文章图片
文章图片

文章图片
文章图片

文章图片
机器之心报道
编辑:冷猫
一觉起来世界已经进化成这样了?
每个人都能懂点魔法 , 能够随意穿梭在各个平行时空和幻想世界里 。
读者朋友们看到这说不定撇撇嘴 , 「这不就是 AI 视频吗?」
但如果加上两个关键词 , 这将成为 AI 视频生成领域革命性的突破!
就在昨天 , Decart 发布了世界上首个「实时的」「无时长限制的」并且支持「任意视频流」的扩散视频模型 MirageLSD!
输入任何视频流 , 无论是相机或视频聊天、电脑屏幕还是游戏 , MirageLSD 都能在 40 毫秒延迟以内将其转化为你想要的任何世界 。
这一切都看上去不可思议 , AI 视频已经能够实现和滤镜一样的应用方式 , 实时智能调整画面风格和画面内容 , 并且能够通过文本提示任意地进行控制 。
实时视频魔法
解锁全新应用可能
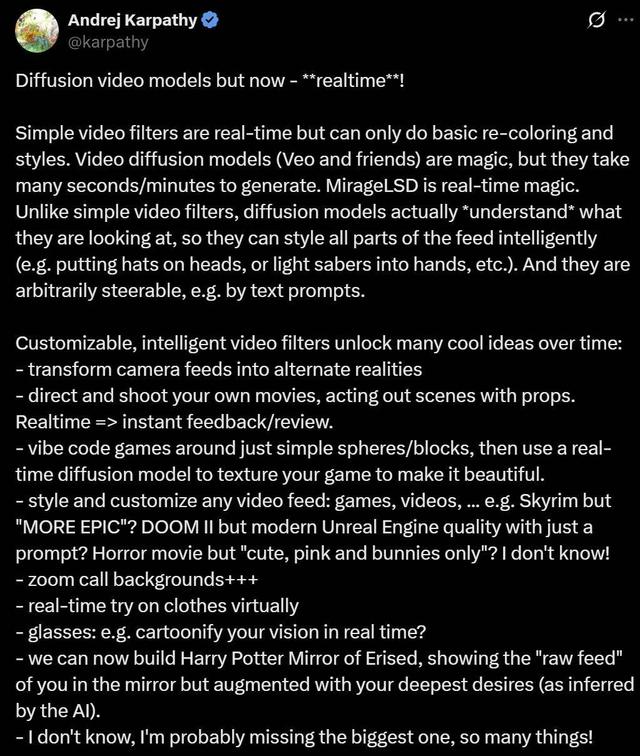
前特斯拉 AI 总监 , OpenAI 的创始团队成员 Andrej Karpathy 为此技术展开了广泛的想象:
- 将摄像头画面变为 “另一个世界” 。
- 自导自演实时电影:拿起道具、演绎场景 , AI 负责实时布景和风格化 , 秒看回放 , 边演边剪 。
- 游戏开发轻松起步:用简单的球体 / 方块编码游戏机制 , 再用实时扩散模型为游戏生成精美贴图 。
- 任意视频流的风格迁移:例如:只需一句提示词就能让《上古卷轴》看起来 “更史诗” , 让《毁灭战士 2》拥有现代虚幻引擎画质 。
- 视频会议背景和实时虚拟试衣 。
- AR 眼镜升级:实时将现实世界卡通化 。
- 哈利波特的「厄里斯魔镜」:现实中看似普通的镜子 , 实际上会显示出 AI 根据你 “深层欲望” 生成的理想自己或世界 。
【世界首个「实时、无限」扩散视频生成模型,Karpathy投资站台】也许这些都只是开始 , 真正的 “杀手级应用” 还没被发现 —— 这个领域值得无限想象!
这一切让我想起了「刀剑神域」 , 似乎覆盖现实世界的幻想画面真的要实现了?
Decart 也展示了一些构想的演示 , 充分满足了各种可能:
比如在沙漠里滑雪?
比如可以花上 30 分钟写个游戏代码 , 然后让 Mirage 处理图形?
Decart 推文中笑称 , 使用 Mirage「从提示词制作 GTA VII , 比 GTA VI 发售还快 。 」
目前 Mirage 已正式上线 , 与其观看屏幕上的魔法 , 不如亲手创造魔法 。
Decart 将持续发布模型升级和新功能 , 包括面部一致性、语音控制和精确物体操控等 。 与此同时 , 平台还将上线一系列新特性 —— 如流媒体支持(以任意角色进行直播)、游戏集成、视频通话等功能 。
- 体验链接:https://mirage.decart.ai/
MirageLSD技术原理
MirageLSD 主要在视频生成的时长和延迟两大角度产生了突破 , 基于定制的模型 —— 实时流扩散(Live Stream Diffusion , LSD) , 该模型能够逐帧生成并保持时间连贯性 。
在视频时长方面 , 先前的视频模型在生成 20-30 秒后就会因错误累积而严重降低质量 。
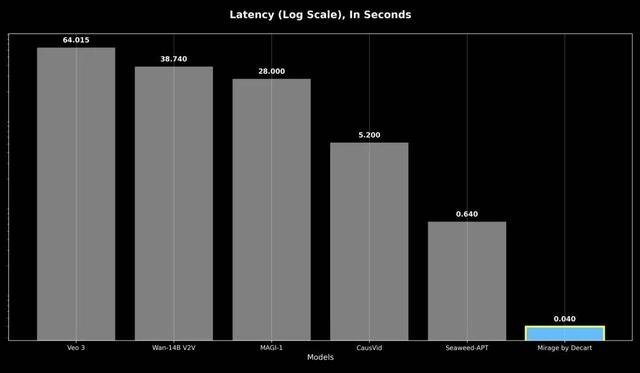
在生成延时方面 , 它们往往需要几分钟的处理时间才能输出几秒钟的视频 。 即使是今天最接近实时速度的系统 , 通常也是分块生成视频 , 从而引入不可避免的延迟 , 完全无法实现交互应用 。
无限长视频生成
MirageLSD 是第一个能够生成无限长视频的视频生成模型 。
由于模型的自回归特性 , 会导致误差逐步累积 , 从而限制输出的长度 。
为了实现无限自回归生成:
- MirageLSD 基于 Diffusion Forcing 技术 , 实现逐帧去噪;
- 我们引入历史增强方法 , 在训练中对输入历史帧进行扰动 , 使模型学会预判并纠正输入中的伪影 , 从而增强其对自回归生成中常见偏移的鲁棒性;
零延时视频生成
响应性是指最坏情况下的响应延迟 , 即使是之前的自回归模型响应速度也比 MirageLSD 慢 16 倍以上 , 导致实时交互无法实现 。
实时生成要求每帧的生成时间控制在 40 毫秒以内 , 以避免被人眼察觉 。 我们通过以下方式实现这一目标:
- 设计定制的 CUDA mega kernels , 以最小化开销并最大化吞吐;
- 基于 shortcut distillation 和模型剪枝技术 , 减少每帧所需的计算量;
- 优化模型架构 , 使其与 GPU 硬件高度对齐 , 实现效率最大化 。
扩散模型与 LSD
扩散模型通过一系列逐步去噪操作 , 将随机噪声逐渐还原为图像或视频 。 在视频生成中 , 这通常意味着一次性生成固定长度的视频片段 , 这有助于保持时间一致性 , 但会带来延迟 。 一些系统尝试通过所谓的 “自回归生成” 方式 , 逐段顺序生成帧片段 , 以提高灵活性 。 然而 , 这种方式仍需在每一段帧生成完毕后才能响应新的输入 , 限制了交互性和实时应用的能力 。
LSD 采用了不同的方法 。 它一次生成一帧 , 使用因果性的自回归结构 , 每一帧都依赖于此前生成的帧以及用户提示 。 这种方式支持即时反馈、零延迟交互 , 并且可以持续生成视频 , 无需预先设定终点 。
在每一个时间步 , 模型会接收一组过去生成的帧、当前输入帧以及用户定义的提示词 , 然后预测下一帧输出 , 该帧会立即作为输入传递到下一轮生成中 。
这种因果反馈机制使 LSD 能够保持时间上的一致性 , 持续适应画面中的动作与内容变化 , 并在实时遵循用户提示的同时 , 生成无限长度的视频序列 。
此外 , 它还使 LSD 能够对输入作出即时响应 —— 无论是文本提示还是视频内容的变化 —— 实现真正的零延迟 。 这正是实时编辑与转换成为可能的关键 。
技术缺陷与改进方向
首先 , 当前系统依赖于有限的历史帧窗口 。 引入更长期的记忆机制有望提升长序列中的连贯性 , 从而在角色身份、场景布局和长期动作等方面实现更一致的表现 。
此外 , 尽管 MirageLSD 支持基于文本的风格变换 , 但对于特定物体、空间区域或动作的精细控制仍较为有限 。 若能整合关键点或场景标注等结构化控制信号 , 将有助于在实时环境中实现更细粒度、用户可控的编辑操作 。
在语义一致性和几何稳定性方面 , 特别是在面对极端风格变换时 , 仍需进一步优化 。 MirageLSD 在极端风格变化下 , 可能会出现物体结构或布局被扭曲的情况 。
更多相关技术信息 , 请参阅 Decart 的技术介绍:
- 文章链接:https://about.decart.ai/publications/mirage
推荐阅读











- 华为果断放弃“高利润”,麒麟9020新机上市仅一个月,跌价1050元
- 小米终于妥协,16GB+1TB+7550mAh,发布不到三个月跌至2612元
- 这个行业成时代机会!雷军3天卖出近5万件,科技巨头250亿投资公司
- 微星推出多款全新的B850主板,传还有另外三个背插型号在准备当中
- 微信最新的一个隐藏新变化,又是非常实用!
- 美女产品经理离职!魅族22还没发布,小米16再过2个月就要来了
- 网络安全意识必修课:个人隐私保护,从 “我” 做起
- 12人小公司融资2亿!这个AI“外星人”凭啥让硅谷疯狂买单?
- 手机圈又来新人,iKKO带来一个新物种
- 我希望我的 AI,能将我带向世界