
文章图片

文章图片

文章图片

文章图片
文章图片
文章图片
文章图片
文章图片
文章图片

文章图片
文章图片
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
能看懂视频并进行跨模态推理的大模型Keye-VL 1.5 , 快手开源了 。
相比此前的预览版本 , Keye-VL 1.5的时序定位能力进一步升级 , 并且支持跨模态推理 。
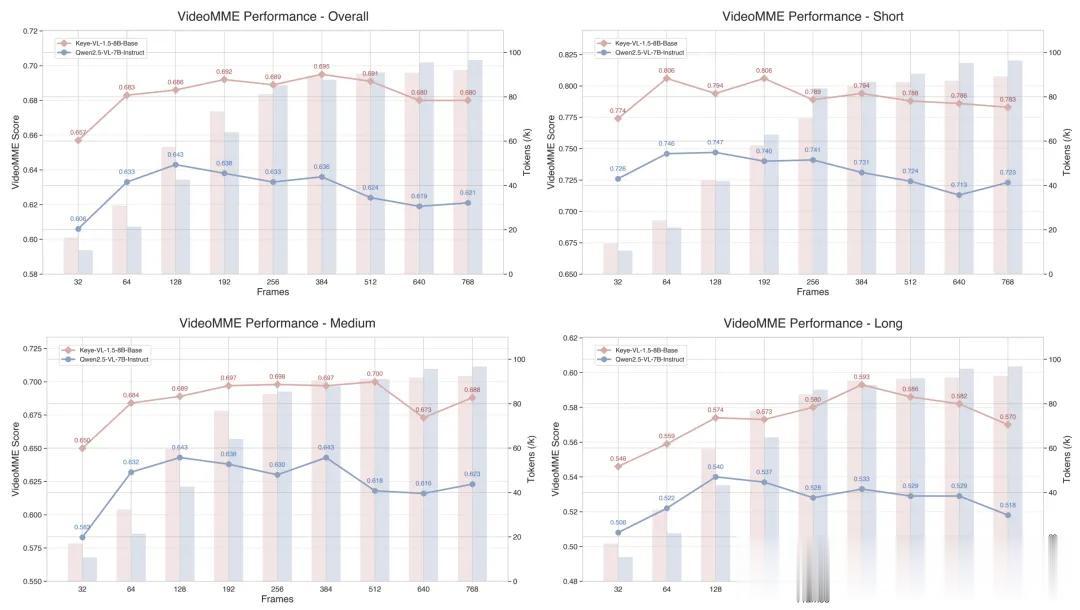
还创新性地提出Slow-Fast双路编码机制 , 给模型带来了128k的超长上下文窗口 , 而且速度与细节兼顾 。
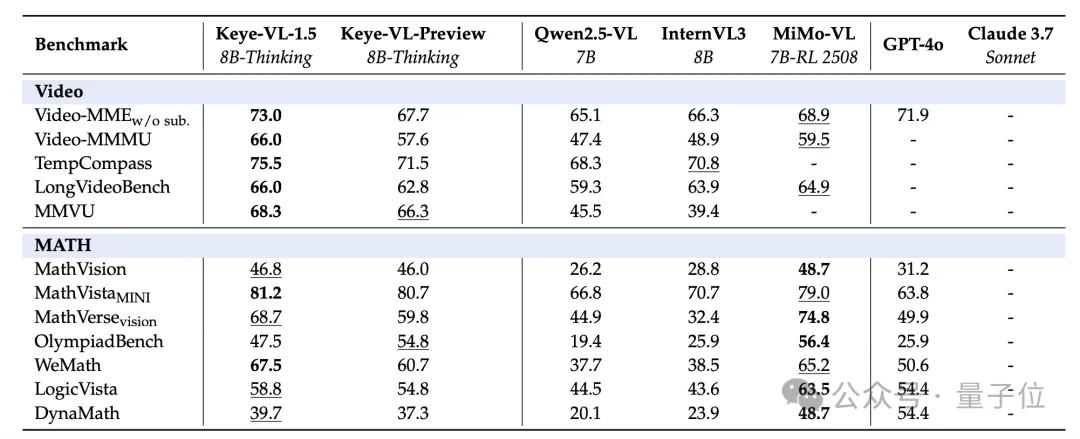
成绩上 , 不仅在Video-MME短视频基准斩获73.0的高分 , 还在通用、视频和推理场景的大量Benchmark当中领跑同级模型 。
视频元素0.1秒级定位 , 还支持推理要说Keye-VL-1.5最大的亮点 , 研究团队认为主要有三个 , 也就是开头提到的128k上下文、突出的短视频理解能力、 以及更强的Reasoning能力 。
在视频理解场景当中 , 这三项能力能够同时得以展现 。
首先是时序信息理解 , Keye-VL-1.5能够准确判断特定物品在视频中出现的时间点 , 而且精确到0.1秒级 。
比如在这段26秒带货视频片段中 , 介绍了一款充电宝 , 其中一个环节是将其装进包包 , 以体现便于携带 。
Keye-VL-1.5看完这段视频后 , 准确回答出了其中包包出现的时间——22.3-23.8秒 。
