
文章图片
文章图片
文章图片
本文作者团队来自 Insta360 影石研究院及其合作高校 。 目前 , Insta360 正在面向世界模型、多模态大模型、生成式模型等前沿方向招聘实习生与全职算法工程师 , 欢迎有志于前沿 AI 研究与落地的同学加入!简历投递邮箱:research@insta360.com
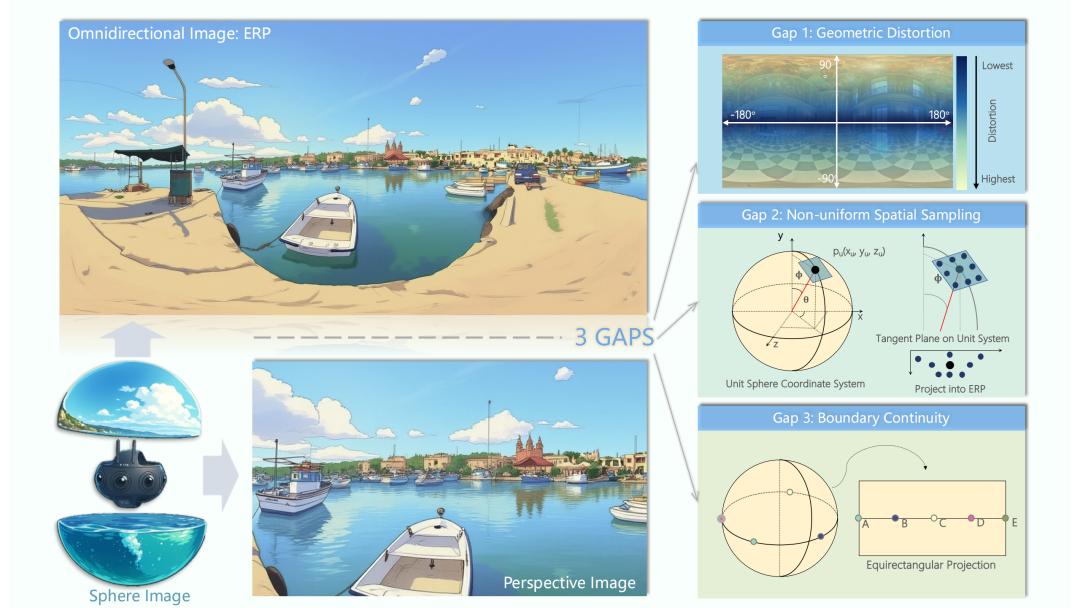
在虚拟现实、自动驾驶、具身智能等新兴应用中 , 全景视觉正逐渐成为不可或缺的研究方向 。 相比于常规透视图像(正常平面图像 , 也是大部分 CV 任务使用的标准输入) , 全景图像捕捉的是 360°×180° 的完整球面视域(包含四周、头顶天空与脚下地面) , 仿佛将站立点周围的整个空间展开成一张“大照片” 。 正因两者在几何投影、空间采样与边界连续性上的本质差异 , 直接把基于透视视觉开发的算法迁移到全景视觉往往失效 。
本文基于 300+ 篇论文、覆盖 20+ 代表性任务 , 首次以 “透视-全景 gap” 为主线 , 系统梳理了三大 gap、两条核心技术路线与未来方向展望 , 既帮助研究者 “按任务选解法” , 也为工程团队 “按场景落地” 提供清晰坐标 。
论文标题:One Flight Over the Gap: A Survey from Perspective to Panoramic Vision 项目地址:https://insta360-research-team.github.io/Survey-of-Panorama/ 综述文章链接: https://arxiv.org/pdf/2509.04444 全景文章汇总链接:https://github.com/Insta360-Research-Team/panoramic-vision-survey
研究背景与动机
左侧展示了由全景相机获取的球面影像 , 经过投影后变成常见的等距矩形投影 (ERP) 全景图像 。 相比下方的透视图像 , 虽然能完整覆盖 360° 场景 , 却引入了三大核心挑战:
几何畸变:球面展开到平面时 , 两极区域被严重拉伸 , 物体形状被破坏 。非均匀采样:赤道像素密集、极区像素稀疏 , 同一物体在不同纬度分辨率差异明显 。边界连续性:ERP 左右边界实际上在球面上相邻 , 但在二维图像上却被分割 , 导致模型学习时出现连续性问题 。
这三大 gap 正是透视方法难以直接适配全景场景的根源 , 也构成了后续研究创新的出发点 。 相较现有的全景视觉综述多沿 “单一任务线” 纵向梳理 , 本文以 “透视→全景” 的 gap 为问题原点进行分类与分析 , 从数据、算法到应用层面揭示两者差异及全景研究滞后的原因 , 这是一个更具动机张力、且现有综述未充分展开的创新视角 。
策略速览
四类方法、一张图看懂任务适配
