
文章图片

文章图片

文章图片
文章图片
当人们还在惊叹大模型能写代码、能自动化办公时 , 它们正在悄然踏入一个更敏感、更危险的领域 —— 网络安全 。
想象一下 , 如果 AI 不只是写代码的助手 , 而是能够像「白帽黑客」一样 , 在不破坏系统的前提下模拟攻击、发现漏洞、提出修复建议 , 会带来怎样的改变?
这个问题 , 最近由 Amazon AWS AI 的 Q Developer 团队给出了答案 。 他们在 arXiv 上同时发布了两篇论文 , 提出了训练网络安全大模型的全新方法:Cyber-Zero 和 CTF-Dojo 。 这两项研究不仅是学术探索 , 更像是一次「实战演练」的预告 , 预示着大模型智能体正在从通用任务走向网络安全的前线 。
论文 1: Cyber-Zero: Training Cybersecurity Agents without Runtime
链接: https://arxiv.org/abs/2508.00910
论文 2: Training Language Model Agents to Find Vulnerabilities with CTF-Dojo
链接:https://arxiv.org/abs/2508.18370
网络安全
大模型落地的一座特殊堡垒
在通用任务上 , 大模型的训练已经形成了相对成熟的范式:海量数据、长时间预训练、再经过对齐与微调 。 但网络安全场景不同 , 其核心难点在于训练环境与数据的高度敏感性 。
事实上 , 闭源大模型已经在安全攻防方向展现出一定潜力 。 Google 的 Project Zero 团队就曾使用 Gemini 系列模型探索漏洞发现 , 一些初创公司甚至尝试构建基于闭源模型的「AI 红队」 , 用来模拟攻击并进行防御验证 。 实际案例表明 , 这些强大的闭源模型确实具备了发现漏洞、自动化执行攻击步骤的潜力 。
然而问题在于 , 这些模型的训练范式和数据集完全不透明 。 我们无法得知它们是如何习得攻防知识的 , 也无法验证模型的安全性与可靠性 。 更重要的是 , 闭源模型无法被研究者和企业安全团队自主改造或控制 , 这本身在安全领域是一种潜在风险 。
另一方面 , 如果要让模型从零开始学会攻防 , 传统思路需要搭建真实运行环境 , 以生成交互轨迹 。 但这种方式成本高、风险大 , 甚至可能在实验中触发不可控的攻击 。 而高质量的安全攻防数据本就极度稀缺 。 漏洞利用和修复往往涉及复杂的环境状态、系统调用和长时间推理 , 很难像自然语言文本那样容易转化为标准语料 。
这意味着 , 如果继续沿用传统方式 , 「AI 白帽黑客」可能永远只能停留在实验阶段 。 Amazon 团队正是瞄准了这个瓶颈 , 提出了两个互补的解决方案:Cyber-Zero 致力于「如何生成安全而高效的训练数据」 , 而 CTF-Dojo 则专注于「如何在实战中训练模型发现漏洞」 。
Cyber-Zero
无需真实环境的模拟训练场
Cyber-Zero 的核心思想是「runtime-free training」 , 即完全不依赖真实运行环境 , 而是通过已有知识和语言建模生成训练所需的高质量行为轨迹 (trajectories) 。
团队注意到 , 公开的 CTF(Capture The Flag)竞赛 writeups 是极其宝贵的资源 。 它们记录了参赛者如何分析题目、尝试攻击、定位漏洞以及最终解题的过程 。 Cyber-Zero 正是基于这些 writeups , 构建出高质量的训练轨迹 。
具体来说 , 系统首先从 writeups 中提取关键步骤和思路 , 然后通过设定不同的人格(persona) , 让大模型在纯文本环境中模拟攻防双方的对话与操作 。 例如 , 攻击者 persona 会生成可能的利用路径 , 防御者 persona 会进行应对 。 这一过程中生成的长序列交互被视作行为轨迹 , 用于训练网络安全智能体 。
实验表明 , 这种免运行时的轨迹生成不仅规模可观 , 而且多样性丰富 , 覆盖了常见的攻防模式 。 与真实环境生成的轨迹相比 , Cyber-Zero 的数据在漏洞定位、攻击路径推理等任务上的训练效果毫不逊色 , 甚至在部分指标上表现更优 。 这意味着 , AI 白帽黑客可以在一个完全安全的虚拟训练营中反复优化 , 而不必担心成本和风险 。
【大模型智能体不止能写代码,还能被训练成白帽黑客】
团队还得出几项关键发现:
