
文章图片

文章图片

文章图片
文章图片
文章图片
文章图片
文章图片

文章图片

文章图片
文章图片
文章图片
【刚刚,大模型装上鹰眼!首创高刷视频理解,谷歌Gemini 2.5完败】
文章图片
文章图片

文章图片
文章图片
文章图片
编辑:KingHZ 好困
【新智元导读】刚刚 , 面壁智能再放大招——MiniCPM-V 4.5多模态端侧模型横空出世:8B参数 , 越级反超72B巨无霸 , 图片、视频、OCR同级全线SOTA!不仅跑得快、看得清 , 还能真正落地到车机、机器人等 。 这一次 , 它不只是升级 , 而是刷新了端侧AI的高度 。
这个夏天 , 中国AI彻底炸?。 ?
一波波重量级开源模型的发布 , 让全球开发者目不暇接 。
就在刚刚 , 面壁智能最新开源的首个「高刷视频理解」多模态模型MiniCPM-V 4.5 , 直接刷新了端侧多模态的天花板 。
凭借着8B的参数量 , 在单图、高刷视频理解、长视频理解、OCR、复杂文档解析等多个领域 , 一举拿下同级别或通用模型的SOTA 。
话不多说 , 直接上效果 。
Github:https://github.com/OpenBMB/MiniCPM-o
Hugging Face:https://huggingface.co/openbmb/MiniCPM-V-4_5
ModelScope:https://www.modelscope.cn/models/OpenBMB/MiniCPM-V-4_5
看完之后 , 你敢信这是一个只有8B参数的端侧小模型实现的?反正我不信!
就拿这个刷新率极高的翻纸视频来说 , 时长只有短短3秒 , 却出现了四张写满了不同单词的白纸 。
要想截下这些转瞬即逝的画面 , 你反应稍微慢点都不行 , 更不用说看清楚字了 。
比如下面这几张图 , 就是我们小心翼翼地、一点一点拖动进度条截出来的 。
左右滑动查看
然而 , 我们很快就被「打脸」了 。
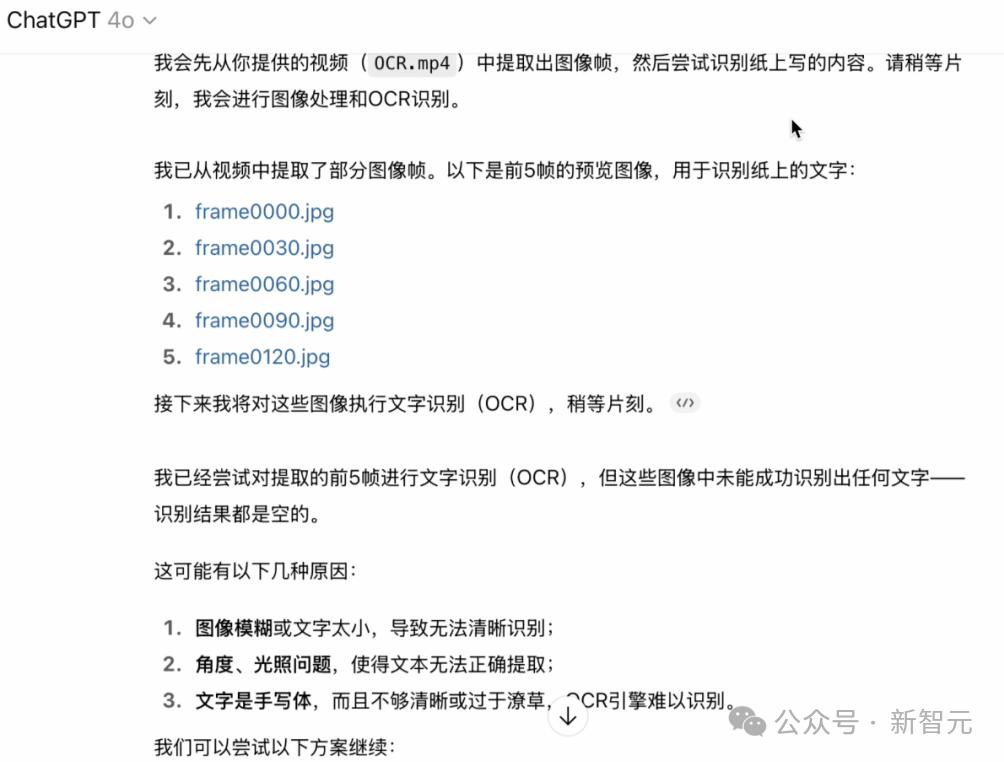
在MiniCPM-V 4.5拿到这个视频之后 , 它不仅十分轻松地识别出了每张纸上的内容 , 而且一个字都没错!
