
文章图片
文章图片

文章图片
文章图片
论文第一作者 Han Meng 是新加坡国立大学博士生 , 从事心理学构建的计算方法研究 。 通讯作者 Yi-Chieh Lee 是新加坡国立大学助理教授 , 在对话式人工智能、人机交互和心理健康技术领域开展研究工作 。 共同作者 Renwen Zhang 是南洋理工大学助理教授 , 专注于计算传播学研究 , 为本研究提供了传播学视角 。 Jungup Lee 是新加坡国立大学副教授 , 在心理健康领域有深入研究 , 为本研究提供了重要的领域知识支撑 。
心理健康问题影响着全球数亿人的生活 , 然而患者往往面临着双重负担:不仅要承受疾病本身的痛苦 , 还要忍受来自社会的偏见和歧视 。 世界卫生组织数据显示 , 全球有相当比例的心理健康患者因为恐惧社会歧视而延迟或拒绝治疗 。
这种「污名化」现象如同隐形的障碍 , 不仅阻碍了患者的康复之路 , 更成为了一个重要的社会问题 。 患者们在承受病痛的同时 , 还要面对来自不同社会环境中的偏见 。 更为复杂的是 , 这种污名化往往以微妙、隐蔽的形式存在于日常对话中 , 即使是先进的人工智能系统也难以有效识别 。
尽管自然语言处理领域在仇恨言论、攻击性语言检测方面已有不少研究 , 但专门针对心理健康污名的计算资源却相对稀缺 。 现有数据集主要来源于社交媒体或合成数据 , 缺乏真实对话场景中的深层心理构建 , 且往往忽视了社会文化背景的重要性 。
新加坡国立大学 AI4SG 实验室联合多学科专家团队 , 构建了首个基于专家标注的心理健康污名访谈语料库 MHStigmaInterview , 希望为这一重要社会问题提供技术支持 。 该研究获得 ACL 2025 Oral 论文及高级领域主席奖(全会仅 47 篇获此荣誉)认可 。
论文标题:What is Stigma Attributed to? A Theory-Grounded Expert-Annotated Interview Corpus for Demystifying Mental-Health Stigma 论文链接:https://aclanthology.org/2025.acl-long.272.pdf 数据集链接:https://github.com/HanMeng2004/Mental-Health-Stigma-Interview-Corpus
研究团队
该研究由新加坡国立大学 AI4SG 实验室主导 , 汇聚了人机交互、计算社会科学、人工智能伦理等多个领域的研究者 。 AI4SG 实验室专注于人机交互、计算社会科学、人机协作以及社会公益人工智能等交叉研究领域 。
研究团队与心理健康领域专家密切合作 , 为 AI 和 NLP 研究引入了跨学科视角 , 为计算科学与社会科学的深度融合提供了一个探索案例 。
理论驱动的框架设计
与传统依赖社交媒体数据的方法不同 , MHStigmaInterview 建立在心理学理论基础上 。 研究团队采用了归因模型 , 将心理健康污名分解为七个核心维度:
认知层面:
责任归因: 认为患者应为自己的病情负责
情感层面:
愤怒: 对患者感到不满 恐惧: 认为患者危险、不可预测 怜悯: 缺乏真正的同情心
行为层面:
拒绝帮助: 不愿意提供支持 强制隔离: 主张强制住院治疗 社交距离: 倾向于回避与患者接触
这种理论驱动的标注体系 , 为后续的计算模型提供了相对明确的学习目标 。
基于聊天机器人的数据收集
为了获得更自然的对话样本 , 研究团队设计了聊天机器人访谈系统 。 该系统通过三个阶段引导参与者:
破冰阶段: 聊天机器人(命名为 Nova)首先与参与者讨论轻松话题 , 如兴趣爱好、最近看过的电影等 , 建立基本的交流氛围 。
情境植入: 系统呈现一个关于虚构角色「Avery」的抑郁症患者故事 , 描述其在工作、学习、社交中面临的挑战 , 避免使用专业术语以减少社会期望偏见 。
深度访谈: 基于七个核心归因维度设计访谈问题 , 如:
「你认为 Avery 目前的状况主要是他们自己行为的结果吗?」 「如果你要为家里选择租户 , 你会放心把房子租给像 Avery 这样的人吗?」 「如果你是 Avery 的邻居 , 你会考虑让他们离开社区并接受住院治疗吗?」
系统会根据参与者回答的详细程度自动调整后续提问策略 , 以获得充分的信息 。
数据集基本情况
经过严格的伦理审查和数据筛选 , 最终语料库包含:
4141 个访谈片段 684 名参与者 , 涵盖不同年龄、性别、种族、教育背景 平均 2.11 轮对话 , 总字符数超过 17 万 专家标注: 两名训练有素的标注员独立标注 , Cohen's kappa = 0.71
数据分析显示:
53.9% 的回答没有表现出污名化态度 责任归因(9.51%)和社交距离(9.15%)是最常见的污名类型 恐惧(8.86%)和愤怒(7.20%)紧随其后 相比传统仇恨言论数据集 , 该语料库中的污名化表达更加隐蔽、微妙
AI 模型的表现
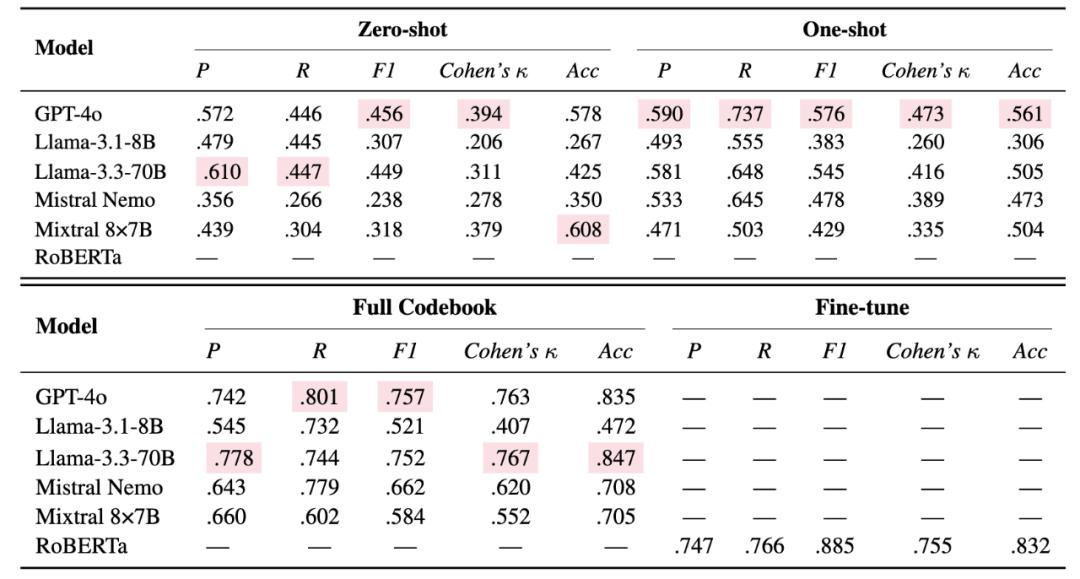
【AI4SG团队发布首个心理健康污名语料库,破解隐性偏见识别难题】研究团队在该语料库上测试了当前主流的大语言模型 , 包括 GPT-4o、LLaMA-3 系列、Mistral 等 。
性能表现:
GPT-4o 在零样本设置下 F1 分数为 0.456 提供详细标注指南后 , 性能提升至 0.757 模型普遍存在高召回率、低精确率的问题
隐性污名表达的深入分析
通过对 137 个错误分类案例的分析 , 研究团队发现了一些值得关注的模式 。 这些隐性污名化表达在日常对话中较为常见 , 但往往难以被识别 。
语言层面的表达特点:
距离化表达是一种常见的策略 , 说话者使用第三人称视角来表达观点 , 比如「邻居们可能很难理解 Avery 的行为」 。 这种表达方式表面上显得客观 , 但往往暗含着某种判断 。
术语滥用现象也比较普遍 , 一些人在缺乏专业背景的情况下 , 不恰当地使用心理学术语来描述患者 , 比如随意使用「偏执」等词汇 。 这种使用方式往往带有负面含义 。
强制性措辞在建议中频繁出现 , 诸如「绝对需要」、「必须接受」等表达 , 在一定程度上忽视了患者的自主选择权 。
语义层面的深层模式:
差别化支持表现为对患者的过度小心 , 比如「我需要在与他们交流时更加谨慎」 。 虽然表面上显得体贴 , 但实际上可能强化了患者的「特殊性」标签 。
家长制态度体现在一些回应中 , 说话者往往以指导者的姿态出现 , 认为自己有资格「教导」患者如何生活 。 这种态度在一定程度上忽视了患者作为独立个体的尊严 。
轻视化倾向则通过淡化心理健康问题的复杂性来体现 , 一些人习惯性地将心理健康问题简化为态度问题 , 认为患者「想开一点」就能解决 。
这些发现揭示了现代社会中污名化表达的复杂性和隐蔽性 , 也说明了开发更精准识别系统的必要性 。
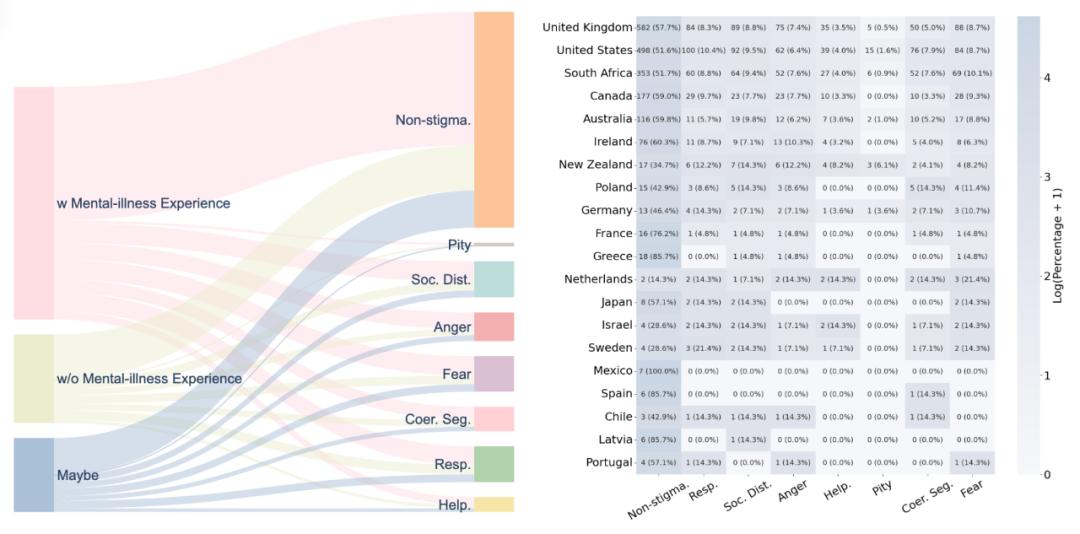
社会文化因素分析
语料库记录了参与者的社会文化背景 , 初步分析显示了一些有趣的模式:
性别差异: 女性参与者在某些维度上表现出相对较少的污名化倾向 年龄影响: 不同年龄群体对心理健康的态度存在差异 文化背景: 来自不同国家的参与者表现出不同的模式 个人经历: 有心理健康问题接触史的参与者更倾向于表现出非污名化态度
这些发现为理解污名化的社会根源提供了基本初步线索 。
应用前景与未来方向
该语料库为多个研究方向提供了资源 。
技术应用:
开发更精准的污名化表达识别系统 为内容审核提供参考工具 支持心理健康相关 AI 应用的开发
研究拓展:
个性化的反污名干预策略研究 跨文化污名模式比较 不同干预方法的效果评估
社会应用:
心理健康教育项目设计 医疗从业者培训支持 公共政策制定参考
MHStigmaInterview 语料库的发布为心理健康污名的计算研究提供了一个新的起点 。 虽然这是初步的探索 , 但它展示了技术在解决社会问题方面的潜力 。 通过持续的跨学科合作和技术改进 , 作者希望能够为构建更加包容的社会环境贡献一份力量 。
这项工作指出 , 在追求技术进步的同时 , 关注技术的社会影响和人文关怀同样重要 。 只有将技术发展与社会需求紧密结合 , 才能真正实现技术向善的目标 。
参考资料:
https://aclanthology.org/2025.acl-long.272.pdf
https://github.com/HanMeng2004/Mental-Health-Stigma-Interview-Corpus
推荐阅读










- 仅1869元!天玑9400+配8000大电池新机,刚发布就问鼎第一!
- iQOO Z10 Turbo+发布!性能续航双王炸,超分超帧畅玩!
- 苹果 iOS 26 Beta 5 全新变化汇总,正式版预计将在这天发布!
- 清华大学团队开发神奇对话评分器:让AI对话质量评判更准确高效
- 1869元,刚发布的这8000mAh新机,真的太猛了
- Deep Cogito发布四款开源混合推理大语言模型
- 曝百度最快8月底发布新版推理模型 部分能力将超越OpenAI o3满血版
- 全新360安全云重磅发布:AI智能体驱动「安全即服务」新未来
- 华为Mate 80将在10月发布 最强鸿蒙手机
- 华为Mate XTs硬刚iPhone17:同日发布,谁会更胜一筹?