在全景视觉中 , 分割/修复等依赖全局语义一致性 , 而深度/光流等强调局部几何精度 , 因此形成了不同策略谱系 。 图(c)给出跨方法(cross-method)纵向对照:明确 Distortion-Aware / Projection-Driven / Physics-/Geometry-based 的适用分工 , 并与代表性任务逐一进行策略适配 。 其价值在于提供一个统一参考:研究者可从整体视角理解任务需求 , 快速选型或设计最合适的方法 , 也为多策略融合与后续创新奠定基础 。
图(a)和图(b)分析了两种典型的策略:
① Distortion-Aware(失真感知方法):直接在 ERP 全景格式上建模 , 通过畸变设计、畸变图权重或自适应注意力来补偿极区问题 。
优势:保留全局像素级别的语义对应 , 不丢失信息;与主流架构高度兼容;端到端设计 , 简洁易用 。 局限:极区残余畸变依旧影响准确率;在几何敏感任务(如深度、光流)上鲁棒性不足 。
② Projection-Driven(投影驱动方法)
思路:通过立方体投影(Cubemap)、切平面投影(Tangent)、二十面体投影(Icosahedron)等 , 将球面转换为多个畸变较小的子视图 。 优势:有效缓解极区畸变与接缝问题;能直接复用透视模型和大规模预训练网络;在几何敏感任务中表现突出;可根据应用灵活选择不同投影 。 局限:多视图信息碎片化 , 需要额外融合机制;计算与存储开销更高;部分投影方式需定制网络结构 。
③选型分析:
Distortion-Aware 适配:全局语义一致性与感知质量的任务(超分辨率、修复、补全、分割、检测 。 Projection-Driven 适配:强调局部几何精度的任务(深度估计、光流、关键点匹配、新视角合成;多模态融合任务 。
两大策略的交叉适配:
超分辨率:视频播放 / 沉浸显示→ Distortion-Aware(强调整体一致性);结构 / 精细重建→Projection-Driven(强调几何保真) 。文生图 / 视频生成:保证整体语义对齐→Distortion-Aware;提供更细粒度的局部几何控制→Projection-Driven 。
Physics-driven 适配:一些特异性的任务依赖物理先验(如光照估计、反射去除、布局检测) 。
任务工具箱
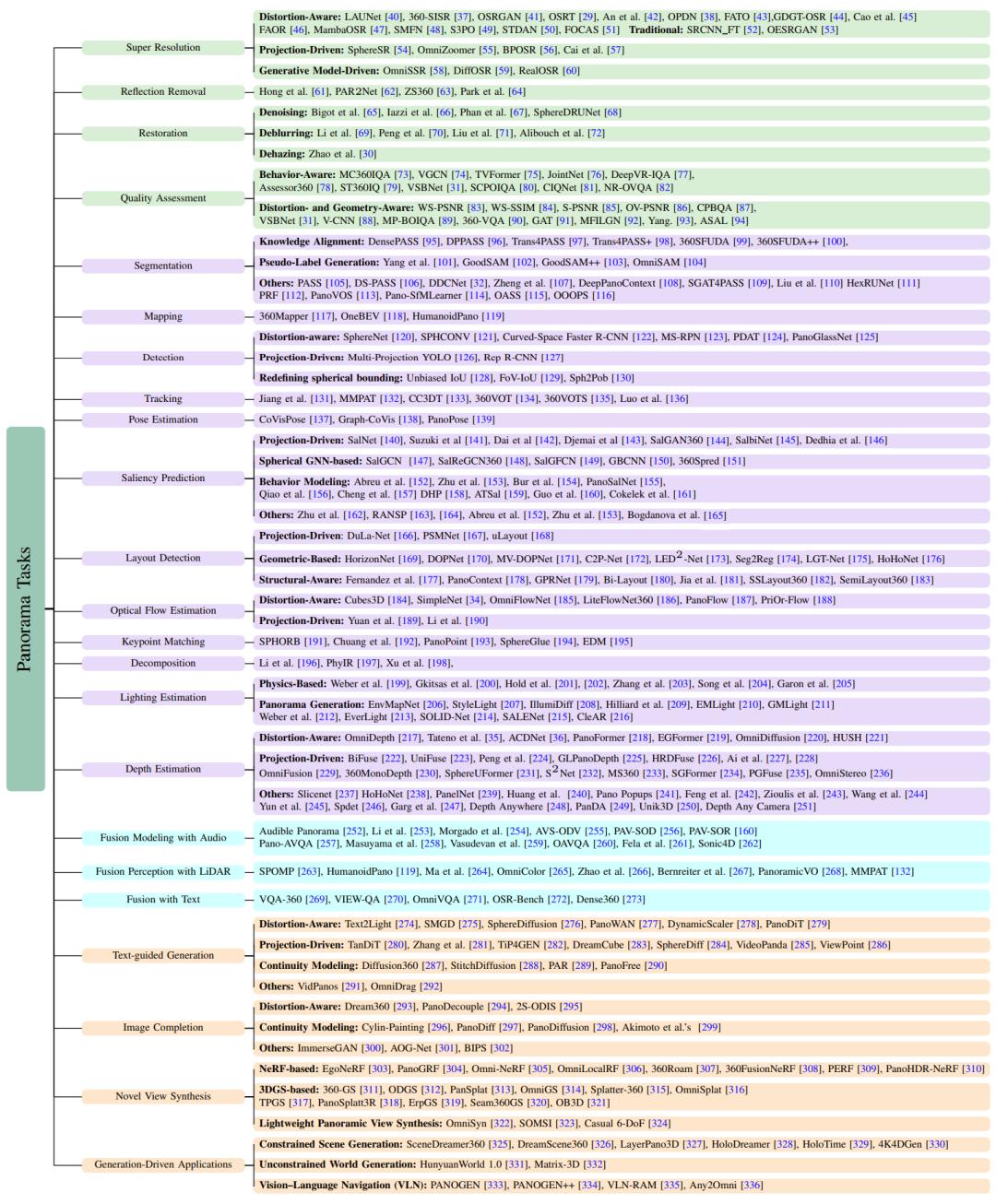
20+ 任务一览 , 按任务选策略
这是全文的横向 cross-task 对照表:将全景视觉的 20+ 代表性任务按四大板块归类(增强与评估、理解、多模态、生成) , 并在每个任务下标注了具有代表性的方法路线与代表工作 。 它与前一张 “cross-method” 图形成互补:前者 “纵向看方法→适配哪些任务” , 这张表 “横向看任务→常用哪些策略 / 里程碑工作” 。
具体地 , 左侧是任务清单 。 每一行右侧列出该任务的主流路线及典型论文 。 这让读者可以反向索引:从任务入手 , 快速定位合适的技术路线与关键文献 。 值得一提的是关于新范式加速渗透的整理:Diffusion / 生成式模型在 T2I/V、IC、NVS 与世界模型方向快速涌现 , 强调语义一致与可控性;3DGS:在 NVS / 场景重建中带来高效高保真渲染;多模态对齐尤其是音频 / 文本 / LiDAR 与全景的对齐成为新热点 。
