
文章图片

文章图片

文章图片
文章图片
文章图片

文章图片
英伟达最快最先进的AI GPU: Blackwell Ultra GB300 , 号称AI 领域的奇迹芯片 , 日前 , 英伟达发布了一篇深度解析文章 , 详细介绍了其最新最强的 AI 芯片 ——GB300 Blackwell Ultra 。 这款芯片已全面投产 , 并已向核心客户交付 。 作为 Blackwell 解决方案的延伸产品 , GB300 在性能和功能上实现了重大升级 。 性能超 GB200 50% 并配备 288GB 内存 。
如同英伟达 Super 系列是原版 RTX 游戏显卡的增强版 , Ultra 系列则是其 AI 芯片的进阶版本 。 尽管此前的 Hopper 和 Volta 等产品线未明确推出 Ultra 型号 , 但从技术层面看也存在类似的增强版本 。 值得注意的是 , Ultra 芯片虽在硬件层面更具优势 , 但软件更新与优化同样能为非 Ultra 芯片带来显著性能提升 。
那么 , Blackwell Ultra GB300 究竟有何特别?如前所述 , 它采用两颗整片晶圆尺寸的芯片(Reticle-sized Dies) , 通过英伟达 NV-HBI 高带宽接口连接 , 在逻辑上呈现为单颗 GPU 。 该 GPU 基于台积电 4NP 工艺(专为英伟达优化的 5nm 制程)打造 , 集成了 2080 亿个晶体管 。 NV-HBI 接口为两颗 GPU 芯片提供 10TB/s 的带宽 , 同时确保其作为单一芯片协同工作 。
英伟达 Blackwell Ultra GB300 GPU 集成了 160 个流式多处理器(SM) , 每个 SM 包含 128 个 CUDA 核心、4 个支持 FP8/FP6/NVFP4 精度计算的第五代张量核心、256KB 张量内存(TMEM)及特殊函数单元(SFU) 。 整体规格达到 20480 个 CUDA 核心、640 个张量核心及 40MB TMEM 。
第五代张量核心是实现 AI 计算的核心引擎 , 英伟达在每代 GPU 的张量核心技术上均有重大创新:
·Volta 架构:8 线程矩阵乘法累加单元(MMA) , 支持 FP16 训练并搭配 FP32 累加计算
·Ampere 架构:全 warp 范围 MMA 单元 , 引入 BF16 和 TensorFloat-32 格式
·Hopper 架构:跨 128 线程的 warp 组 MMA 单元 , 集成支持 FP8 的 Transformer 引擎
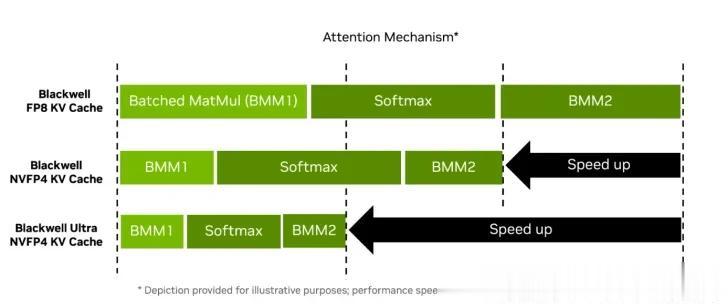
·Blackwell 架构:第二代 Transformer 引擎 , 支持 FP8/FP6/NVFP4 计算及 TMEM 存储
Blackwell Ultra 还实现了内存规格的重大升级:搭载 288GB HBM3e 显存 , 较前代 Blackwell GB200 的最高 192GB 提升显著 。 这一升级使其能够支持万亿级参数规模的 AI 模型 。 内存采用 8 堆叠设计 , 配备 16 个 512 位控制器(总带宽 8192 位) , 单 GPU 显存带宽达 8TB/s , 具体优势包括:
·完整模型驻留:无需内存卸载即可运行 3000 亿 + 参数模型
·扩展上下文长度:为 Transformer 模型提供更大 KV 缓存容量
·提升计算效率:针对多样化工作负载优化计算 - 内存比率