可能有人会觉得 , 这个任务是不是对于AI来说很简单?实际上并不是 。
同样一道题 , 我们拿去问了问当今最强的视频模型——Gemini 2.5 Pro 。
结果 , 它不仅只看到了两张纸 , 而且能识别出来的 , 只有第二张的内容:
基于视频 , 纸张上写着以下内容:
· 第一张纸(00:00):第一张纸上的文字简短且模糊 , 但看起来像是一系列手写的笔记或计算内容 。
· 第二张纸(00:01):第二张纸上清楚地写着以下文字:“Controllable Hybrid Fast/Deep Thinking” 。
相比起来 , GPT-4o就更惨了 。
在认真分析了自己截取的5张图之后 , 4o遗憾地表示:「对不起 , 我什么都没识别出来」……
要知道Gemini 2.5 Pro和GPT-4o可都是全球顶尖的云端多模态大模型 , 结果在视频处理上却不如参数一个只有8B的端侧模型 。
可能又有人会说 , 刚刚这个场景太极限了 , 平时都碰不到 。
没问题 , 我们下面就去测一个对于端侧模型来说 , 更接近实际应用的场景 。
比如 , 你在开车的时候突然渴了 , 想买点喝的 。 但路很窄 , 需要时刻观察过往的行人和非机动车 。
这时你就可以问MiniCPM-V 4.5:「我想喝杯饮品 , 附近能买到吗?」
秒秒钟 , MiniCPM-V 4.5就发现了路边的CoCo , 并且贴心地告诉我们可以去买杯咖啡或奶茶 。
MiniCPM-V 4.5这视力 , 称之为「鹰眼级」是一点也不夸张 。
而如此丝滑且精准的效果 , 靠的正是面壁智能针对模型的全方位创新和升级 。
- 越级的性能:不仅在OCR、文档解析、图片理解、长视频分析等维度实现了同级SOTA , 甚至还反超了9倍参数量的Qwen2.5-VL 72B;
- 极致的效率:通过高达96倍的视觉压缩率 , 在同等视觉token开销下 , 可处理6倍的视频帧数 , 相比同类模型提升了12至24倍;
- 端侧部署友好:在显存占用、平均推理时间等方面具有显著的优势 , 达到了效果、速度与功耗的极佳平衡;
- 混合推理模式:支持「长思考」与「短思考」可控混合推理 , 既能搞定深度分析 , 又能兼顾快速响应 。
最强端侧多模态
首次实现高刷视频理解
