
文章图片
文章图片
头图由AI生成
智东西
作者 | 王涵
编辑 | 漠影
智东西9月17日报道 , 今天凌晨 , 阿里巴巴开源了其首个深度研究Agent模型:通义DeepResearch 。
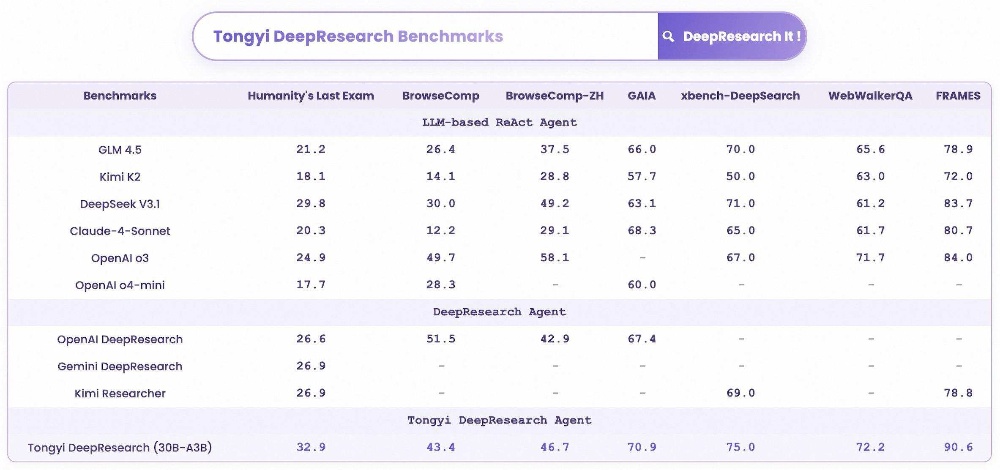
在Humanity’s Last Exam(HLE)、BrowseComp、BrowseComp-ZH、GAIA、xbench-deepsearch、WebWalkerQA以及Frames等权威Agent评测集中 , 通义DeepResearch模型凭借3B激活参数 , 性能超越基于OpenAI o3、DeepSeek V3.1和Claude-4-Sonnet等旗舰模型的ReAct Agent(推理-行动智能体) 。
基准测试成绩排名
基准测试分数
目前 , 通义DeepResearch的模型、框架和方案已在Github、Hugging Face和魔搭社区全面开源 , 开发者和用户可自行下载模型与代码 。
下载地址:
Github:
https://github.com/Alibaba-NLP/DeepResearch
Hugging Face:
https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
魔搭社区:
https://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B
深度研究作为近一年的AI研究热点 , 吸引了谷歌、OpenAI、Anthropic等众多主流企业投入研发 。
深度研究研发的现有方法大多采用“单窗口、线性累加”的信息处理模式 , 在处理长周期任务时 , Agent易遭遇“认知空间窒息”与“不可逆的噪声污染” , 导致推理能力降低 , 难以完成复杂研究任务 。
据介绍 , 为解决这些问题 , 阿里通义团队构建了一套合成数据驱动的完整训练链路 , 覆盖预训练与后训练阶段 。
该链路以Qwen3-30B-A3B模型为基础进行优化 , 设计了RL算法验证与真实训练模块 , 涵盖真实与虚拟环境 , 并借助异步强化学习算法及自动化数据策展流程 , 有效提升了模型的迭代速度与泛化能力 。
在推理阶段 , 通义团队还设计了ReAct和基于自研IterResearch的Heavy两种模式 。 ReAct用于精准评估模型的基础内在能力 , Heavy则通过test-time scaling策略 , 充分挖掘模型的性能上限 , 确保在长任务中也能实现高质量推理 。
结语:阿里进一步补全开源布局今年以来 , 阿里已陆续开源WebWalker、WebDancer和WebSailor等多款检索和推理智能体 , 且均取得开源SOTA成绩 。 通义DeepResearch的开源 , 进一步丰富了阿里在AI智能体领域的开源布局 。
【阿里开源「深度研究」王炸Agent,登顶开源Agent模型榜首】通义DeepResearch的开源为深度研究Agent赛道提供了“轻量化高性能”的新选择 , 也为全球开发者攻克长周期复杂研究任务提供了关键工具支撑 。
推荐阅读












- 让机器人「不只是走路」,Nav-R1引领带推理的导航新时代
- 阿里王牌Agent横扫SOTA全栈开源力压OpenAI!博士级难题一键搞定
- 具身智能还需要一个「五年耐心」
- 阿里开源通义DeepResearch:登顶开源Agent模型榜首
- 华为首款旅行车 1 小时订单破 5000,余承东再次「封神」?
- 安卓机集体「 苹果 」化?
- 谷歌DeepMind「粪坑淘金」全新方法,暗网毒数据也能训出善良模型
- 穿过AI迷雾,企业如何从「+AI」奔向「AI+」?
- 阿里全新AI芯片曝光:重要参数与H20相当!
- B站想用「视频播客」吸引更多优质创作者