
文章图片

文章图片

文章图片

文章图片
文章图片
【何恺明改进了谢赛宁的REPA:极大简化但性能依旧强悍】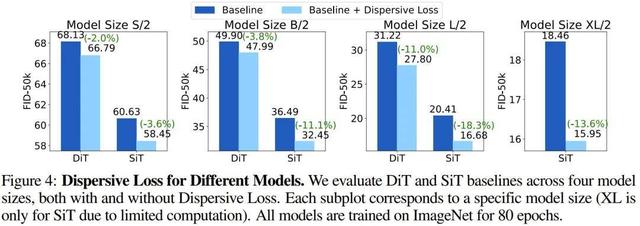
文章图片

文章图片
机器之心报道
编辑:Panda
在建模复杂的数据分布方面 , 扩散生成模型表现出色 , 不过它的成果大体上与表征学习(representation learning)领域关联不大 。
通常来说 , 扩散模型的训练目标包含一个专注于重构(例如去噪)的回归项 , 但缺乏为生成学习到的表征的显式正则化项 。 这种图像生成范式与图像识别范式差异明显 —— 过去十年来 , 图像识别领域的核心主题和驱动力一直是表征学习 。
在表征学习领域 , 自监督学习常被用于学习适用于各种下游任务的通用表征 。 在这些方法中 , 对比学习提供了一个概念简单但有效的框架 , 可从样本对中学习表征 。
直观地讲 , 这些方法会鼓励相似的样本对(正例对)之间相互吸引 , 而相异的样本对(负例对)之间相互排斥 。 研究已经证明 , 通过对比学习进行表征学习 , 可以有效地解决多种识别任务 , 包括分类、检测和分割 。 然而 , 还没有人探索过这些学习范式在生成模型中的有效性 。
鉴于表征学习在生成模型中的潜力 , 谢赛宁团队提出了表征对齐 (REPA)。 该方法可以利用预训练得到的现成表征模型的能力 。 在训练生成模型的同时 , 该方法会鼓励其内部表征与外部预训练表征之间对齐 。 有关 REPA 的更多介绍可阅读我们之前的报道《扩散模型训练方法一直错了!谢赛宁:Representation matters》 。
REPA 这项开创性的成果揭示了表征学习在生成模型中的重要性;然而 , 它的已有实例依赖于额外的预训练、额外的模型参数以及对外部数据的访问 。
简而言之 , REPA 比较麻烦 , 要真正让基于表征的生成模型实用 , 必需一种独立且极简的方法 。
这一次 , MIT 本科生 Runqian Wang 与超 70 万引用的何恺明出手了 。 他们共同提出了 Dispersive Loss , 可译为「分散损失」 。 这是一种灵活且通用的即插即用正则化器 , 可将自监督学习集成到基于扩散的生成模型中 。
- 论文标题:Diffuse and Disperse: Image Generation with Representation Regularization
- 论文链接:https://arxiv.org/abs/2506.09027v1
直觉上看 , 分散损失会鼓励内部表征在隐藏空间中散开 , 类似于对比学习中的排斥效应 。 同时 , 原始的回归损失(去噪)则自然地充当了对齐机制 , 从而无需像对比学习那样手动定义正例对 。
一言以蔽之:分散损失的行为类似于「没有正例对的对比损失」 。
因此 , 与对比学习不同 , 它既不需要双视图采样、专门的数据增强 , 也不需要额外的编码器 。 训练流程完全可以遵循基于扩散的模型(及基于流的对应模型)中使用的标准做法 , 唯一的区别在于增加了一个开销可忽略不计的正则化损失 。
与 REPA 机制相比 , 这种新方法无需预训练、无需额外的模型参数 , 也无需外部数据 。 凭借其独立且极简的设计 , 该方法清晰地证明:表征学习无需依赖外部信息源也可助益生成式建模 。
带点数学的方法详解
分散损失
新方法的核心是通过鼓励生成模型的内部表征在隐藏空间中的分散来对其进行正则化 。 这里 , 将基于扩散的模型中的原始回归损失称为扩散损失(diffusion loss) , 将新引入的正则化项称为分散损失(Dispersive Loss) 。
如果令 X = {x_i 为有噪声图像 x_i 构成的一批数据 , 则该数据批次的目标函数为:
等式 (6) 中定义的基于 InfoNCE 的分散损失类似于前述先前关于自监督学习的论文中的均匀性损失(尽管这里没有对表示进行 ?? 正则化) 。 在那篇论文中的对比表示学习 , 均匀性损失被应用于输出表示 , 并且必须与对齐损失(即正则项)配对 。 而这里的新公式则更进一步 , 移除了中间表示上的对齐项 , 从而仅关注正则化视角 。