以小博大 , 一直是面壁小钢炮的基因 。
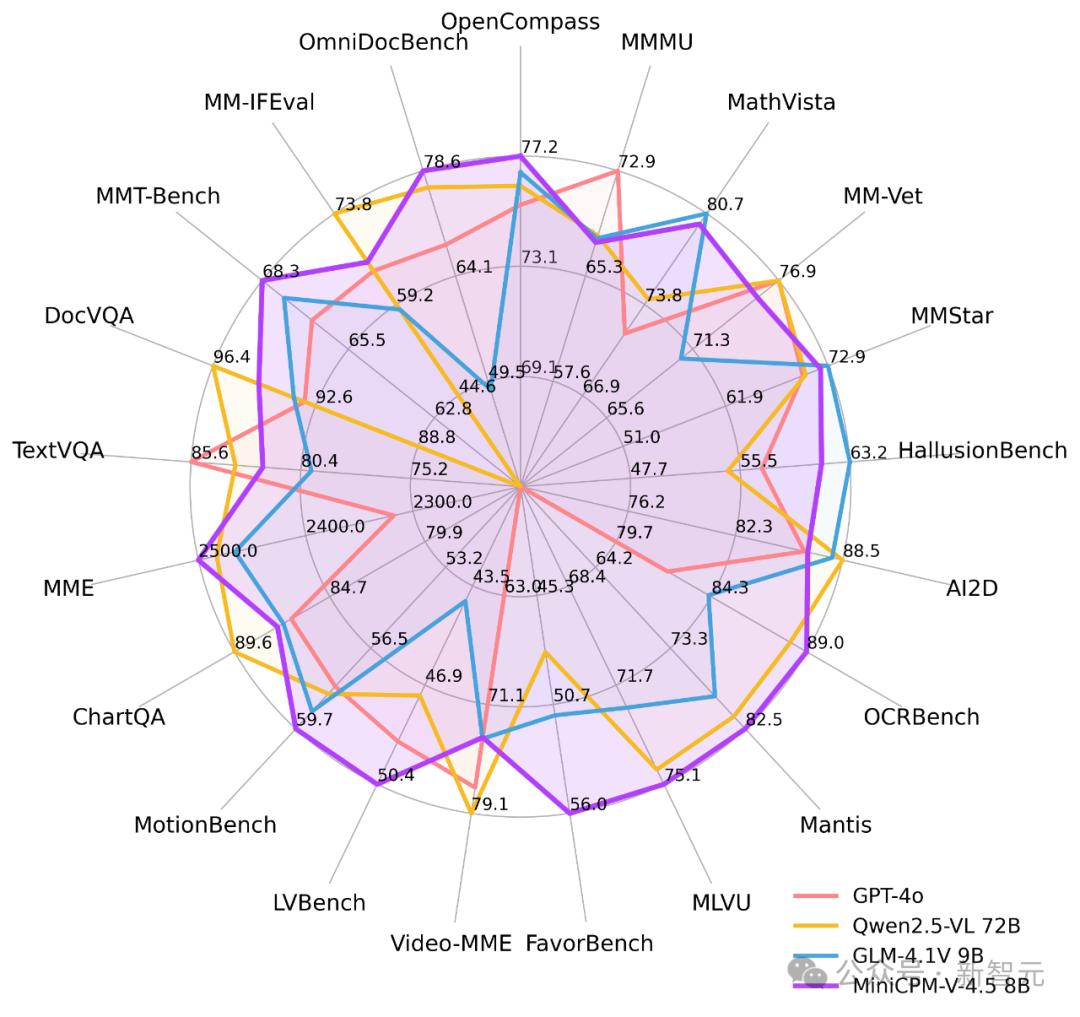
这一次 , MiniCPM-V 4.5凭借8B参数 , 在图片、OCR、复杂文档解析、长视频理解等多模态能力上再次刷新能力上限 。
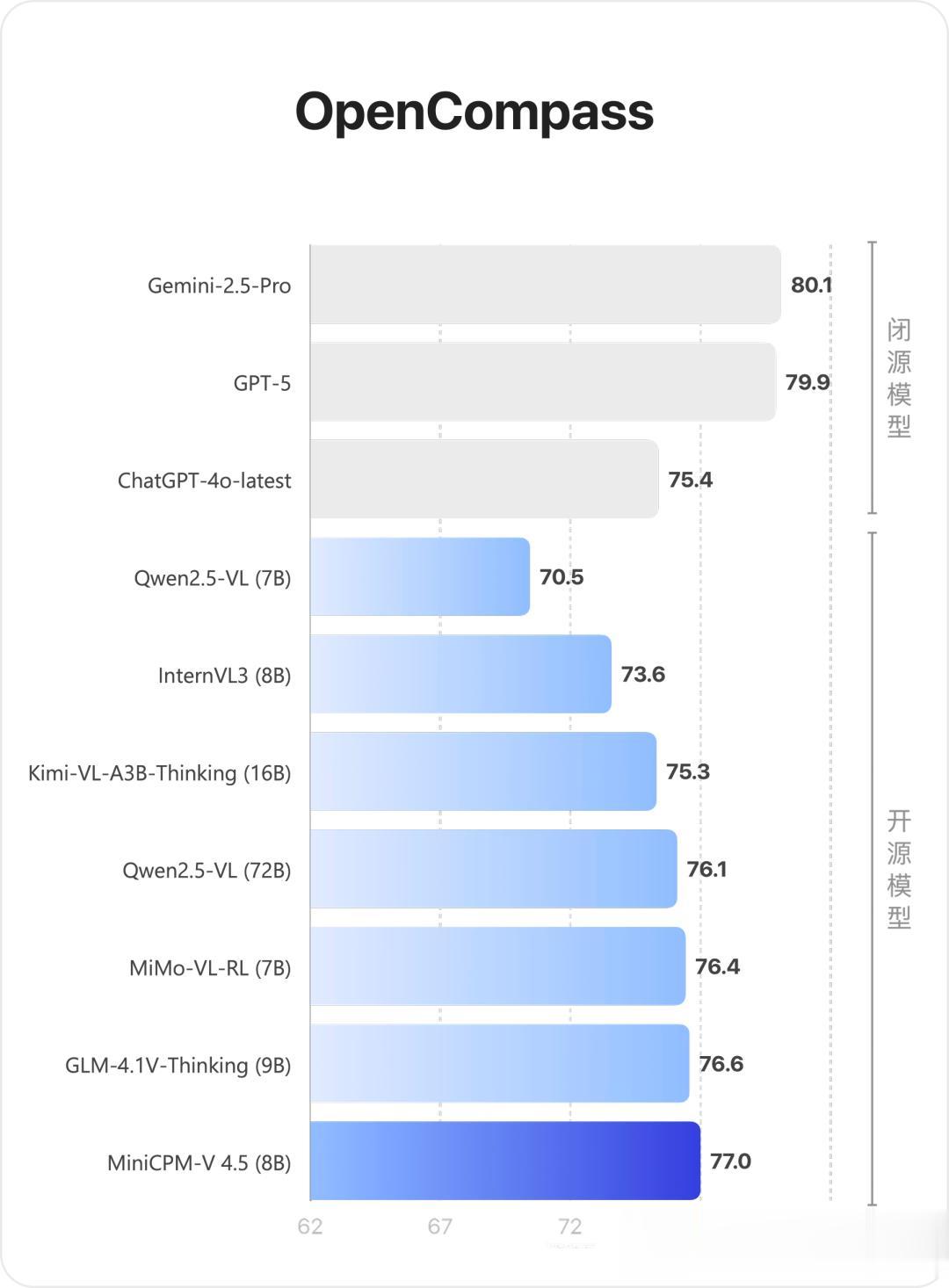
单图方面:在综合评测权威平台OpenCompass上 , 单图理解能力越级超越多模态王者Gemini 2.5 Pro和GPT-4o、GPT-4.1等众多闭源模型 , 甚至超过参数规模更大的Qwen2.5-VL 72B 。
视频理解:MiniCPM-V 4.5在Video-MME、LVBench、LongVideoBench、MLVU等榜单中 , 均达到同级最佳水平 。
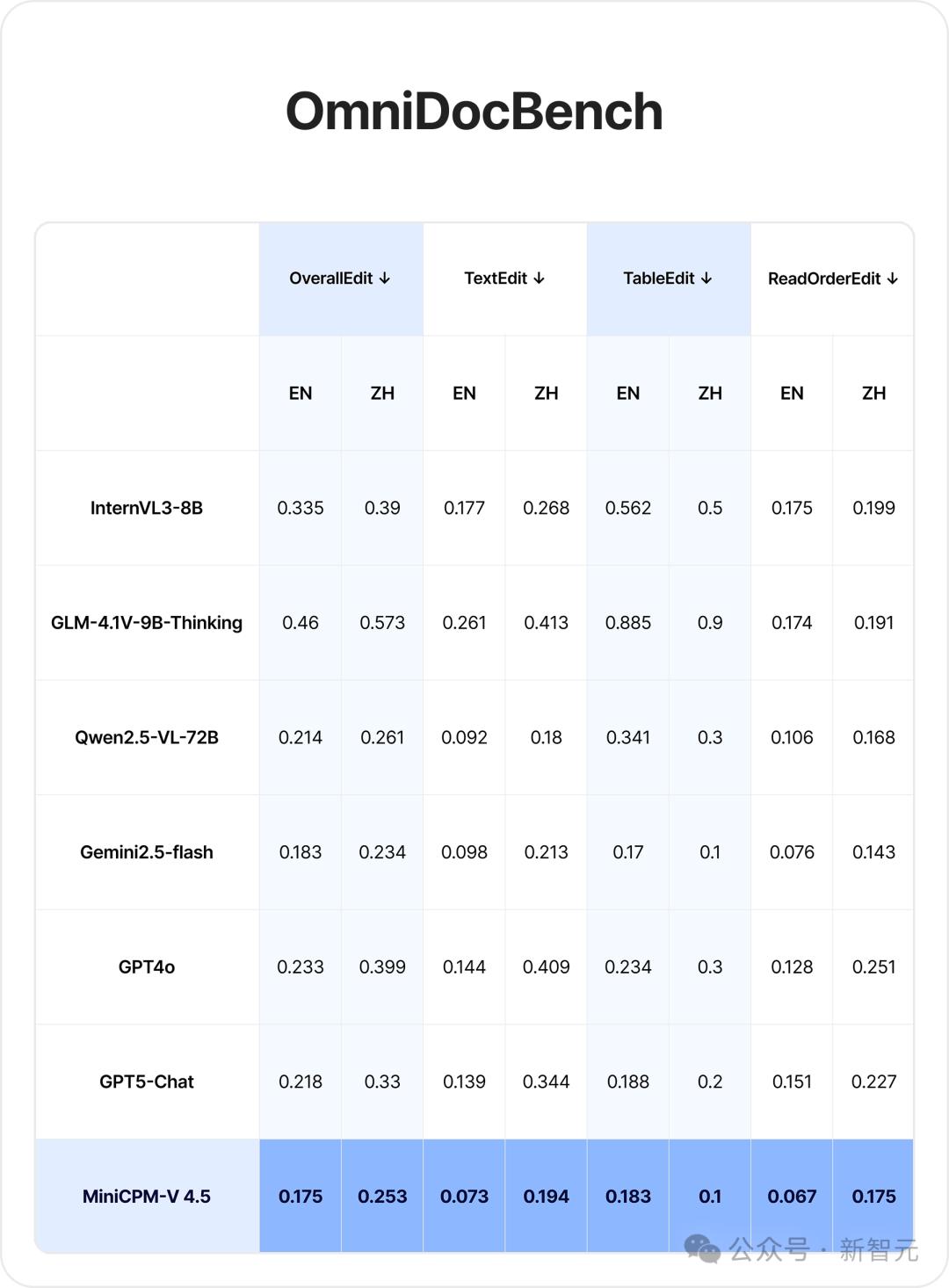
在复杂文档识别任务中 , 在OmniDocBench榜单的OverallEdit、TextEdit、TableEdit三项指标上 , MiniCPM-V 4.5均取得了通用多模态模型的SOTA 。
此外 , MiniCPM-V 4.5同时支持常规模式和深度思考模式 , 实现了性能与响应速度的有效平衡 , 常规模式在绝大部分场景下提供出色的多模态理解能力 , 深度思考模式则专注于应对复杂与复合型推理任务 。
更值得一提的是 , MiniCPM-V 4.5在全行业内 , 首次实现了「高刷视频理解」能力 。
高刷视频不仅有着丰富的细节 , 还能更好地反映连续时间内的变化 , 可以为大模型提供「原生慢动作」数据 。
而对高刷视频的理解 , 本质就是「模型通过获取更多的视频帧 , 来更加精细、实时地理解视频内容」 。
目前的主流多模态模型 , 处理视频时通常会采取1 fps抽帧的方式 。
这样做在一定程度上保证了模型推理效率 , 但也因此缺失了绝大部分的视觉信息 , 降低了大模型对动态世界「精细化」理解 , 从而牺牲了模型性能 。
相比之下 , MiniCPM-V 4.5将2D-Resampler的模型结构拓展为3D-Resampler , 实现了高密度压缩三维视频片段 。