而其他模型或者时间只精确到秒而且还不准确 , 或者干脆不说时间 , 直接数起了镜头 。
再来是描述能力 , Keye-VL-1.5能够详细描述视频画面场景和细节 。
例如对于上面这段视频 , Keye-VL-1.5给出了这样的描述:
并且Keye-VL-1.5还具备视频推理能力 , 能够根据前序视频内容推断后续事件发生原因 。
在这段宠物视频当中 , 大狗做出了一个咬小狗耳朵的动作 , 而Keye-VL-1.5要分析大狗为什么要咬 。
其实答案在视频当中已经以文字的形式写了出来 , 但是Keye-VL-1.5的解释更加详细 , 并进一步用视频中的后续变化来加强自己的观点 。
跑分方面 , Keye-VL-1.5在多项公开Benchmark以及内部评测中都拿到了同尺寸模型中的最高分 。
在MMBench、OpenCompass等综合类基准中 , Keye-VL-1.5的成绩均超越Qwen2.5-VL 7B , 并取得多个SOTA 。
在图像推理强相关的AI2D、OCRBench等数据集中 , 也均超出同级其他模型 。
针对视频理解 , Keye在Video-MME、TempCompass和LongVideoBench上 , 成绩同样领先于Qwen2.5-VL 7B等模型 。
包含视觉的数学与逻辑推理维度上 , Keye也保持了领先优势 。
除了这些公开数据集 , Keye团队还构建了200条面向短视频应用的内部多维度评测 。
Keye-VL-1.5-8B在人类标注的五项指标(正确性、完整性、相关性、流畅度、创造性)上获得3.53分的综合成绩 , 较预览版本提升了0.51分 , 也超过了作为对比的竞品模型 。
那么 , Keye-VL是如何实现的呢?
