
文章图片

文章图片

文章图片

文章图片
文章图片
文章图片

文章图片
文章图片
文章图片

文章图片
智东西
作者 | 李水青
编辑 | 云鹏
智东西6月10日报道 , 今日 , 苹果开发者大会WWDC25坐实了大模型版Siri跳票的消息 , 而备受期待的苹果AI也被吐槽“拖后腿” 。
就在这两天 , 苹果发布的一篇关于大模型的新论文引起热议 , 该论文试图极力论证大型推理模型(LRMs)的彻底性崩溃 。
研发人员设计实验测试了Claude 3.7 Sonnet、DeepSeek-R1、o3 mini等推理模型 , 得出结论:大型推理模型在处理简单问题时存在“过度思考”问题;而当问题的复杂性上升到临界点时 , 它们回答问题的准确性就会触发“崩溃模式” , 甚至准确度低到接近零 。
苹果发布论文《思维的错觉:通过问题复杂性视角理解推理模型的优势与局限性》
“这(论文)对大语言模型来说是相当具有毁灭性的 。 ”美国人工智能领域知名意见领袖Gary Marcus说 。
投资公司Bootstrapped创始人Ruben Hassid将论文转发至社交平台X上称:“苹果刚刚证明 , 像Claude、DeepSeek-R1和o3-mini这样的AI‘推理’模型实际上根本不具备推理能力 。 它们只是能很好地记住模式而已 。 ”这条推文预览了超1000万 , 评论达到2600多条 。 知名风投Lux Capital联合创始人兼合伙人Josh Wolfe也推荐分享了这篇论文 。
但这篇论文同时也引起了大量质疑 。 苹果论文试图证明 , AI推理模型是假的 , 只是模式匹配机器 。 但不少用户提到:“我们只能等着看论文来证明人类的推理不仅仅是记忆模式了 。 ”用外网爆火的梗图来说就是 , 就算苹果证明了模型无法做推理和原始思考 , 但人类就能了吗?
一些人甚至称这篇论文是“烂文” , 并拿“用锤子敲螺丝”来形容苹果团队实验的荒谬 。 有用户通过复现苹果团队的实验以证明苹果的论证存在逻辑漏洞 , 比如游戏的规划次数不能代表复杂度 , 大模型崩溃只是因为输出太长等 。
另外有网友扒出论文作者的背景 , 论文联合一作还是一名实习生 , 是弗吉尼亚理工大学计算机科学专业三年级博士生 , 这也成为质疑者的发难点 。
【苹果AI“暴论”震动AI圈!DeepSeek、Claude等热门大模型只是死记的模式机器?】还有不少用户认为 , 苹果之所以否定大模型进程是因为其自己错过了这波AI机遇 。
论文地址:https://machinelearning.apple.com/research/illusion-of-thinking?utm_source=perplexity
一、苹果新论文质疑DeepSeek、o3-mini推理能力首先来看实验设计 , 苹果团队的大多数实验在推理模型及对应非推理模型上进行 , 例如Claude 3.7 Sonnet(带/不带深度思考)和DeepSeek-R1/V3 。 团队允许最大token预算为64k 。
测试不是基于当下主流基准测试进行的 , 因为苹果认为这些测试受数据污染影响严重 , 并无法深入了解推理轨迹的结构和质量 , 因此其通过25个谜题实例进行了测试 。
1、DeepSeek、Claude在高复杂度任务上完全崩溃
谜题环境允许在保持一致逻辑结构的同时 , 精确控制组合复杂性 。 苹果认为 , 这种设置不仅能够分析最终答案 , 还能分析内部推理轨迹 , 从而深入了解大型推理模型的“深度思考”方式 。