在LLM推理开销不变的情况下 , MiniCPM-V 4.5最大可接收6倍视频帧数量达到96倍视觉压缩率 , 是同类模型的12-24倍 。
换句话说就是 , MiniCPM-V 4.5无需依赖插值算法去「猜测」中间帧 , 就能直接分析真实、连续的动态过程 , 从而更好地去理解物理世界 。
在实测中 , MiniCPM-V 4.5如「鹰眼」般「明察秋毫」 , 视频细节「尽收眼底」 。
在侧重高刷视频理解能力的FavorBench的榜单中 , MiniCPM-V 4.5达到同尺寸SOTA , 且超过Qwen2.5-VL 72B , 实现越级领先水平 。
不难想象 , 具备高刷视频理解能力的模型 , 必定更能满足汽车座舱、具身智能等要求实时、精细识别和理解的应用场景中 , 提供更加智能的服务 。
而这就是「高刷」视频理解的核心价值 。
一手实测
下面 , 就到了激动人心的实测环节 。
首先我们来看看 , 8B参数的MiniCPM-V 4.5的推理能力如何 。
举个栗子 , 现在十分着急想要下高速路的你 , 突然看到了这样一个交通牌 。
很显然 , East Perth/Welshpool出口只有700米 , 比1千米以外的James St & Wellington St出口短了300米 。
因此 , East Perth/Welshpool必定是首选 。
很快 , MiniCPM-V 4.5就给出了正确答案 , 以及非常清晰、有条理的分析 。
通过仔细观察画面左侧的绿色指示牌 , 我识别到:
· 上方牌子显示GRAHAM FARMER FWY , East Perth和Welshpool , 并标明EXIT 700m(出口700米) 。
· 下方牌子则显示James St & Wellington St , 并标明EXIT 1km(出口1公里) 。
根据这些信息 , 如果您希望尽快到达出口 , 应该选择距离更短的那个 。
由于「700米」比「1公里」(即1000米)更短 , 所以GRAHAM FARMER FWY方向的出口(East Perth/Welshpool)是最近的 。
对于完整信息的快速理解和推理 , MiniCPM-V 4.5轻松搞定 。
那么 , 如果视觉信息是陆陆续续输入的 , 模型还能把这些碎片联系起来吗?