Blackwell 系列的互联技术包括 NVLINK 交换机、NVLINK-C2C 连接 , 以及用于主机 GPU 连接的 PCIe Gen6 x16 接口 。 以下是 NVLINK 5 及主机端连接的关键特性:
·单 GPU 双向带宽:1.8TB/s(18 条链路 ×100GB/s)
·性能扩展:较 Hopper GPU 的 NVLink 4 提升 2 倍
·最大拓扑规模:支持 576 颗 GPU 构建无阻塞计算架构
·机架级集成:72 颗 GPU 的 NVL72 配置 , 总带宽达 130TB/s
·PCIe 接口:Gen6×16 通道(双向 256GB/s)
·NVLink-C2C:支持 Grace CPU-GPU 内存一致性通信(900GB/s)
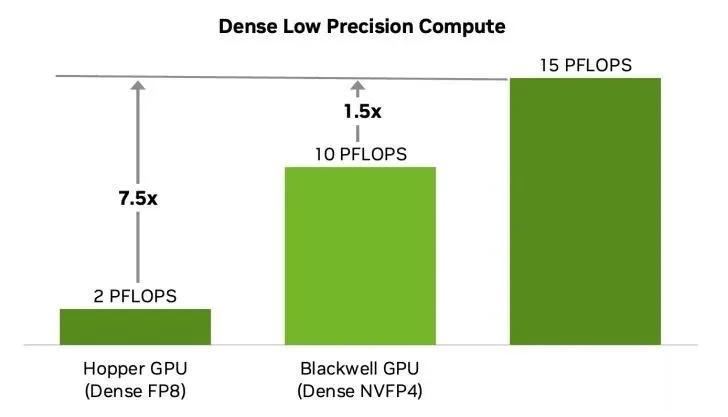
得益于全新 NVFP4 标准 , 英伟达 Blackwell Ultra GB300 平台的密集低精度计算输出提升 50% , 同时保持接近 FP8 的精度水平(差异通常小于 1%) 。 与 FP8 相比 , NVFP4 还能将内存占用减少 1.8 倍 , 较 FP16 减少 3.5 倍 。
Blackwell Ultra 还搭载了先进的调度管理与企业级安全特性:
·增强型 GigaThread 引擎:新一代工作调度器 , 优化上下文切换性能并实现 160 个 SM 间的工作负载智能分配
·多实例 GPU(MIG):支持将 GPU 划分为不同规格的 MIG 实例(如 2 个 140GB 实例、4 个 70GB 实例或 7 个 34GB 实例) , 实现安全多租户环境下的性能隔离
·机密计算与安全 AI:为敏感 AI 模型和数据提供硬件级可信执行环境(TEE) , 首次在 Blackwell 架构中集成 TEE-I/O 功能 , 并通过 NVLink 在线加密实现接近未加密模式的吞吐量
·高级远程证明服务(RAS)引擎:基于 AI 的可靠性监控系统 , 实时监测数千项参数以预测故障、优化维护计划 , 最大化大规模部署的系统可用性
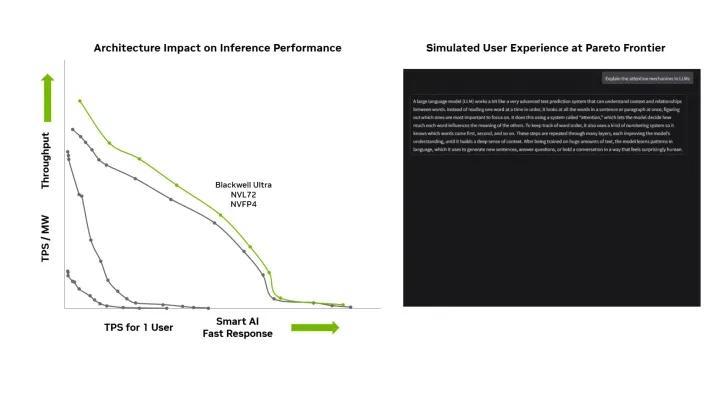
性能效率方面 , Blackwell Ultra GB300 的每兆瓦吞吐量(TPS/MW)较 Blackwell GB200 进一步提升(具体数据见下图) 。
【深度解析最快AI芯片:性能怪兽、AI奇迹芯片!】种种创新表明 , 英伟达凭借 Blackwell 及 Blackwell Ultra 等工程杰作稳居 AI 领域之巅 。 其深度软件支持与持续优化是核心竞争力 , 而年度硬件迭代节奏与不断加码的研发投入 , 将确保其在未来数年内持续引领行业 。
推荐阅读











- 性能、AI和影像深度融合:骁龙8 Elite在安卓阵营处于什么地位?
- 人工智能深度融入教育领域 打造人机协同新生态
- 从GPT-2到gpt-oss,深度详解OpenAI开放模型的进化之路
- 从图书馆到宿舍:大一新生笔记本的真实使用场景解析
- 小米玄戒O2最快明年二季度推出 将采用最新Arm公版架构
- 最快10月见!博主预测华为Mate80和X7售价,最高上调千元
- ChatGPT负责人深度复盘:我们做错了什么?
- 罗永浩播客节目首秀,李想深度回应理想汽车“被黑”幕后真相
- 重拾有线信仰:lifeme魅蓝「墨弦」高保真圈铁HiFi耳机深度体验
- 传英伟达将自研HBM Base Die:3nm制程,最快2027年试产