视频理解 , 也用上了快慢思考★模型架构和快慢编码策略
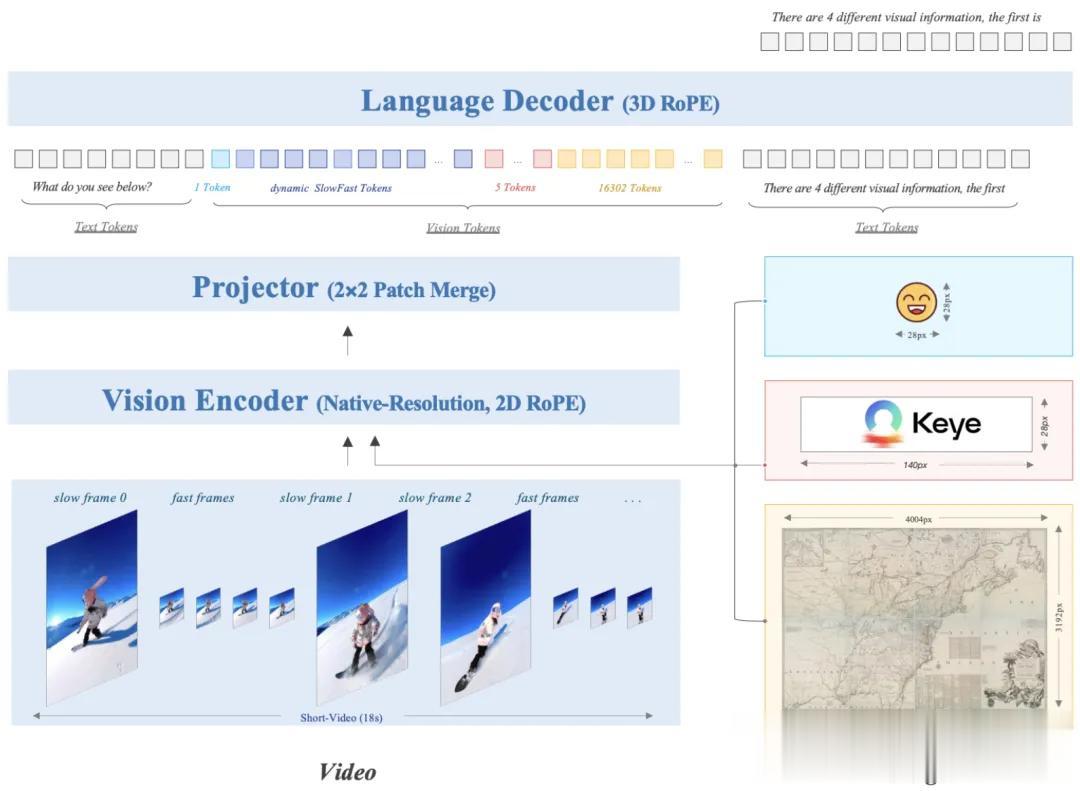
整体设计上 , Keye-VL-1.5采用了“视觉Transformer(ViT)+MLP投影器+语言解码器”的三段式架构 。
ViT将输入图像或视频帧切成14×14的patch序列 , 用自注意力捕捉全局空间关系 。
该ViT在初始化时直接继承SigLIP-400M参数 , SigLIP是一种图文对比预训练方法 , 可让视觉特征天然带有语义对齐能力 。
为了在不裁剪的情况下处理任意分辨率 , 团队对ViT添加了“原生分辨率”支持 , 操作上先把绝对位置向量插值到任意尺寸 , 再引入2DRoPE(二维旋转位置编码)增强高分辨率外推 。
ViT输出的patch特征经由两层MLP投影器送入语言解码器 , 语言端采用Qwen3-8B , 并在其位置编码中加入3DRoPE 。
3DRoPE是在传统二维旋转角的基础上再增加一维“时间/深度”角度 , 目的是让文本token与视觉token按统一时序排序 。
针对视频的高帧率与高分辨率矛盾 , Keye-VL-1.5还创新性地提出Slow-Fast编码策略 。
模型首先会对连续帧做patch级余弦相似度计算 , 若与最近一次“慢帧”(又称变化帧 , 低帧数高分辨率)相似度95%则判定为“快帧” (又称静止帧 , 高帧数低分辨率) , 否则标记为新“慢帧” 。
处理时 , 慢帧保留高分辨率 , 快帧分配慢帧30%的token预算 , 再结合二分搜索 , 能够让总预算精确落在限制内 , 并在序列里插入时间戳特殊符号以标注帧界 。
通过这种视频快慢编码策略 , Keye实现了性能与计算成本的有效平衡 。
★四阶段渐进式预训练
预训练采取四阶段渐进流水线 , 按照“先单模后多模、先对齐后扩窗”的顺序展开:
Stage0 , 视觉编码器预训练:仅用SigLIP对比损失继续训练ViT , 强化视觉语义 , 适应内部数据分布; Stage1 , 跨模态对齐:冻结ViT与Qwen , 只训练MLP投影器进行大规模跨模态对齐; Stage2 , 多任务预训练:解冻全网络 , 在8K上下文下端到端优化 , 增强模型的基础视觉理解能力; Stage3 , 退火训练: 在精选高质量数据上进行微调 , 引入长上下文模态数据 , 把上下文拉长到128K 。