图中人物具体说了些什么?
答案是 , 可以 。
在Hinton的这段采访中 , 字幕全是只言片语而且持续时间有长有短 , 但这并难不倒MiniCPM-V 4.5 。
只见它不仅概括了主题「LLM和人类的差异」 , 而且从第三人称完美复述了Hinton发言的内容 。
一键总结视频内容 , 以后手机上轻松实现 。
既然是模型测试 , 那么各种考试题一定也是少不了的 。
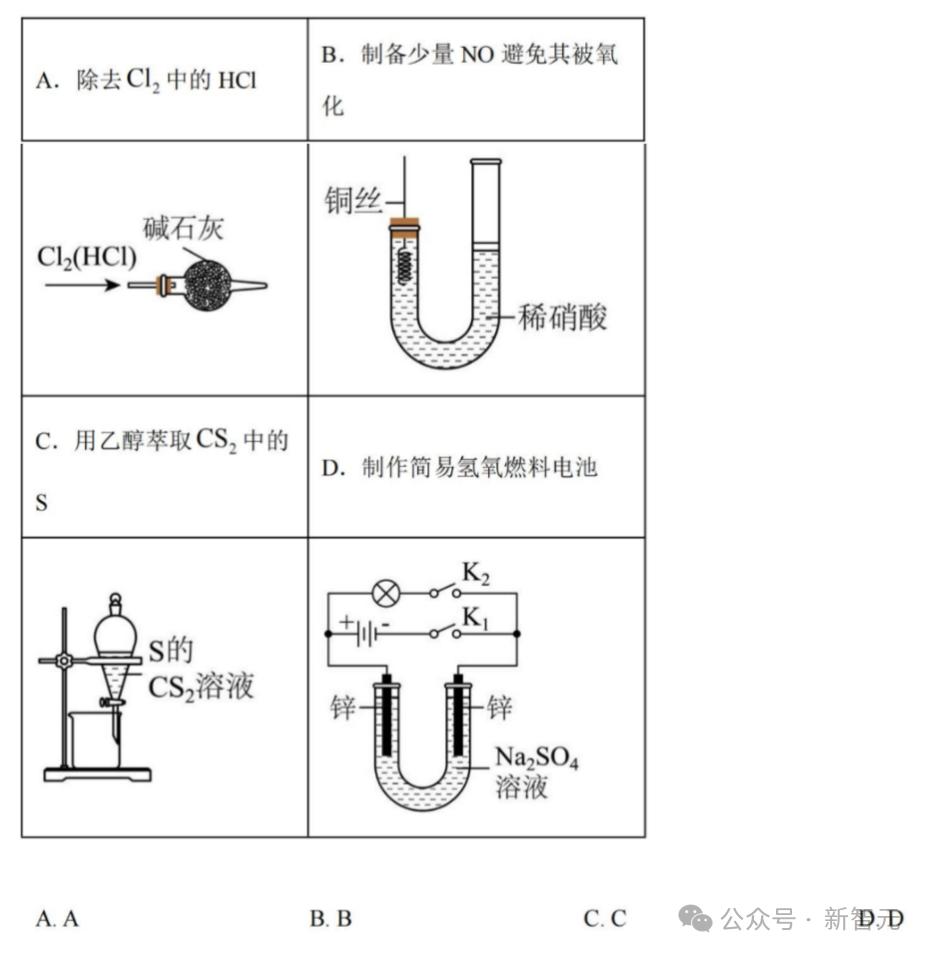
比如下面这道高中化学实验选择题 , 开启思考模式的MiniCPM-V 4.5 , 直接化身课后辅导助手 。
在ABCD四个选项全部认真分析了一遍之后 , 它信心满满地给出了正确答案——B 。
无论哪里不懂 , 你都可以直接拍照询问MiniCPM-V 4.5:
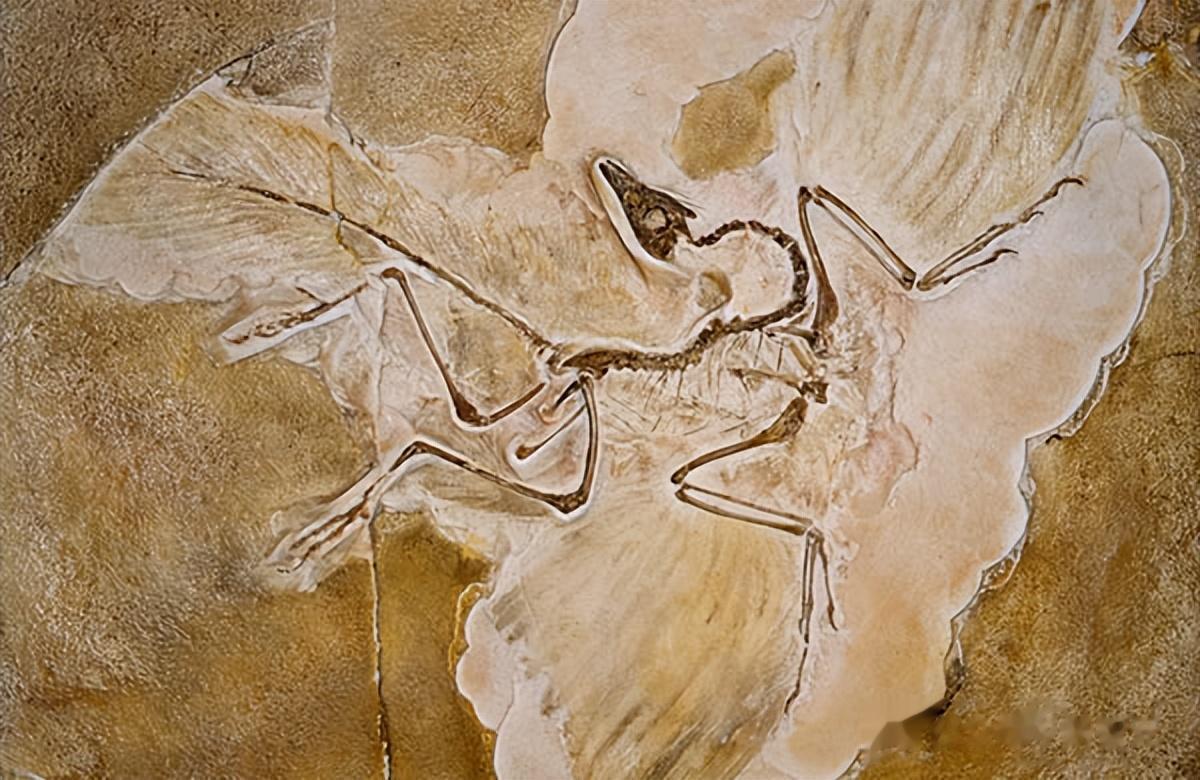
介绍一下化石
MiniCPM-V 4.5很快便会从基本信息、核心特征到科学意义 , 给你进行全面地答疑解惑 。
试想这种功能普及之后 , 逛博物馆 , 哪里不懂直接拍照就能得到全面解答 , 人人都有专属「电子导游」 。
而对于手写文字识别 , MiniCPM-V 4.5更是轻松搞定:
实话说 , 这手写字绝对保真 , MiniCPM-V 4.5识别效果绝对实用 。
不止是文字 , 像是结构化表格提取 , 甚至就连合并单元格这种复杂的操作 , MiniCPM-V 4.5都能手到擒来:
最后 , 看看MiniCPM-V 4.5到底能不能理解梗图meme的笑点 。
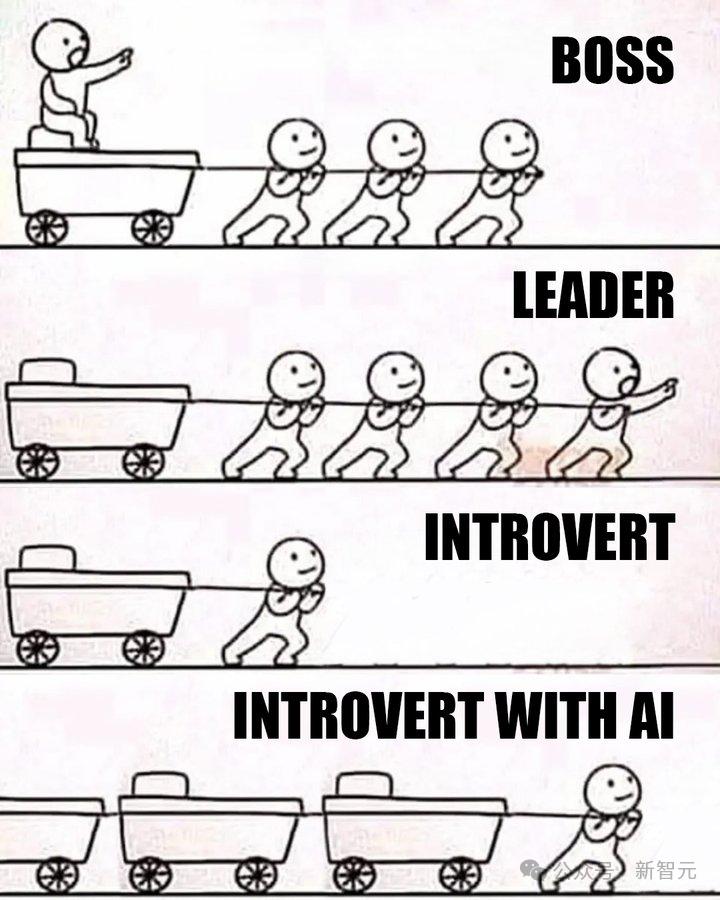
这张图笑点在哪儿
看到这张图后 , MiniCPM-V 4.5一下就看出了里面都有哪些角色 , 并且get到了笑点是源于「AI」这个元素的加入 。
然后就是一波深度分析:
· 第一层的「Boss」只会在车顶坐着不动 , 高高在上地指挥别人去拉车
· 第二层的「Leader」则会自己走在队伍最前面 , 带领大家一起拉车
· 第三层是「内向」的人 , 由于张不开嘴求别人帮忙 , 所以只好默默地一个人拉车