对于每个谜题实例 , 团队生成25个样本 , 并报告每个模型在这些样本上的平均性能 。 团队通过调整问题规模N(表示圆盘数、棋子数、块数或过河元素数)来改变复杂性 , 从而研究复杂性对推理行为的影响 。
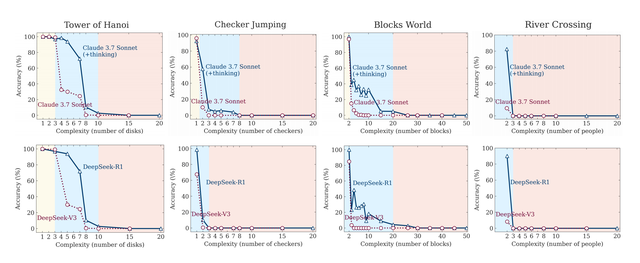
下图展示了两种模型类型在所有谜题环境中作为问题复杂性函数的准确性 。
下图显示了这些模型对在等效推理token计算下的上限性能能力 , 也就是跨所有谜题的平均值 , 将早期从数学基准的分析扩展到可控的谜题环境 。
这两个图的结果表明 , 与基准测试中的观察不同 , 这些模型的行为在复杂性不同的问题中存在三种情况:
(1)在低复杂度任务上 , 标准模型的表现出人意料地优于大型推理模型;
(2)在中等复杂度任务上 , 大型推理模型的额外深度思考表现出优势;
(3)在高复杂度任务上 , 两种模型的表现都完全崩溃 。
2、接近复杂度临界值 , 推理模型开始“偷懒”
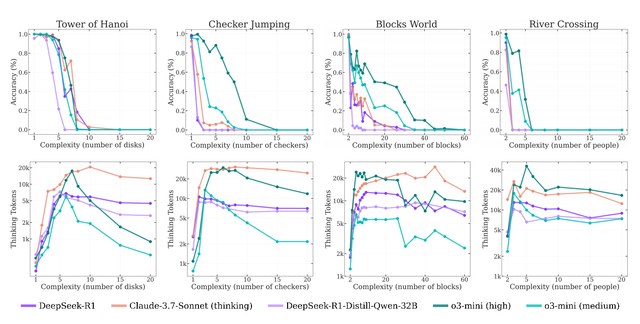
接下来 , 苹果团队研究了配备推理token的不同专门推理模型如何应对不断增加的问题复杂性 。 其实验评估了五种最先进的推理模型:o3-mini(中等和高配置)、DeepSeek-R1、DeepSeek-R1-Qwen-32B和Claude-3.7 Sonnet(深度思考版) 。
下图展示了这些模型在不同复杂性级别上的准确性和推理token使用情况(底部) 。 结果表明 , 所有推理模型在复杂性方面都表现出类似的模式:随着问题复杂性的增加 , 准确性逐渐下降 , 直到超过特定于模型的复杂性阈值后完全崩溃 , 准确度为零 。
团队还观察到 , 推理模型最初随着问题复杂性的增加按比例增加其推理token 。 然而 , 在接近一个与它们的准确性崩溃点密切对应的临界阈值时 , 模型违反直觉地开始减少推理努力 。
这种现象在o3-mini变体中最为明显 , 在Claude-3.7-Sonnet(深度思考版)模型中则不那么严重 。 值得注意的是 , 尽管在深度思考阶段运行远低于其生成长度限制 , 并有充足的推理预算可用 , 但随着问题变得更加复杂 , 这些模型未能利用额外的推理计算 。
这种行为表明 , 当前推理模型的思考能力相对于问题复杂性存在基本的扩展限制 。
3、推理模型内部推理拆解 , “过度思考”和“崩溃模式”
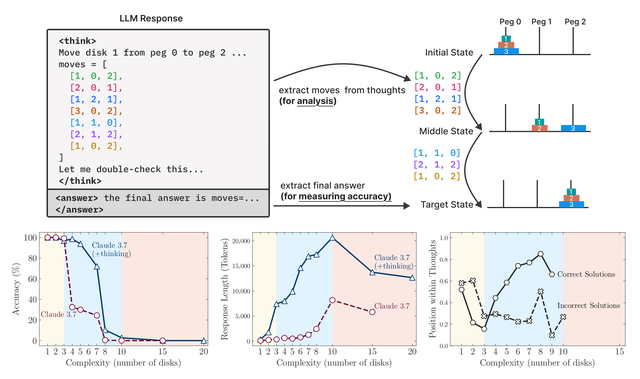
为了更深入地了解推理模型的思考过程 , 苹果团队对其推理轨迹进行了细粒度分析 。 他们借助谜题模拟器提取并分析模型推理中探索的中间解决方案 。
下图中的(a)展示了所有谜题环境中中间解决方案在深度思考中的位置、正确性和问题复杂性之间的关系 。 团队从推理轨迹中进行的分析进一步验证了上述三种复杂性机制 。
对于较简单的问题 , 推理模型通常在其思考的早期找到正确的解决方案 , 但随后继续探索不正确的解决方案 。 请注意 , 与正确解决方案(绿色)相比 , 不正确解决方案(红色)的分布更向上方(朝向思考的末尾)移动 。 这种在文献中被称为“过度思考”的现象导致了计算的浪费 。
随着问题变得中等复杂 , 这种趋势发生了逆转:模型首先探索不正确的解决方案 , 并且大多在思考的后期得出正确的解决方案 。 此时 , 与正确解决方案(绿色)相比 , 不正确解决方案(红色)的分布更向下移动 。
最后 , 对于复杂性较高的问题 , 崩溃出现 , 这意味着模型无法在思考中生成任何正确的解决方案 。
