共同应对NVLink这个大敌 。
为了抵御博通强袭 , NVIDIA今年也推出 NVFusion 解决方案 , 开放合作伙伴如联发科、Marvell、Astera Labs等共研 , 并通过NVLink生态系打造客制化的AI芯片 。 外界认为 , 这是为了巩固生态系而进行的半开放式合作 , 也给更多合作伙伴一些客制化空间与机会 。
Scale-Out方面 , 主要由在以太网领域深耕已久的博通占据主导 , 近期最新推出的产品包括Tomahawk 6、Jericho4 , 以抢占Scale-Out和更远传输距离的商机 。
而NVIDIA则推出许多Quantum InfiniBand交换机产品 , 以及Spectrum以太网交换平台 , 加强更多面向的Scale-Out产品 。 虽然InfiniBand属于开放架构 , 但因产品生态环境主要仍由NVIDIA收购的Mellanox所主导 , 限制了客户的选择灵活性 。
根据博通的相关数据 , 三款产品各自横跨两种不同的服务器扩展架构 。
针对更长距离的跨数据中心扩展的Scale-Across , 目前还不确定博通和NVIDIA谁会领先 , 不过NVIDIA针对这一概念率先推出Spectrum-XGS , 该解决方案通过新的网络算法 , 来实现站点之间更远距离的数据有效移动 , 也可以作为现有Scale-Up和Scale-Out架构的补充方案 。
至于博通的Jericho4也符合Scale-Across的概念 。 博通指出 , Tomahawk系列芯片能串联单一数据中心内的机柜 , 连接距离通常不超过一公里(约0.6英里) , 而Jericho4设备则能处理超过100公里的跨机房连接 , 维持无损RoCE传输 , 其数据处理能力约为前一代产品的四倍 。
那么NVIDIA 和博通的CPO 解决方案?随着网络传输战场持续 , 相信在光网络的竞争将会更加激烈 , 对此NVIDIA和博通都针对CPO光通讯找寻新解方 , 而台积电、格罗方德也积极开发用于CPO的制程与解决方案 。
NVIDIA的策略是以系统架构为出发点 , 并将光学互连视为SoC的一部分 , 而非外挂式模组 , 并于今年 GTC正式发表Quantum-X Photonics InfiniBand交换器和Spectrum-X Photonics Ethernet交换器 , 前者将于年底推出 , 后者则于2026年问世 。
两个平台均采用台积电COUPE平台 , 通过SoIC-X封装技术将65纳米的光子积体电路(PIC)与电子积体电路(EIC)整合 。 而这个策略出发点 , 是为了强调自家平台整合 , 加强整体效益与规模扩展 。
博通的策略则专注于提供全方位解决方案 , 聚焦在供应链的规模化运作 , 供应第三方客户完整的模组化方案 , 帮助客户应用落地 。 博通也表示 , 公司之所以在CPO领域成功 , 是建立在深厚的半导体与光学技术整合能力之上 。
博通目前推出第三代200G / lane CPO抢市 。 博通也表示 , 其 CPO产品采用3D芯片堆叠架构 ,PIC同样使用65纳米 ,EIC则采用7纳米制程 。
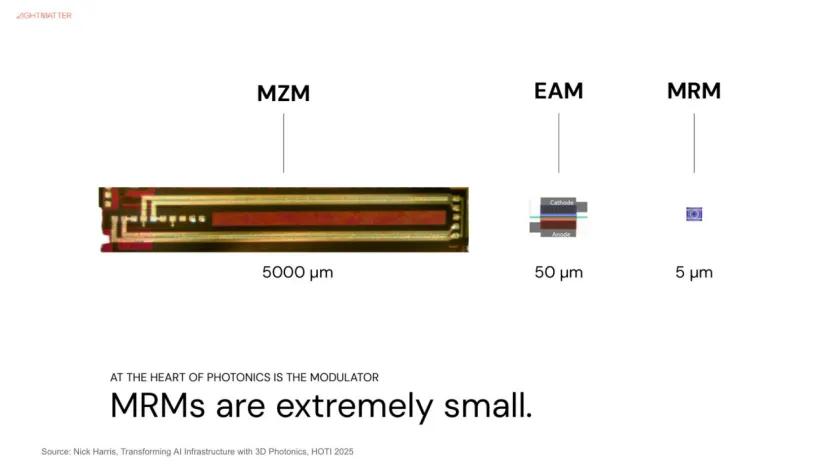
由下图可知 , 光收发模组由以下关键元件组成 , 如雷射光源(Laser Diode )、光调变器( Modulator )、光感测器( Photo Detector )等 。 其中 , 雷射光源负责产生光信号 , 光调变器负责将电信号/数位信号转成光信号 , 因为涉及电光转换 , 也可以说是决定单通道传输速度的关键 。
在关键的光调变器上 , NVIDIA选择MRM (微环调变器 ,Micro-Ring Modulator ) 。 由于MRM尺寸较小 , 容易受误差及温度影响 , 也将是导入MRM的挑战之一 。
至于博通 , 则选择使用技术较成熟的MZM调变器(马赫–曾德尔调变器 ,Mach-Zehnder Modulator ) , 同时布局 MRM 技术 , 目前已经通过3 纳米制程试产 , 并以芯片堆叠方式 , 持续领导CPO 进展 。
目前在AI推论持续扩张浪潮下 , 市场焦点已逐渐从“算力竞赛”转向“数据传输速度” , 无论是博通主打的网络与交换技术、NVIDIA推动的端到端解决方案 , 谁能率先突破传输效率与延迟的限制 , 谁就有机会在下一波AI竞赛中夺得先机 。
*声明:本文系原作者创作 。 文章内容系其个人观点 , 我方转载仅为分享与讨论 , 不代表我方赞成或认同 , 如有异议 , 请联系后台 。
【CPO赛道对决!NVIDIA、博通到底在竞争什么?】想要获取半导体产业的前沿洞见、技术速递、趋势解析 , 关注我们!
推荐阅读











- 影石杀入AI录音硬件赛道,2198元起和科大讯飞直接竞争
- 面对千亿美元赛道,北京三次押重注在最早专注AR眼镜的亮亮视野
- 扎克伯格宁愿浪费数千亿也不愿错过AI赛道,互联网大厂砸了多少钱
- 2025年最强三芯孰强孰弱?骁龙、天玑和苹果处理器的年度对决总结
- 高端泳池机器人品牌星迈创新完成10亿元融资,正式入局割草赛道|硬氪独家
- 央视撒贝宁探厂刷屏:天马用天工屏给OLED换了一条新赛道!
- 大疆运载,被低估的“超级赛道”
- 从造车到造“人”:奇瑞招商在即,车企抢占机器人赛道
- 联发科连放两记重锤:天玑9500抢先亮相,天玑9600瞄准2nm新赛道
- 小红书杀入本地生活到店赛道,或将在10天后正式上线