
文章图片

文章图片
文章图片
文章图片
语音交互作为人机通信的关键接口 , 长期以来受限于高延迟、低自然度的交替式对话架构 。 为突破这一瓶颈 , 北京智源人工智能研究院联合 Spin Matrix 与新加坡南洋理工大学 , 正式发布 RoboBrain-Audio(FLM-Audio) —— 首个支持 “自然独白 + 双训练范式” 的原生全双工语音对话大模型 。
RoboBrain-Audio 采用原生全双工 (Native Full-duplex) 架构 , 相比传统的 TDM(时分复用)模型在响应延迟、对话自然度上实现飞跃式提升 , 同时语言理解能力显著强于其他原生全双工模型 , 标志着具身智能体从 “能听会说” 向 “边听边说” 的交互能力跃迁 。
根据公开数据 , 当前业界训练音频基座模型时使用的数据量已达到上千万乃至上亿小时 , 这些模型在音色克隆和长回复生成上更具优势 , 而 RoboBrain-Audio 仅使用 100 万小时 (业界数据量的 1%) 数据训练 , 不但回复质量满足日常交互需求 , 而且具有响应模式更为敏捷自然等优势 , 尤其适配具身场景 。 RoboBrain-Audio(FLM-Audio)相关论文已公开发布 , 模型与代码均已开源 。
论文链接:https://arxiv.org/abs/2509.02521 Hugging Face 模型页:https://huggingface.co/CofeAI/FLM-Audio GitHub 代码库:https://github.com/cofe-ai/flm-audio为什么必须是 “原生全双工”?
从 TDM 到同步对话的演进
现有的语音对话模型 , 例如 Kimi-Audio MiMo-Audio 等 , 多采用时分复用(TDM) 架构 , 即将听、说、文本等多个通道的输入和输出交织在同一序列中处理 。 虽然实现简单 , 但这种交织会使主模型总序列长度过长 , 计算开销随通道数急剧增加 。 同时 , TDM 不善于处理实际、开放场景中快速变化的输入:当用户频繁打断时 , 模型的反应延迟受限于外部 chunk 机制 , 通常高达 2 秒 , 更无法实现 “边听边说” 等更类人的响应模式 。 这些因素都限制了 TDM 架构的实时交互体验 。
相反 , 原生全双工(Native Full-Duplex )架构(如 Moshi)将多通道信息在每一时间步合并处理 , 也就是支持 “边听 , 边想 , 边说” , 不但避免了序列长度爆炸 , 而且可以将打断响应的延迟降至最低 80ms 级别 。 然而 , 当前的原生全双工模型依赖词级对齐策略 , 需为每个词标注精确的语音时间戳 , 并将连续的文本 token 打散 。 该策略不仅成本高昂 , 还会破坏预训练语言模型的能力 , 导致指令跟随性能下降 。
RoboBrain-Audio(FLM-Audio) 在采用最先进的原生全双工架构的基础上 , 彻底摆脱了 “词级对齐” 的工程枷锁 , 不再依赖高成本、易出错的精细时间标注 , 为模型训练效率与泛化能力打开新空间 。
核心创新:自然独白对齐 + 双训练
1. 自然独白:从 “词对齐” 到 “句对齐”
RoboBrain-Audio 弃用词级时间戳 , 创新性地在全双工实时框架下引入 “自然独白(Natural Monologue)” 对齐机制:
完整句子先生成 → 让语言模型自由发挥 , 不被 special token 阻断; 语音通道异步生成 → 按句异步朗读 , 类比人类 “先想后说”; 等待机制与打断处理 → 可被中断、可并发听说 , 支持真正的全双工交互; 只需句级标注 → 降低训练数据成本、避免精细对齐误差;这一设计保留了语言大模型在生成连贯性和指令理解上的天然优势 , 使模型更自然、更强大 。 此外 , 自然独白机制还有效解决了部分词语(尤其是数字)的上下文依赖性发音问题 。 在传统词级对齐策略中 , 模型往往需要在词刚被解码时立即输出对应语音 , 这会导致在缺乏完整上下文时出现错误发音(如 “2025” 可能读作 “两千零二十五” 还是 “二零二五” 需依语境判断) 。 而自然独白允许模型先完成整个句子的文本生成 , 再统一决定最自然的语音表达方式 , 从而提升发音准确性和语言连贯性 , 避免 “听感割裂” 。
2. 语音新训练范式:后训练 + 有监督微调 , 构建 “听说能力” 全闭环
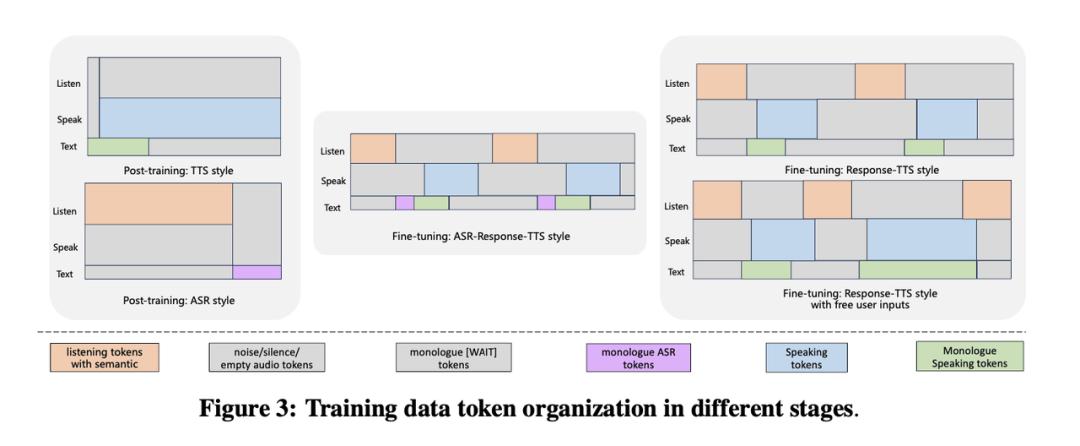
模型训练分为两个阶段 , 共四个子阶段 , 分别模拟语音识别(ASR)、语音合成(TTS)及交互对话任务:
后训练阶段(Post-Training):赋予模型 “听” 和 “说” 的基础能力
数据:在第一子阶段使用约 100 万小时音频 - 文本对 , 在第二子阶段额外引入开源人工精标对齐数据 。 双格式组织:同一份数据被组织成两种格式交替训练: TTS 风格(文本领先):文本通道先出现完整句子 , 语音通道延迟 2 个 token 开始输出 。 模拟语音合成(TTS) 任务 。 ASR 风格(语音领先):语音通道先出现输入音频 , 文本通道随后输出完整转录文本 。 模拟语音识别(ASR) 任务 。 目的:让模型同时掌握 “听写”(ASR)和 “朗读”(TTS)这两项核心技能 , 为后续的对话任务打下坚实基础 。有监督微调阶段(SFT):塑造对话与全双工能力
数据:使用 20 万条合成的高质量多轮对话数据 , 语音由 700 + 种人声通过 TTS 系统生成 。 核心子阶段: SFT-1(半双工过渡阶段):采用 “ASR-Response-TTS” 格式 。 模型先听完用户整句输入 , 将其转写为文本(ASR) , 再生成文本回复并转换为语音(TTS) 。 此阶段巧妙地融合了后训练学到的 ASR 和 TTS 能力 。 SFT-2(全双工最终阶段):采用 “Response-TTS” 格式 。 隐藏 ASR 监督信号 , 模型必须直接从音频输入理解用户意图 , 并生成回复 。 在此基础上 , 引入用户随机打断 , 模型学会在 0.5 秒内停止当前输出并响应新输入 , 从而获得全双工交互能力 。系统实验:ASR、TTS、对话性能在原生双工模型中全面领先
通过系列实验 , 科研人员系统性地评估了 RoboBrain-Audio 在音频理解、音频生成和全双工对话三个核心任务上的性能 , 并通过消融实验验证了其关键设计选择的有效性 。
1. 音频理解
该工作通过自动语音识别(ASR)和语音问答(Spoken QA)两项任务 , 在 benchmark 上进行评测 , 实验结果表明 , RoboBrain-Audio 在中文 ASR(Fleurs-zh)上优于非全双工架构的 Qwen2-Audio;在均使用原生全双工架构的前提下 , RoboBrain-Audio 使用更少的后训练数据在 LibriSpeech-clean 上显著优于 Moshi , 印证了自然独白和双训练的优势 。
