英伟达祭出下一代GPU,狂飙百万token巨兽,投1亿爆赚50亿

文章图片
文章图片
9日 , 英伟达重磅发布了专为海量上下文AI打造的CUDA GPU——Rubin CPX , 将大模型一次性推理带入「百万Token时代」 。 NVIDIA创始人兼CEO黄仁勋表示 , Vera Rubin平台将再次推动AI计算的前沿 , 不仅带来下一代Rubin GPU , 也将开创一个CPX的全新处理器类别 。
「百万Token怪兽」出世!
昨天(9日) , NVIDIA突放大招 , 推出了Rubin CPX , 这是一款专为大规模上下文推理而设计的全新GPU 。
它的性能 , 是Vera Rubin NVL144平台的2倍多 , 是基于Blackwell Ultra的GB300 NVL72机架式系统的7.5倍!
它具有单机架8 EFLOPS的NVFP4计算力、100TB高速内存与1.7 PB/s的内存带宽、128GB的高性价比GDDR7显存 。
相比较NVIDIA GB300 NVL72系统 , Rubin CPX带来了3倍的注意力机制处理能力 。
性能巨兽 , 在变现能力上更是不容小觑 。
每投入1亿美元 , 最高可以带来50亿美元的Token收入!
Rubin CPX开创CPX全新处理器类别Rubin CPX基于Rubin架构构建 , 是首款专为海量上下文AI打造的CUDA GPU , 能够在同一时间推理跨越数百万个知识标记的模型 。
可以说 , Rubin CPX是专为破解AI「长上下文」瓶颈而生的「特种兵」 。
它的出现 , 为AI带来了百万Token级推理场景下的性能和效率的新突破 。
依托于全新的NVIDIA Vera Rubin NVL144 CPX平台 , Rubin CPX与NVIDIA Vera CPU和Rubin GPU紧密协同 , 可以支持多步推理、持久化记忆与长时程上下文 , 这让它在面对软件开发、视频生成、深度研究等领域的复杂任务时 , 更加游刃有余 。
这也意味着在Rubin CPX的最新加持下 , AI编码将从简单的代码生成工具 , 升级为能够理解并优化大规模软件项目的复杂系统 。
同样 , 它还可以满足长视频与研究类应用领域 , 在数百万Token级别上保持持续一致性与记忆的需求 。
这些需求 , 都在逼近当前基础设施的极限 。
NVIDIA创始人兼CEO黄仁勋表示 , Vera Rubin平台将再次推动AI计算的前沿 , 也将开创一个CPX的全新处理器类别 。
「正如RTX颠覆了图形与物理AI一样 , Rubin CPX是首个专为海量上下文AI打造的CUDA GPU , 模型能够一次性跨越数百万个Token的知识进行推理 。 」
目前 , Cursor、Runway和Magic等AI先锋企业 , 正在积极探索Rubin CPX在应用加速上的新可能 。
30-50倍ROI , 重写推理经济Rubin CPX通过解耦式推理创新 , 可以企业带来30-50倍ROI , 重写推理经济 。
大模型的推理 , 主要分为上下文和生成两个阶段 。
它们对于基础设施的要求 , 也存在着本质性的差异 。
上下文阶段 , 以计算受限为主 , 需要高吞吐处理来摄取并分析海量输入数据 , 以产出第一个Token的输出结果 。
而生成阶段 , 则以内存带宽受限为主 , 依赖快速的内存传输与高速互联(如NVLink)来维持逐Token的输出性能 。
解耦式推理 , 可以让这两个阶段独立处理 , 从而更加针对性地优化算力与内存资源 , 提升吞吐 , 降低时延 , 增强整体资源的利用率 。
但解耦式推理 , 也带来了新的复杂性层次 , 需要在低时延KV缓存传输、面向大模型感知的路由 , 以及高效内存管理之间进行精确协调 。
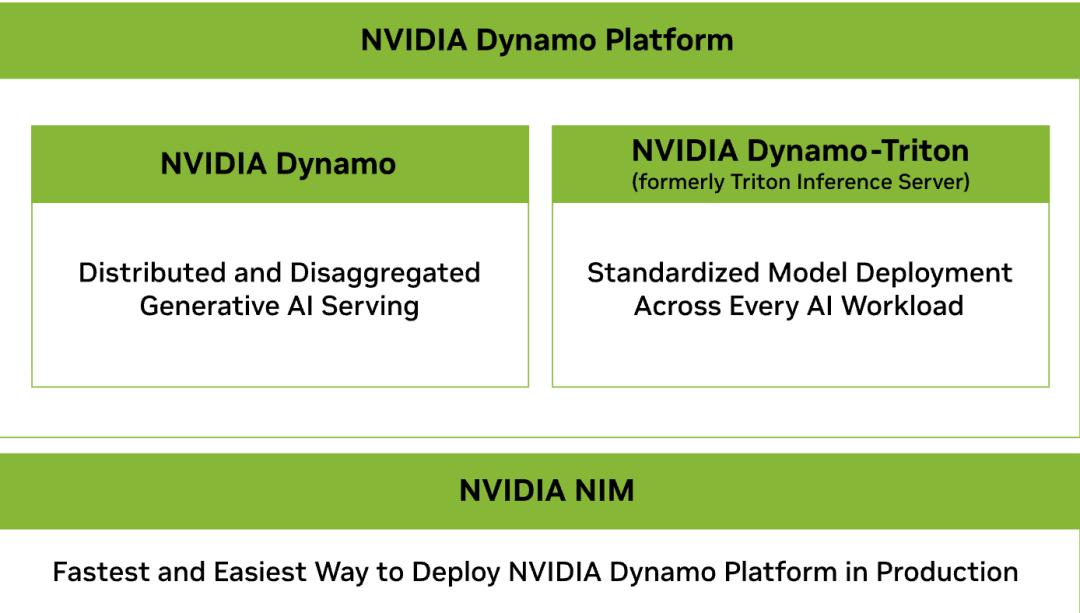
这离不开NVIDIA Dynamo , 它作为以上组件的编排层 , 发挥着关键作用 。
Rubin CPX是专为大语言模型(尤其是百万Token上下文)推理设计的「专用加速器」 。
Rubin CPX与NVIDIA Vera CPU, 以及用于生成阶段处理的Rubin GPU协同工作 , 共同形成了面对长上下文场景的完整的高性能解耦式服务方案 。
CPX的推出 , 标志着解耦式推理基础设施的最新进化 , 也树立了推理经济的新标杆 。
在规模化场景下 , NVIDIA Vera Rubin NVL144 CPX平台 , 可带来30–50x的投资回报(ROI) 。
这意味着1亿美元的资本性支出(CAPEX) , 最高可转化为50亿美元的收入 。