整个预训练语料超过1万亿token , 数据源既包含LAION、DataComp、CC12M等公开多语言图文库 , 也有大规模自建图像、视频与文本 。
四阶段结束后 , Keye团队对不同数据配比训练的“同质”权重与针对OCR、数学等薄弱项单独强化得到的“异质”权重进行模型融合 , 以减小偏差并提升鲁棒性 。
“同质模型”指的是在退火期采用相同网络结构和相似任务目标 , 但调整数据配比、样本难度或随机种子训练出的多份主干权重 , 这些模型彼此性能分布接近;
“异质模型”则是利用与主干不同的专用数据域进行进一步精调而生成的专家权重 , 例如团队针对车牌、票据和街景文字额外收集/合成数据训练出的OCR-Expert 。
由于双方架构一致 , 融合过程可以通过直接权重插值实现 , 不引入推理时额外开销 , 却能将专家的局部能力注入通用模型 。
★Post-training
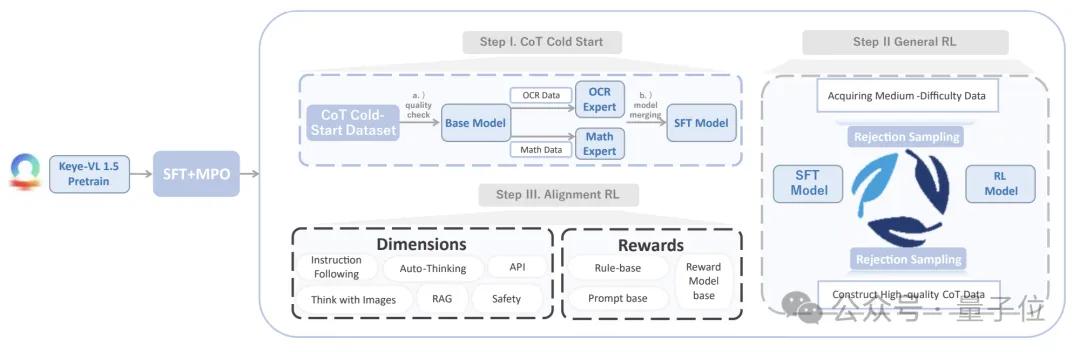
Keye-VL-1.5的训练后处理包含四个主要阶段:
第一步用监督微调结合多偏好优化(MPO)建立输出质量基线; 第二步通过五步流水线的大规模链式思考数据冷启动 , 为模型提供可靠的推理示范; 第三步在可验证奖励框架下采用GSPO算法并配合渐进提示采样做多轮强化学习 , 系统化提升通用推理能力; 最后一步以规则-生成式-模型三源奖励完成对齐强化学习 , 重点加强指令遵循、格式一致性与用户偏好一致性 。
在监督微调阶段 , 团队先构建包含750万多模态问答的候选池 , 用TaskGalaxy将样本映射到七万种任务标签 , 再刻意提高高难度类型的占比 。
随后进入MPO , 以25万开源、15万纯文本和2.6万人工样本为基底 , 利用Keye-Reward模型分数和人工评估构造高低质配对 , 通过偏好损失函数让模型在同一问题上倾向得分更高的答案 , 从而进一步提升回答质量 。
有了质量可控的答案后 , 模型借助链式思考冷启动流水线迅速补齐推理深度 , 先自动生成带步骤的解答 , 再由第二模型逐步打分进行分级 , 中档样本经人工精修后复审 , 高分样本直接入库 , 为后续强化学习提供可靠冷启动权重 。
