
文章图片
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
文章图片
文章图片

文章图片
编辑:KingHZ
【新智元导读】AI下半场 , AGI已成过去式 , ASI正引领新智能革命!OpenAI推出的GDPval评估体系 , 通过真实工作任务审视大模型潜力 , 揭示AI如何从实验室走向3万亿经济战场 , 助力人类从日常琐事中解放 , 拥抱创造性未来 。
AI下半场真来了!
AGI都过时了 , 现在AI业内讨论的是超级人工智能ASI:
AGI能把人类从80%的日常工作中解放出来;
而ASI则全面超越人类智能的系统 。
刚刚 , 在a16z访谈中 , OpenAI首席科学家Jakub Pachocki , 透露OpenAI的研究路线图的下一步是推理 , 下一个5年的重点目标是打造自动化研究人员:
AI自动发现新想法 , 自动化研究人员的工作 , 自动化机器学习研究 。
但理解AI潜力最清晰的方式 , 并不是预测未来 , 而是看看模型现在已经能做什么 。
历史经验告诉我们 , 从互联网到智能手机 , 每一项重大技术从诞生到普及都需要十年以上 。
OpenAI希望以更透明的方式 , 展示大模型如何真正服务于现实世界 。
因此 , 他们推出了一项全新的评估体系GDPval , 在有据可依的基础上审视AI进步轨迹 , 而不是凭空臆测 。
论文地址:https://cdn.openai.com/pdf/d5eb7428-c4e9-4a33-bd86-86dd4bcf12ce/GDPval.pdf
数据集:https://huggingface.co/datasets/openai/gdpval
在GDPval 上 , 专家评审员将顶尖模型的输出与人类专家的工作进行了比较 。
哈佛大学教授、名誉校长Lawrence H. Summers——同时任OpenAI的董事会成员 , 认为新研究令人兴奋:
在多项实际任务上 , 即使只有有限的指导 , AI的表现与人类相当甚至更好;
人类与人·工智能结合 , 可以更高效;
AI具有令人惊讶的能力 , 可用来评估并随后改进其性能 。
OpenAI坦承:Claude Opus 4.1表现最佳 , 在接近一半的任务上与专家工作相当或更好 , 明显优于GPT-5 。
但OpenAI的进步速度引人注目:在一年内 , GPT系列模型胜率几乎翻了一番 。
GDPVal
衡量AI的3万亿美元影响
过去 , 大模型评估往往集中在学术测试或编程挑战上 。
这些评估虽然在推动模型推理能力方面起到了重要作用 , 但与现实工作场景仍有一定距离 。
为了填补这道鸿沟 , OpenAI逐步开发出一系列更贴近实际、更具经济意义的评估方法——
从传统的MMLU(涵盖多学科的考试型题目) ,
到更具实战意味的SWE-Bench(软件工程Bug修复任务)、MLE-Bench(机器学习工程任务 , 如模型训练与分析)、Paper-Bench(科研论文的逻辑推理与评议) ,
再到基于市场项目的SWE-Lancer(源于真实交易的自由职业软件开发任务) 。
GDPval正是在这一演进路径上的下一个关键节点 。
这项评估直接来源于现实工作中的任务 , 覆盖了9大行业、44种职业、每年共计3万亿美元经济价值 。
整个任务集共包含1320个高度专业化任务(其中220为金标任务子集 , 已开源) 。
这些任务源于真实工作产出 , 比如法律意见书、工程图纸、客服对话记录或护理计划等 。