未来展望
关于全景视觉的未来 , 要想从 “可用” 走向 “好用” , 需要在数据—模型—应用三条主线上同步推进:
(1) 数据瓶颈(图左上)
数量:缺少大规模、跨任务、跨场景的标准 360° 数据 , 限制通用训练与可复现评测 。多样性:过度集中于室内 / 城市场景 , 自然 / 空中 / 混合环境覆盖不足 , 难以走向开放世界 。质量:高质量、细粒度标注(深度 / 分割 / 检测 / 跟踪 / 建图)稀缺 , 真实场景标注成本高 。多模态:图文、视音频、LiDAR 等跨模态资源不足 , 制约 VQA、生成与对齐研究进程 。
(2) 模型范式(图右上)
基础模型:将对比 / 掩码 / 自监督迁移到全景视觉;从大规模透视模型迁移到全景域 , 强调零样本鲁棒性 。专家模型:面向检测 / 分割 / 深度 / 时序等 , 设计参数高效的全景专家模块 , 与预训练骨干解耦协同 。多模态:语言 - 音频 - 全景的空间连续性与对齐仍是难点;亟需理解+生成一体化与世界模型式框架 。全景生成:评测指标缺失、极区一致性、真实畸变复现、曲线运动轨迹建模与全景视频时空一致性是核心痛点 。
(3) 下游应用(图下)
空间智能与自动系统:具身智能、自动驾驶、UAV 导航 , 依赖无盲区全局感知与稳健决策 。XR 与沉浸式交互:全景录制与高分辨生成 + 空间音频 / 触觉等多感官 , 走向轻量化穿戴端 。三维重建与数字孪生:全景→完整重建 / 数字孪生 , 支撑智慧城市 / 文博修复等 。广泛的社会应用:安防、教育、文娱、医疗等行业化场景 , 强调可部署性与合规性 。
结语
透视到全景并非一次简单的 “投影转换” , 而是一场贯穿数据、模型与应用的系统性升级 。 本综述以 “透视—全景 gap” 为主线 , 梳理挑战、方法与未来应用 , 为研究者与工程团队提供按任务选型的 “路线图” 。 我们也欢迎社区共同完善基准与数据 , 推动全景视觉在 XR、机器人系统与数字孪生等关键场景中真正 “好用、可用、可落地” 。
【Insta360最新全景综述:全景视觉的挑战、方法与未来】更多细节与完整方法清单 , 请查阅论文与项目主页 。
推荐阅读














- 任何游戏都能用!AMD AFMF 3帧生成现身最新驱动
- 直击CoRL|跨越“Sim-to-Real”天堑 NVIDIA解锁物理AI全景图
- 小米未上榜,全球智能手机 AP-SoC 市场份额最新排名出炉!
- 郭明錤最新分析:小米17系列砍单20%,官方已迅速回应!
- 华为盘古718B模型最新成绩:开源第二
- Flash Attention作者最新播客:英伟达GPU统治三年内将终结
- 黄仁勋最新访谈:没人需要原子弹,但人人都需要人工智能!
- Meta最新研究RecoWorld,从「猜你喜欢」到「听你指令」
- AMD最新专利:内存带宽翻倍!
- 刚刚谷歌发布机器人最新大脑模型!思考能力SOTA,还能跨物种学习