上图中的(b)对河内塔(Tower of Hanoi)环境中思考的顺序段(bin)内的解决方案准确性进行了补充分析 。 河内塔游戏是一种经典的游戏 , 它有三个柱子和多个圆盘 , 玩家需要将左侧柱子上的所有圆盘移动到右侧柱子上 , 并且不能将较大的圆盘堆叠在较小的圆盘上 。
可以观察到 , 对于较简单的问题(较小的N) , 解决方案的准确性随着思考的进行而趋于下降或波动 , 进一步证明了过度思考现象 。 然而 , 对于更复杂的问题 , 这种趋势发生了变化 , 解决方案的准确性随着思考的进行而增加 , 直到达到某个阈值 。 超过这个复杂性阈值 , 在“崩溃模式”下 , 准确性为零 。
4、精确计算执行面临局限性 , “能力”忽高忽低
最后 , 苹果团队展示了关于推理模型在执行精确问题解决步骤方面的局限性 。
如下图(a)和(b)所示 , 在河内塔环境中 , 即使团队在提示中提供了算法 , 以便模型只需执行规定的步骤 , 性能也没有提高 , 并且观察到的崩溃仍然发生在大致相同的点 。
只要练习 , 一个聪明且有耐心的七岁小孩都能完成河内塔游戏 。 而对于计算机来说 , 这更是小菜一碟 。 但Claude几乎不能完成7个圆盘 , 准确率不到80% , 如下图的左下面板所示 , 而且几乎根本无法正确完成8个圆盘 。
苹果公司发现广受好评的o3-min(高版本)并没有更好 , 并且如下图所示 , 他们在多个任务中发现了类似的结果 。 比如 , 大语言模型无法可靠地解决河内塔问题 , 但网上有很多可以免费获取的源代码库 。
这值得注意 , 因为寻找和设计解决方案应该需要比仅仅执行给定算法多得多的计算 , 例如用于搜索和验证 。 这进一步凸显了推理模型在验证和遵循逻辑步骤解决问题方面的局限性 , 表明需要进一步研究以了解此类模型的符号操作能力 。
此外 , 在下图(c)和(d)中 , 团队观察到Claude 3.7 Sonnet推理模型的行为非常不同 。 在河内塔环境中 , 该模型在提议的解决方案中的第一个错误通常发生得晚得多 , 例如 , 对于 N=10 , 大约在第100步 , 而在过河环境中 , 该模型只能生成直到第4步的有效解决方案 。
值得注意的是 , 该模型在解决N=5的河内塔问题时实现了近乎完美的准确性 , 这需要31步 , 而在解决N=3的过河谜题时却失败了 , 该谜题有11步的解决方案 。
这可能表明 , N2的过河示例在网络上很少见 , 这意味着大型推理模型在训练期间可能没有频繁遇到或记忆此类实例 。
二、苹果研究引起争议:设计有逻辑漏洞 , 忽视token限制致结论失真苹果这篇论文一经发布 , 引起了产业较多关注 , 支持和反对声并存 。
知名风投Lux Capital联合创始人兼合伙人Josh Wolfe转发了这篇论文并分享了文章的主要观点:“Claude+DeepSeek看起来很聪明 , 但当复杂性上升时它们就会……彻底崩溃” , “苹果的看法是这些模型没有推理能力 , 只是超级昂贵的模式匹配器 , 一旦我们超出它们的训练分布范围 , 它们就会崩溃”……
美国人工智能领域知名意见领袖Gary Marcus也发文称:“它(苹果新论文)对大语言模型来说是相当具有毁灭性的……大语言模型的拥护者已经一定程度上承认了这一打击 。 ”
他说:“苹果的论文最根本地表明 , 无论你如何定义通用人工智能(AGI) , 大语言模型都无法取代优秀的、规范明确的传统算法 。 ”Gary Marcus的文章获得了大量点赞转发和超160条评论 。 高赞评论提到:“这篇论文是一项精妙的科学研究 , 但不幸的是 , 计算机科学界已经失去了它的精髓 。 ”