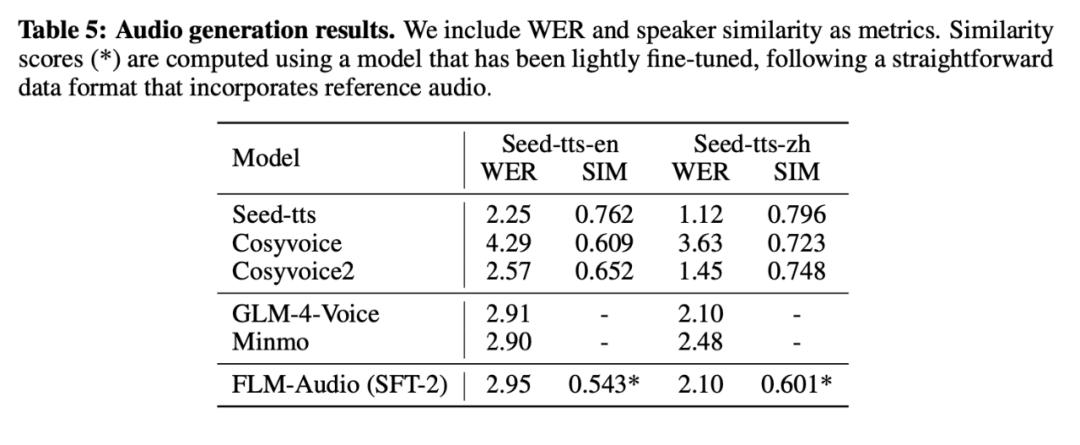
2. 音频生成
该工作通过文本转语音(TTS)任务 , 对模型的音频生成能力进行评测 。 分别在 Seed-TTS-en(英文)、Seed-TTS-zh(中文)两个数据集上进行模型能力的评估 。 RoboBrain-Audio 的 WER 与专业 TTS 模型(如 Seed-TTS、CosyVoice2)接近 , 表现优秀 。 SIM 分数较低 , 原因是其未针对音色克隆进行专门优化 。
3. 全双工对话
【智源研究院开源原生全双工语音大模型RoboBrain-Audio】该工作通过多轮语音对话任务 , 采取自动评估(使用 DeepSeek-V3 对回答质量评分(0–10))和人工评估(5 名标注员从 4 个维度评分(1–10))两种方式 , 与 Qwen2.5-Omni 模型(非原生双工)进行对比 。 RoboBrain-Audio 在生成文本内容质量接近的前提下 , 在流畅度、响应速度等用户体验相关指标上取得领先 , 体现了自然独白设计能够弥补原生全双工模型的文本能力短板 , 同时充分发挥其天然架构优势 。
RoboBrain-Audio 的生态意义:
丰富 RoboBrain 全栈体系 , 迈向具身智能体
对于 “原生全双工” 框架而言 , RoboBrain-Audio 的自然独白策略是对音频 - 文本对齐方式的根本性革新 , 而双训练范式则是确保这一策略成功实现的工程保障 。 两者结合 , 使模型在数据效率(更少的数据)、性能表现(更强的语言能力与更低的延迟)和用户体验(更自然的对话)上实现了全面突破 , 为构建真正智能的具身语音交互 Agent 提供了新的可复制范式 。
RoboBrain-Audio 并非孤立产品 , 是智源 RoboBrain 系列面向 “具身智能” 的关键能力载体:
已有的 RoboBrain 系列模型专注于具身感知、规划与操作; RoboBrain-Audio 赋能语音理解与自然语言交互; 两者结合 , 将加速构建 “听懂人话、看懂世界、动手做事” 的机器人智能体 。未来 , 团队将持续深度整合 RoboBrain-Audio 的强语音交互能力与 RoboBrain 在任务规划、物体感知等方面的能力 , 实现自然语音交互驱动下复杂任务的执行 , 持续提升机器人在导览导购、家庭等场景的服务效能 。
推荐阅读















- 首个代码世界模型引爆AI圈,能让智能体学会「真推理」,Meta开源
- 阿里又一大模型开源,手机电脑样样玩的溜,多项测试秒GPT-5
- 中国AI高速路,华为给出开源开放方案
- 阿里一夜扔出三个开源王炸,猛刷32项开源SOTA
- 腾讯智能体开源大动作!关键技术都拿出来了,开发平台还全面升级
- 全自研芯片计算!百度智能云Qianfan-VL系列模型重磅开源
- 集合通信库VCCL释放GPU极致算力,创智、基流、智谱等重磅开源
- 攻克大模型训推差异难题,蚂蚁开源新一代推理模型Ring-flash-2.0
- 阿里开源「深度研究」王炸Agent,登顶开源Agent模型榜首
- 阿里王牌Agent横扫SOTA全栈开源力压OpenAI!博士级难题一键搞定