该团队注意到 , 当 j = i 时 , 就不需要明确排除项 D (z_iz_j) 。 由于不会在一个批次中使用同一图像的多个视图 , 因此该项始终对应于一个恒定且最小的差异度 , 例如在?? 的情况下为 0 , 在余弦情况下为 -1 。 因此 , 当批次大小足够大时 , 这个项在那个对数中的作用是充当一个常数偏差 , 其贡献会变小 。 在实践中 , 无需排除该项 , 这也简化了实现 。
分散损失的其他变体
分散损失的概念可以自然延伸到 InfoNCE 之外的一类对比损失函数 。
任何鼓励排斥负例的目标都可以被视为分散目标 , 并实例化为分散损失的一种变体 。 基于其他类型的对比损失函数 , 该团队构建了另外两种变体 。 表 1 总结了所有三种变体 , 并比较了对比损失函数和分散损失函数 。
铰链损失(Hinge Loss)
使用分散损失的扩散模型
如表 1 所示 , 所有分散损失的变体都比其对应的分散损失更简洁 。 更重要的是 , 所有分散损失函数都适用于单视图批次 , 这样就无需进行多视图数据增强 。 因此 , 分散损失可以在现有的生成模型中充当即插即用的正则化器 , 而无需修改回归损失的实现 。
在实践中 , 引入分散损失只需进行少量调整:
- 指定应用正则化器的中间层;
- 计算该层的分散损失并将其添加到原始扩散损失中 。
该团队表示:「我们相信 , 这种简化可极大地促进我们方法的实际应用 , 使其能够应用于各种生成模型 。 」
分散损失的实际表现如何?
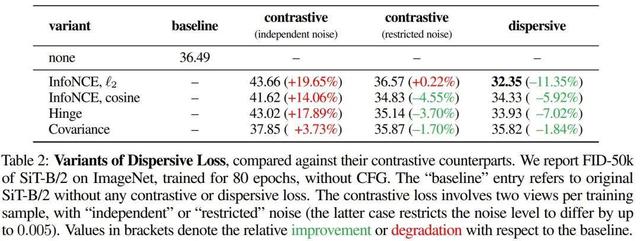
表 2 比较了分散损失的不同变体及相应的对比损失 。
可以看到 , 在使用独立噪声时 , 对比损失在所有研究案例中均未能提高生成质量 。 该团队猜想对齐两个噪声水平差异很大的视图会损害学习效果 。
而分散损失的表现总是比相应的对比损失好 , 而前者还避免了双视图采样带来的复杂性 。
另外 , 该团队还研究了不同模块选择以及不同 λ(控制正则化强度)和 τ(InfoNCE 中的温度)值的影响 。 详见原论文 。
另外 , 不管是在 DiT(Diffusion Transformer)还是 SiT(Scalable Interpolant Transformers)上 , 分散损失在所有场景下都比基线方法更好 。 有趣的是 , 他们还观察到 , 当基线性能更强时 , 相对改进甚至绝对改进往往还会更大 。
总体而言 , 这种趋势有力地证明了分散损失的主要作用在于正则化 。 由于规模更大、性能更强的模型更容易过拟合 , 因此有效的正则化往往会使它们受益更多 。
图 5 展示了 SiT-XL/2 模型生成的一些示例图像 。
当然 , 该团队也将新方法与 REPA 进行了比较 。 新方法的正则化器直接作用于模型的内部表示 , 而 REPA 会将其与外部模型的表示对齐 。 因此 , 为了公平起见 , 应同时考虑额外的计算开销和外部信息源 , 如表 6 所示 。
REPA 依赖于一个预训练的 DINOv2 模型 , 该模型本身是从已在 1.42 亿张精选图像上训练过的 11B 参数主干网络中蒸馏出来的 。
相比之下 , 新提出的方法完全不需要这些:无需预训练、外部数据和额外的模型参数 。 新方法在将训练扩展到更大的模型和数据集时非常适用 , 并且该团队预计在这种情况下正则化效果会非常好 。
最后 , 新提出的方法可以直接泛化用于基于一步式扩散的生成模型 。
在表 7(左)中 , 该团队将分散损失应用于最新的 MeanFlow 模型 , 然后观察到了稳定持续的改进 。 表 7(右)将这些结果与最新的一步扩散 / 基于流的模型进行了比较 , 表明新方法可增强 MeanFlow 的性能并达到了新的 SOTA 。
推荐阅读












- 如何把微信撤回时间,2分钟改为3小时,方法简单实用,一看就会
- 5G发牌六周年:5G-A从启航到跃升,谱写科技改变社会新篇
- WWDC25汇总:iOS 26外观大改,没有AI版Siri
- 「Next-Token」范式改变!刚刚,强化学习预训练来了
- 刚刚!苹果 iOS 26 正式发布,界面大改
- iOS 26 界面大改,这些机型被淘汰
- 三星大胆改革后,DRAM产量大幅提升
- 谷歌推出新功能,密码不安全Chrome自动帮忙改
- 出售广州LCD面板工厂股份之后 乐金显示财务状况明显改善
- 三年9个并购,AMD强势进阶