接下来进入通用强化学习 , 系统首先按照样本难度分组 , 然后利用GSPO在组内基于序列重要性权重裁剪优势函数 , 缓解长序列梯度不稳 。
当推理能力趋于收敛后 , 训练转入最后的对齐阶段 。
规则奖励通过正则和AST解析强制检查JSON、Markdown等结构与内容安全 , 生成式奖励由外部大模型评估逻辑一致性与语言风格 , 模型奖励则来自Keye-Reward模型的细粒度偏好分 。
三类信号动态加权 , 使最终模型既能遵循指令又能保持格式正确并符合用户偏好 , 同时有效降低无依据生成风险 。
团队成果多次亮相顶会说到快手大模型 , 我们可能更熟悉视频生成模型可灵 , 但实际上 , 快手在其他类型的大模型上同样有很强的实力 。
打造Keye-VL的Keye团队 , 是快手内部专注多模态大语言模型研发的核心AI部门 , 主攻视频理解、视觉感知与推理等前沿方向 。
Keye团队认为 , 整合视觉、语言和行为等多源数据的智能体 , 对于解锁更深层次的认知和决策至关重要 。
目前 , Keye团队已经拥有大量成果 , 在今年的多个顶会上密集发布 。
ICML 2025上 , Keye团队提出了多模态RLHF框架MM-RLHF(2502.10391) , 通过120k人类偏好对比与批评式奖励模型 , 显著提升MLLM安全性及对齐性能 。
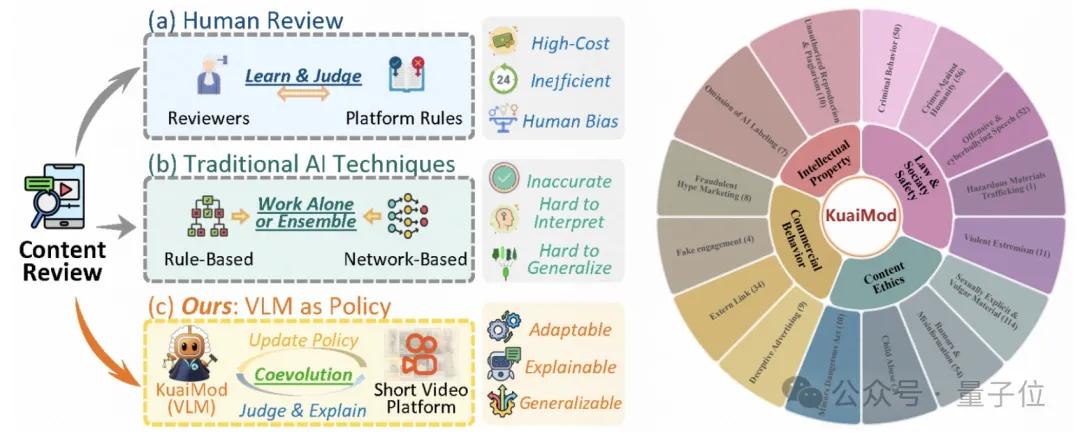
KDD 2025上 , 视觉语言模型治理框架VLM as Policy(2504.14904)获得了最佳论文提名 。
该框架通过VLM驱动内容质量与风险判定 , 显著提高短视频审核效率与准确率 。
CVPR 2025上 , Keye团队也发布了两项成果 。
交错图文多模态数据集CoMM(2406.10462) , 提供了高一致性图文叙事样本 , 从而增强模型图文穿插理解与生成能力 。
视觉token压缩加速算法LibraMerging , 采用位置驱动合并 , 在无需再训练的情况下大幅降低推理开销 。
还有ICLR 2025中 , Keye有三项研究成果亮相 , 包括一种优化算法和两个数据集 。