百万Token怪兽 , 重新定义下一代AI应用Vera Rubin NVL144 CPX平台 , 重新定义了企业构建下一代生成式AI应用的可能性 。
NVIDIA Vera Rubin NVL144 CPX机架与托盘 , 配备Rubin上下文GPU(Rubin CPX)、Rubin GPU与 Vera CPU
Rubin CPX与NVIDIA Vera CPU、Rubin GPU , 共同集成在全新的NVIDIA Vera Rubin NVL144 CPX平台内 。
NVIDIA Vera Rubin NVL144 CPX平台 , 采用最新GPU架构 , 具备极高算力与能效比 , 可以基于MGX架构实现机架级部署 。
1.算力跃升
NVIDIA MGX机架式系统 , 单机架集成了144块Rubin CPX GPU、144 块Rubin GPU与36颗Vera CPU , 可以提供8 EFLOPS的NVFP4计算力 , 并在单机架内配备100TB高速内存与1.7 PB/s的内存带宽 。
2.长序列的高效处理优化
Rubin CPX针对长序列的高效处理进行了优化 , 是软件应用开发与高清(HD)视频生成等高价值推理用例的关键 。
3.显存升级
单个Rubin CPX GPU可以提供高达30 petaflops的NVFP4计算能力 , 它配备128GB的高性价比GDDR7显存 , 以加速最苛刻的上下文类工作负载 。
4.注意力机制加速
相比NVIDIA GB300 NVL72系统 , Rubin CPX带来了3倍的注意力机制处理能力 , 显著提高模型处理更长上下文序列的能力且不降速 。
5.多种形态配置
Rubin CPX提供多种形态配置 , 包括 Vera Rubin NVL144 CPX , 并可与NVIDIA Quantum-X800 InfiniBand横向扩展计算网络 。
也可以搭配采用NVIDIA Spectrum-XGS以太网技术与NVIDIA ConnectX?-9 SuperNICs?的NVIDIA Spectrum-X?以太网网络平台结合使用 , 以实现大规模部署 。
Rubin CPX , 拥抱NVIDIA全栈AI生态在生态上 , Rubin CPX将得到完整的NVIDIA AI堆栈支持 , 包括:
软件平台:NVIDIA AI Enterprise , 包含NVIDIA NIM?微服务以及可在NVIDIA加速的云、数据中心和工作站上部署的AI框架、库与工具 。 编排与模型:NVIDIA Dynamo平台负责高效扩展AI推理 , 同时处理器将能够运行NVIDIA Nemotron?多模态模型家族中的最新模型 。 开发者生态:基于数十年的创新 , Rubin平台扩展了NVIDIA庞大的开发者生态 , 包括NVIDIA CUDA-X?库、超过600万开发者的社区以及近6000个CUDA应用 。NVIDIA Rubin CPX预计将于2026年底可用 。
它的推出将为全球开发者与创作者解锁更强大的能力 , 重新定义企业构建下一代生成式AI应用的可能性 。
参考资料https://developer.nvidia.com/blog/nvidia-rubin-cpx-accelerates-inference-performance-and-efficiency-for-1m-token-context-workloads/%20
https://nvidianews.nvidia.com/news/nvidia-unveils-rubin-cpx-a-new-class-of-gpu-designed-for-massive-context-inference?ncid=so-twit-653111
【英伟达祭出下一代GPU,狂飙百万token巨兽,投1亿爆赚50亿】本文来自微信公众号“新智元” , 作者:元宇 , 36氪经授权发布 。
推荐阅读
















- 英伟达的AI已经开始接管整个项目了?SATLUTION进化代码库登顶SAT
- 英伟达要求三星翻倍供应GDDR7,或用于对华特供芯片
- 当智能醒于物理世界,英伟达副总裁: 下一个十年属于物理AI!
- 英伟达深夜突放大招,全新GPU为长上下文推理而生
- 唱衰ASIC惨遭博通打脸,英伟达称自家GPU更具性价比!
- 博通ASIC来势汹汹,英伟达无惧!
- OpenAI携手博通自研芯片,科技巨头围攻英伟达
- 三星将向英伟达大量供应GDDR7,传将用于对华特供的B30芯片
- 思科联手英伟达和VAST推出安全AI工厂解决方案
- 华为麒麟芯片正式回归,下一代芯片也传来新消息,性能、工艺或全面突破