每一项任务都需通过多轮严格审核流程 , 确保其具备三点 , 即:高度贴近实际工作场景;可由同领域的专业人士独立完成;具备明确的评估标准 。
每项任务平均经历5轮专家评审 , 评审团队包括其他任务撰写者、独立职业评审专家 , 并辅以模型可行性与清晰度校验 。
GDPval的独特之处在于 , 不仅任务内容贴近现实、形式多样 , 还具备极高的专业性和代表性 。
与传统评估相比 , GDPval并非简单的文本提示任务 。 它要求模型处理完整的参考材料与工作背景 , 输出形式也不仅限于文字 , 还包括文档、PPT、图表、电子表格 , 甚至多媒体内容 。
当然 , GDPval目前还只是一个起点 , 尚未完全覆盖现实知识工作中任务的复杂性 。
它帮助我们清晰地认识到 , 大模型不仅仅能在实验室中解题 , 更可能在千千万万人的日常工作中 , 扮演可靠的辅助角色 。
请再读一遍:AI不再只是「通过考试」 , 而是开始接受文明体系本身的考核标准:GDP 。
独立研究员Shanaka Anslem Perera表示:
这不仅仅是一套评估体系 , 更像是某种经济生命体的诞生。
GDPval , 是「后人类经济时代」的第一套会计体系 。
【OpenAI 3万亿美元测试,AI首战44个行业人类专家!】
今天 , 它是一个「基准」;明天 , 它将成为新物种的记分牌 。
当AI的产出开始计入GDP , 它就不再是工具 , 而是超越「土地、劳动与资本」的第四种生产要素
半数任务
AI已逼近专业水平
早期测试结果显示 , 当前领先的大模型在某些任务上 , 表现已接近甚至媲美行业专家 。
在220项金标任务中 , 行业专家盲测了多款主流模型:
GPT-4o、o4-mini、OpenAI o3、GPT-5、Claude Opus 4.1、Gemini 2.5 Pro、Grok 4 。
结果显示:
- Claude Opus 4.1在美学表现方面表现最强(如文档排版、PPT布局等);
- GPT-5则在准确性方面领先 , 尤其擅长定位专业知识点 。
在接近一半的任务中 , 其产出被评为「与人类一样好」甚至「优于人类」 。
从GPT-4o(2024年春发布)到GPT-5(2025年夏发布) , 模型在GDPval任务上的平均表现几乎翻倍 , 呈现出明显的线性进步趋势 。
OpenAI还发现 , 顶尖模型完成GDPval任务的速度和成本 , 平均是人类的1%——约快100倍、便宜100倍 。
不过 , 这一数据仅统计了模型推理时间与API调用成本 , 并未包含人类监督、迭代修改与实际集成等现实工作流程所需的资源投入 。
尽管如此 , 在模型表现尤为出色的任务类型上 , 先用AI试一轮 , 再交由人类介入 , 可能成为节省时间与成本的理想策略 。
如何优化模型以提升GDPval表现
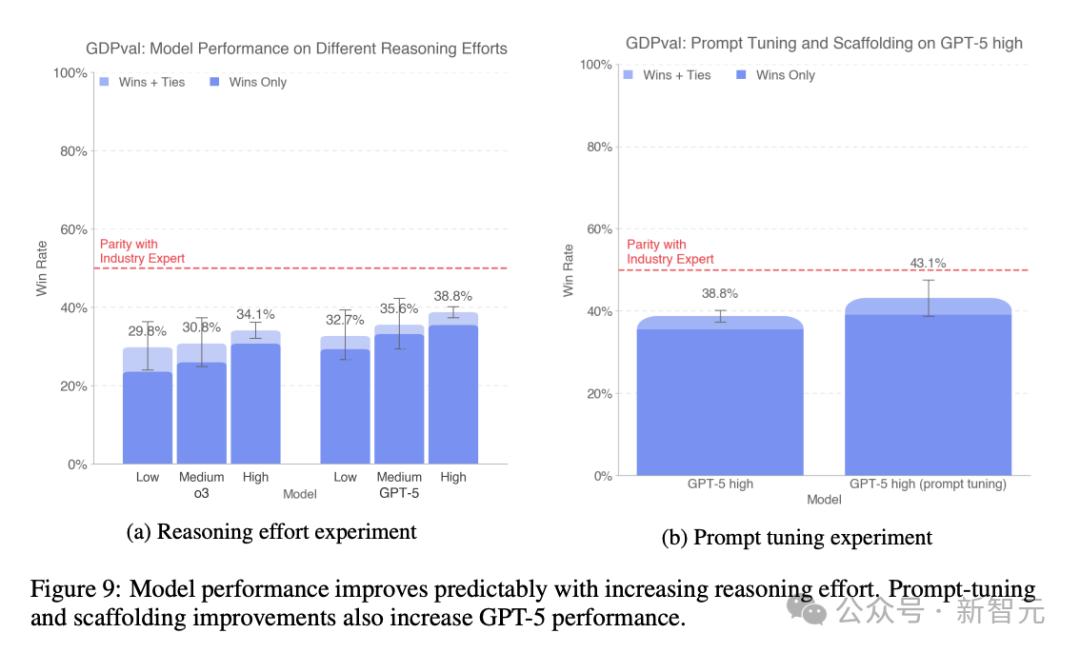
为了验证是否可以提升GPT-5在GDPval任务中的表现 , OpenAI增量训练了实验性的内部特定版GPT-5 。
结果证实 , 经过该训练流程后 , 模型性能确实得到了实质性提升 , 展现了进一步优化的潜力 。
下图的多项受控实验结果 , 进一步印证了这一点:扩大模型规模、引导模型进行更多推理步骤、提供更丰富的任务背景信息 , 都会带来可衡量的性能增益 。