MoE模型优化算法STGC(2406.19905) , 可以检测token梯度冲突并进行重路由 , 提升专家利用率与收敛速度 。
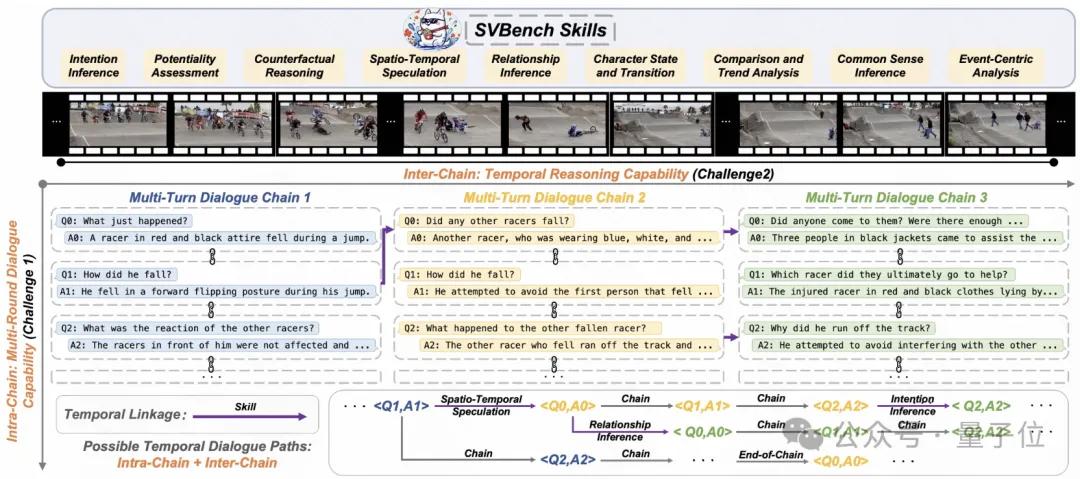
视频对话理解基准SVBench(2502.10810) , 构建了时序多轮问答链 , 评测LVLM在流式长视频场景的推理水平 。
还有视觉任务指令数据集TaskGalaxy(2502.09925) , 可以自动生成万级层级任务与40万余样本 , 增强模型跨任务泛化能力 。
在快手内部 , Keye团队的这一系列成果 , 正在为短视频内容审核、智能剪辑、搜索与互动推荐等业务场景提供底层AI能力 。
Keye正在把多模态技术从实验环境推向千万级日常场景 , 验证复杂视频理解在真实业务中可行且高效 , 为同类技术的工程化落地提供了直接样本 。
技术报告:https://arxiv.org/pdf/2509.01563代码:https://github.com/Kwai-Keye/Keye/blob/main/Kwai_Keye_v1_5.pdf模型权重:https://huggingface.co/Kwai-Keye/Keye-VL-1.5-8B在线DEMO:https://huggingface.co/spaces/Kwai-Keye/Keye-VL-1_5-8B
— 完 —
量子位 QbitAI
【视频理解新标杆,快手多模态推理模型开源】关注我们 , 第一时间获知前沿科技动态
推荐阅读













- 「一句话生成爆款视频」,这款 AI 流量神器有点东西|AI 上新
- 重新定义个性化视频体验,快手与清华联合提出灵犀系统
- 提升全面,右手对称鼠标新标杆!体验雷柏VT7系列双模双高速游戏鼠标
- 跟谷歌学坏了,三星也发视频“阴阳”苹果没有折叠屏,AI也不行
- 群核科技发布空间大模型,旨在解决AI视频空间一致性难题
- DJI Mic 3首发评测:机身mini体验旗舰,无线麦克风新标杆?
- vivo Y500评测:超耐用大电池,入门机新标杆
- 刚刚,大模型装上鹰眼!首创高刷视频理解,谷歌Gemini 2.5完败
- Reels支持翻译对口型,Meta短视频的“全村希望”正在靠AI突围
- 视频产业的创意活力,被百度蒸汽机这颗“动力心脏”激活了