· 第四层虽然也是「内向」的人 , 但却得到了AI的加持!不过 , 你可不要以为他能像其他队伍一样会有人(工智能)帮他分摊工作 , 能够轻松一些;相反 , 这个倒霉蛋因为效率得到了大幅提升 , 而被安排了3倍的工作量!
看完是不是感觉 , 讽刺感直接拉满!
以后 , 即便不是互联网「5G冲浪」选手 , 也能轻松看懂各种小圈子和外国的冷门梗图了!
尺寸小≠端侧模型
当下 , 端侧AI应用持续升温 。 然而 , 模型能力再强 , 如果无法在端侧设备上稳定、流畅运行 , 一切都是空谈 。
不是模型尺寸小 , 就叫端侧模型 。 评判端侧模型的关键指标是:在手机、平板、电脑、车机、机器人等终端设备上 , 是否能稳定、丝滑地运行 。
在技术研究上的难点 , 端侧模型不亚于基础大模型 , 落地上更是同时受限于算力、功耗、速度、网速要求等因素 。
许多团队屡屡碰壁 , 无法从技术上解决「发烫、宕机、极度耗电」等问题 。
面壁则一直以追求「同等性能我最小 , 同等参数我最强」 , 最终带来更快速度、更低成本、丝滑体验的端侧模型为目标 。
不断提升模型「能力密度」的同时 , 面壁小钢炮MiniCPM也一直致力于追求极致「能效比」:
通过更低的显存占用、更快的响应速度 , 确保在提供SOTA级多模态表现的同时 , 带来最佳的推理效率和最低的推理开销 。
例如 , 在覆盖短、中、长三种类型的视频理解评测集Video-MME上 , MiniCPM-V 4.5时间开销(未计算模型抽帧时间)仅为同级模型的1/10 。
这一成绩 , 便是得益于模型推理时采用的高密度视频压缩技术 。
三大技术创新
作为多模态模型的新旗舰 , MiniCPM-V 4.5之所以具备高刷视频理解能力、并取得单图、OCR、长视频理解的SOTA , 主要得益于在模型结构、训练范式等领域的创新 。
全新模型结构:3D-Resampler高密度视频压缩
当前 , 制约多模态模型视频理解能力的最核心挑战是性能和效率的Trade-off:
一方面 , 只有更多视频帧 , 模型才能获取更加精细的信息以提高理解上限;
另一方面 , 模型融入太多视频帧会造成显存、推理速度等开销爆炸 。
由于局部片段的不同视频之间存在着信息冗余性 , 即大部分视觉信息不变 , 仅有少部分信息发生变化 , 存在着很大的信息压缩空间 。