OpenAI设计了一条通用提示词 , 要求模型在提交结果前进行严谨的自检 , 可适用于各类多模态经济类任务 , 并未针对具体问题进行过拟合 。
最豪评分员
顶尖机构的14年行业专家
在GDPval任务中 , 为了评估模型的实际表现 , OpenAI依赖资深从业者作为「评分员」 。
专家入选标准包括:至少4年行业从业经验 , 且简历中需体现专业认可度、晋升轨迹及管理职责 。 参与本项目的专家平均拥有14年从业经验 。
行业专家团队曾任职于以下代表性机构:
Meta、微软、摩根士丹利、谷歌、甲骨文、苹果、通用电气、高盛、HBO、IBM、摩根大通、领英、洛克希德·马丁、美国银行、巴克莱银行、波音、美国疾控中心、花旗集团、美国国防部、美国联邦贸易委员会、美国国家公园管理局、NFL网络、雷神、Sally Beauty、《科学美国人》、苏富比、英国电讯报集团、赛默飞世尔、《时代》杂志、美国司法部、美国空军、美国邮政总局……
这些评分员来自与任务相同的职业背景 , 并在不知晓「人类 vs AI」身份的前提下 , 盲评由模型与人类任务撰写者完成的任务成果 。
他们不仅会给出评价 , 还会对比排名 , 最终判断每个AI生成结果是「优于」、「相当于」或「劣于」人类结果 。
为了确保评分过程透明一致 , 每位任务撰写者还为其职业领域制定了详细评分标准(rubric) , 涵盖各类评价维度 。
OpenAI还开发了「自动评分器」——一个用于预测人类专家偏好的AI系统 , 模仿行业专家的对比评估方式 。
自动评估工具比专家评估更快、成本更低 , 且与人类专家评估的一致性达到66% , 仅比人类评估者之间71%的一致性低5% 。
由于其局限性 , OpenAI没有使用自动评分器取代人类打分员 。
AI与工作的未来图景
随着AI能力不断提升 , 劳动力市场势必将发生结构性变化 。
GDPval的早期结果已经表明 , 大模型在处理那些重复性强、结构清晰的任务时 , 效率远超人类专家 , 不仅更快也更便宜 。
但也要看到 , 大多数工作不仅仅是可拆解的任务清单 。
GDPval的意义在于:它揭示了AI可以承接哪些日常性事务型任务 , 从而为人类腾出时间专注更具创造力、判断力的复杂工作 。
当AI能够以这种方式补充而非替代人类时 , 将为经济增长释放巨大潜力 。
OpenAI希望借助GDPval与相关工具 , 推动AI工具的普及平民化 , 支持劳动者顺利适应时代变革 , 并打造能鼓励广泛参与与共享成果的激励机制 。
同时 , OpenAI也开放了GDPval金标任务子集以及一个公共评分平台 , 希望能为更多研究者提供基础设施 , 持续推动该方向的发展 。
愿每个人都能搭上AI时代的「上行电梯」 。
推荐阅读















- 刚刚,Meta挖走OpenAI清华校友宋飏,任超级智能实验室研究负责人
- 马斯克与OpenAI再生纠葛 旗下xAI指控对方窃取商业机密
- 再见了,英伟达!500亿美元中国市场对美芯关门,比尔盖茨预言成真
- 突发!Meta刚从OpenAI挖走了清华校友宋飏
- 贝恩:AI企业8000亿美元收支缺口,如何创造收入弥补支出是个难题
- AI芯片厂商Groq完成7.5亿美元融资,投后估值69亿美元
- 英伟达千亿美元投资OpenAI,意在维持AI泡沫不破?
- 鸿蒙智行93万车主迎来最重磅OTA升级:30+项体验优化
- 卖出550万枚智能戒指!可穿戴黑马被曝新融资,冲刺百亿美元估值
- 全是套路!英伟达千亿投OpenAI,奥特曼拿钱买卡还让甲骨文赚差价