通用的软件工程智能体(SWE Agents)无法直接迁移至网络安全任务 。 写代码 ≠ 找漏洞 , 两类技能之间存在明显鸿沟 。 模型规模与性能密切相关:参数更大的模型更擅长维持长程推理链 , 跨多步组合命令 , 并在多轮交互中保持状态连贯 , 这对复杂攻防至关重要 。 经过 Cyber-Zero 轨迹微调的 32B 智能体 , 性能已接近闭源模型 Claude-3.7-Sonnet , 而推理成本仅为其 1% 。
这些结果一方面凸显了 Cyber-Zero 的实用价值:它不仅能安全、低成本地生成训练数据 , 还能让模型通过微调在安全任务上具备实用能力;另一方面也指出了研究方向:如果不针对安全任务进行专门优化 , 即便是大规模的通用 SWE 智能体也难以承担白帽黑客的角色 。
CTF-Dojo
让 AI 在实战中学会发现漏洞
如果说 Cyber-Zero 提供的是一个「虚构的训练场」 , 它通过解析 CTF writeups 与 persona 模拟 , 在纯文本空间中生成攻防轨迹 , 让模型在完全无风险的虚拟环境中学习;那么 CTF-Dojo 就是一个「真实的战场」 。 它直接构建可运行的 CTF 攻防环境 , 让智能体能够真正执行命令、与系统交互、发现并利用漏洞 。 前者强调规模化、安全、高效的数据生成 , 后者强调贴近实战的攻防演练 , 两者一虚一实 , 形成互补 。
CTF-Dojo 的核心难点在于:如何在大规模下为 LLM 智能体提供稳定的运行环境 。 传统 SWE(软件工程)代理通常需要专家手动配置环境才能运行 , 而每个任务的准备工作往往耗时数周 , 极大限制了研究规模 。 为此 , Amazon 团队提出了 CTF-Forge , 一种能够在几分钟内自动搭建运行时的容器化工具 , 可以快速部署数百个挑战实例 , 显著降低了人力成本 。
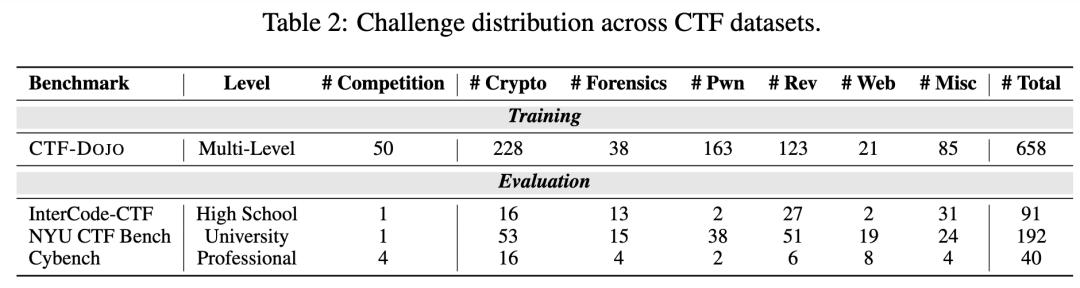
研究团队选择了全球最具代表性的 pwn.college CTF Archive 作为种子数据 。 该数据集收录了数百个来自顶级赛事的高质量题目 , 涵盖六大类别 , 从 Web 漏洞、二进制利用到密码学挑战一应俱全 。 通过精心筛选 , 并排除测试数据中已包含的题目 , 最终形成了 658 个独立任务实例 , 为智能体训练提供了坚实的基础 。
然而 , 最初实验表明 , 开源模型在这些复杂任务上的成功率极低 。 大部分 OSS 模型只能完成少数挑战 , 生成的轨迹也质量参差不齐 。 为了提高可用样本的产出率 , 团队引入了三项推理阶段增强技术:
将公开的赛题笔记(writeups) 作为提示 , 帮助模型更快锁定解题方向; 运行时增强:通过在执行过程中动态修改环境配置或任务约束 , 把过于复杂的挑战「降维」 , 从而提升模型完成任务的成功率; 教师模型多样化:不仅依赖单一模型生成解题轨迹 , 而是同时调用多种不同类型的大模型(包括开源和闭源) , 让它们各自贡献成功案例 , 以此获得更丰富、更具多样性的训练样本 。
最终 , 团队主要依赖 Qwen3-Code-480B 和 DeepSeek-V3-0324 两个强大的开源模型 , 收集到来自 274 个挑战的 1000+ 成功轨迹 。 在去除冗余、限制每个任务实例的最大样本数后 , 最终得到了 486 条高质量、经过运行验证的轨迹 。
基于这些数据 , 研究团队对 Qwen3 系列模型(8B、14B 和 32B 参数规模)进行了训练 , 并在多个网络安全基准任务上评估了效果 。 结果显示 , 经过 CTF-Dojo 训练的模型 , 在 EnIGMA+ 基准(源自前作 Cyber-Zero)上取得了最高 11.6% 的绝对提升 , 不仅超过了开源基线模型 , 还表现出与闭源模型接近的水平 。 更重要的是 , 随着训练样本数量的增加 , 性能呈现出清晰的可扩展性 , 证明了在真实环境轨迹驱动下 , 大模型在网络安全任务上的潜力可以被系统性激发 。
这些结果意味着 , CTF-Dojo 不仅解决了过去「环境难以大规模配置」的工程难题 , 还验证了一个核心科学问题:网络安全智能体的性能能够随着执行数据的增加而持续提升 。 在已有 SWE 代理无法泛化的情况下 , CTF-Dojo 给出了一条清晰的道路:通过规模化、自动化的运行环境收集轨迹 , 推动模型逐步逼近人类白帽黑客的实战水平 。
从虚拟到实战的组合拳