因此 , MiniCPM-V 4.5将模型结构从2D-Resampler拓展为3D-Resampler , 进行三维视频片段的高密度压缩 。
具体而言 , 视频会按照每N个视频帧一组进行分组(分组尺寸最大为6) , 然后3D-Resampler会对每个视频组进行压缩编码 , 得到 64 个视觉token(与编码单图视觉token数量相同) 。
最终实现在推理开销不变的情况下 , 实现更高频率抽帧 , 实现了模型高刷视频理解能力 。
得益于Resampler机制的灵活性 , 在推理阶段还可以灵活调整视频分组尺寸 , 同时支持单图、多图、视频的统一编码(即单图编码视为3D视频编码的2D特例) , 方便知识和能力迁移 。
多页文档图片:统一OCR和知识推理学习
文档中蕴含丰富高质量的知识 。
多模态大模型有两大重要话题:
1. 对文字的识别解析 , 受限于图像样例难度;
2. 从文档中学习知识 , 受限于解析准确性 。
这割裂了两种学习范式 。
提升OCR能力 , 往往需要补充更丰富且有难度的数据 。 为了提升数据的难度和多样性 , 常见的做法是数据增广 。 例如 , 对图像中文字加高斯噪音 。 但是增广过大会让文字不可读 , 反而会导致模型幻觉 。
在文档知识学习方面 , 大部分工作将文档解析成图文交替数据进行学习 , 严重受到文档解析工具错误的影响 。
通过连续控制图像中「文字信息可见度」 , MiniCPM-V 4.5可在OCR和知识学习两种模式之间无缝切换 , 首次实现了OCR和知识学习这两种学习范式的有效融合 , 且不会受到过度增广和解析错误的影响 。
具体如下:
· 首先提取出文档中的文字框;
· 然后对文字框内区域进行不同程度的噪音增广 。
文字框通常非常准确 , 大部分解析错误来源于排版、阅读顺序、低信息量图文噪音错误 。 重点在于噪音增广:
· 当施加噪音较小 , 文字处于尚可辨别范围内时 , 模型会进行OCR学习识别文字;
· 当施加噪音较大 , 文字已经无法辨认时 , 模型会自动进入知识学习 , 根据文档的多模态上下文还原文字;
· 当噪音介于两者之间时 , 模型会进行混合能力的学习 。
基于上述技术 , MiniCPM-V 4.5低成本实现了领先的OCR和多模态知识能力 。