另一边是对这篇论文猛烈的批评声 。
一位X平台用户截取论文关键内容并称:“所有这些都是胡说八道 , 但他们甚至懒得看输出结果 。 这些模型实际上是在思维链中背诵算法 , 无论是纯文本还是代码 。 正如我在另一篇文章中解释的那样 , 不同游戏的步骤并不相同 。 ”
他还认为 , 苹果团队对游戏复杂性的定义也令人困惑 , 因为河内塔游戏只是比其他游戏多出指数级的步骤 , 这并不意味着河内塔更难 。
他复现了河内塔游戏 , 由此发现 , 所有模型在圆盘数量超过13个时的准确率都会为 0 , 因为它们无法输出那么多(tokens) 。
“你至少需要2^N-1步 , 并且输出格式要求每步10个token+一些常量 。 此外 , Sonnet 3.7的输出限制为128k , DeepSeek R1为 64k , o3-mini为100k 。 这包括它们在输出最终答案之前使用的推理token 。 ”
一旦超过7个圆盘 , 这些推理模型就不会再去尝试推理问题 。 它会说明问题是什么以及解决它的算法 , 然后输出其解决方案 , 甚至不会考虑各个步骤 。
他指出 , 即使对于n=9(9个圆盘)和n=10(10个圆盘) , Claude 3.7 Thinking也会提前停止推理 , 因为它认为输出太长了 。 准确率的下降至少有一部分仅仅是因为模型认为这是浪费时间而决定提前停止 。
还有一位X平台用户称:“这篇论文太烂了” , 并以比喻“他们试图用锤子敲入螺丝 , 然后写了一篇论文 , 讲述锤子实际上是如何成为固定物品的非常有限的工具”来质疑实验设计的效度 。
还一些观点认为 , 苹果完全错过了AI的列车 , 才会来否定当下的大模型前景 。
结语:对推理模型提出质疑 , 但实验具有局限性通过这篇论文 , 苹果团队对大型推理模型在已建立的数学基准上的当前评估范式提出了质疑 。
团队利用算法谜题环境设计了一个可控的实验测试平台 , 由此论述当下先进的推理模型仍无法开发出可泛化的问题解决能力 , 在不同环境中 , 准确性最终会在超过特定复杂性后崩溃为零 。
与此同时 , 产业人士对论文实验设计逻辑、论述过程、示例选择提出了较多质疑 。 苹果团队也承认了研究的局限性:那就是谜题环境只代表了推理任务的一小部分 , 可能无法捕捉到现实世界或知识密集型推理问题的多样性 。 同时 , 团队的大多数实验依赖于对封闭前沿大型推理模型的黑盒API访问 , 这限制了其分析内部状态或架构组件的能力 。
此外 , 确定性谜题模拟器的使用假设推理可以一步一步地完美验证 。 然而 , 在结构较少的领域中 , 这种精确的验证可能不可行 , 从而限制了这种分析对其他更可泛化推理的可移植性 。
来源:Apple、X平台
推荐阅读














- 从“通用智能”到“领域专家”:Gartner揭示企业AI落地的必由之路
- 微软之后,苹果备忘录也支持导出MD格式了
- 苹果实力雄厚 但为何升级版Siri却延迟发布?
- 618惊喜再升级 三星存储品牌日“全家桶”一站式搬回家
- 负责人开启“微博办公”模式,小米可穿戴业务终于要翻身了?
- 苹果Vision Pro将支持高性能iPad游戏,但未透露具体细节
- iPhone 17系列大分裂!这次买机真的要做“选择题”了
- iOS 26翻车实录:液态玻璃美颜变“电老虎”,旧iPhone慎升!
- vivo S30系列火热开售!带你解锁 “甜酷” 新体验!
- 爆料Xbox掌机带来的“手持界面”,明年有望登录所有Windows PC