把 Cyber-Zero 和 CTF-Dojo 放在一起看 , 就会发现它们形成了一个闭环 。 Cyber-Zero 提供的是安全、可扩展的训练数据来源 , 相当于一个虚拟训练营;而 CTF-Dojo 则是实战武馆 , 让模型在真实挑战中不断迭代 。 前者解决了数据与成本的问题 , 后者解决了能力习得与迁移的问题 。 两者结合 , 为 AI 白帽黑客的成长提供了完整路径 。
这种设计思路的意义在于 , 它不仅追求理论上的可行性 , 还强调在生产环境中真正可部署 。 正如论文中展示的实验结果 , Cyber-Zero 的数据生成和 CTF-Dojo 的环境构建都能规模化运行 , 且能在真实任务上带来可验证的性能提升 。 这标志着 AI 在网络安全方向正在逐步进入应用落地阶段 。
未来意义与挑战
AI 白帽黑客蕴藏广阔前景:在企业安全团队中 , 它可以作为虚拟成员 , 自动扫描代码、发现潜在漏洞 , 并提出修复建议;在红队演练中 , 它可以充当对手角色 , 帮助测试防御系统;在教育场景中 , 它可以成为学员的「陪练」 , 提供个性化的挑战和反馈 。 更长远来看 , 随着成本降低和技术成熟 , 中小企业也有望借助这样的系统获得「普惠安全」 。
但与此同时 , 这项技术的双重用途属性不容忽视 。 正如研究团队在论文中强调的那样 , 虽然 Cyber-Zero 和 CTF-Dojo 的初衷是帮助开发者和研究人员在软件部署前发现并修复漏洞 , 但同样的能力也可能被滥用于进攻目的 , 比如自动化发现外部系统的漏洞 , 甚至开发恶意工具 。 特别是 Cyber-Zero 的「免运行时」方法 , 降低了训练高性能网络安全智能体的门槛 , 使其更容易被更广泛的群体获取和使用 。 这种民主化的趋势既意味着安全研究的普及 , 也意味着风险的扩散 。
实验结果已经证明 , 基于虚拟轨迹或执行验证数据训练的模型 , 能够在多个基准任务上达到接近甚至媲美闭源前沿模型的性能 。 这表明先进网络安全能力的民主化不仅在技术上可行 , 而且正在快速到来 。 如何确保这类能力更多地服务于防御 , 而不是被滥用于攻击 , 将是未来亟需讨论的议题 。
在未来研究方向上 , 团队提出了几个值得关注的思路 。 一个是构建实时更新的 CTF 基准:通过 CTF-Forge 自动重建比赛环境 , 把来自活跃 CTF 赛事的挑战容器化 , 用于动态评测和轨迹采集 , 实现可扩展、实时的 benchmark 。 另一个方向是强化学习 , 即让网络安全智能体直接与动态环境交互 , 并通过结构化奖励获得反馈 。 这种范式有望突破单纯模仿学习的局限 , 使模型能够发展出更普适、更具适应性的策略 , 更好地应对未知的安全问题 。
因此 , 未来的关键在于平衡开放与安全 。 在推动技术进步与普及的同时 , 建立有效的安全护栏 , 需研究者、开发者、安全机构与政策制定者协同努力 , 确保这类强大工具以负责任的方式被开发和使用 。 唯有如此 , 才能真正增强整体网络防御能力 , 迎接一个更安全的智能时代 。
参考资料:
[1
Zhuo T. Y. Wang D. Ding H. Kumar V.Wang Z. (2025). Cyber-Zero: Training Cybersecurity Agents without Runtime. arXiv preprint arXiv:2508.00910.
[2
Zhuo T. Y. Wang D. Ding H. Kumar V.Wang Z. (2025). Training Language Model Agents to Find Vulnerabilities with CTF-Dojo. arXiv preprint arXiv:2508.18370.
[3
https://x.com/terryyuezhuo/status/1962009753472950294
[4
https://github.com/amazon-science/Cyber-Zero
推荐阅读











- 如果大模型是一片星空,谁是北斗?
- 放弃实体SIM卡的iPhone能买吗:三大运营商均推进,联通用户或成首批尝鲜者
- 二季度出货的智能手机平均配备3.19个摄像头
- 北京市通用人工智能产业创新伙伴计划2.0发布
- 2025外滩大会科技智能创新赛落幕,优胜者奖金池达162万元
- 当智能醒于物理世界,英伟达副总裁: 下一个十年属于物理AI!
- 星钥半导体8英寸Micro-LED芯片中试线在光谷通线
- iPhone 17 国行首发不支持 AI,苹果智能预计年底上线
- IFA观察|更智能、更绿色,中国企业高端出海
- 芝麻信用战略升级商业信用服务体系 向高德地图正式开放