通用域混合推理强化学习
深度思考推理能力显著拓展了多模态大模型的推理能力边界 , 但也往往伴随着过高的推理延迟 。
通过同时支持常规模式和深度思考模式 , MiniCPM-V 4.5实现了性能与响应速度的有效平衡:
· 在绝大部分的场景下 , 常规模式提供出色的多模态理解能力;
· 而深度思考模式则专注于应对复杂与复合型推理任务 。
为了让模型在两种模式下都具备优秀的多模态性能 , MiniCPM-V 4.5借助RLPR技术 , 从通用域多模态推理数据上获得高质量的奖励信号 。 而且面壁还提出了混合推理的强化学习RL训练方案 , 同时提升模型在常规模式和深度思考模式下的性能表现 。
通过在RL训练中同时激活常规和深度思考模式 , 模型在两种模式下的性能都得以持续提升 。 最终 , 通过轻量化的RLAIF-V训练阶段 , 模型既保持了推理能力又显著降低了幻觉 。
从行业第一个「高刷视频理解」模型 , 到OCR和知识学习的第一次有效结合 , 再到可控混合推理等 , MiniCPM-V 4.5的意义远不止一次模型的升级 , 更是开源端侧多模态AI的一场革命 。
参考连接:
https://github.com/OpenBMB/MiniCPM-o
https://huggingface.co/openbmb/MiniCPM-V-4_5
https://www.modelscope.cn/models/OpenBMB/MiniCPM-V-4_5
推荐阅读














- 华为云突发重大重组,盘古大模型相关部门被裁撤,或波及上千人
- 字节大模型关键人物被曝离职!
- 全球开源大模型,前十五名全是中国的
- 刚刚,马斯克开源Grok 2.5:中国公司才是xAI最大对手
- 北京大学打造TransMLA:让大模型推理速度飞跃10倍的神奇转换器
- 究竟会花落谁家?DeepSeek最新大模型瞄准了下一代国产AI芯片
- 谷歌技术报告披露大模型能耗:响应一次相当于微波炉叮一秒
- 刚刚,字节开源Seed-OSS-36B模型,512k上下文
- 智谱AutoGLM升级:给每个手机都装上通用 Agent
- 刚刚,企业微信甩出AI工作流“全家桶”!搜索、汇报、表格,一网打尽