
文章图片

文章图片
文章图片

文章图片

文章图片

文章图片
文章图片

文章图片
文章图片

文章图片

机器之心报道
机器之心编辑部
昨天 , OpenAI 官宣了一个重磅消息:他们的一个推理模型在国际数学奥林匹克(IMO)竞赛中获得了金牌水平的表现 。
官宣该消息的 OpenAI 研究科学家 Alexander Wei 表示 , 在评估过程中 , 研究团队严格按照人类选手的比赛规则进行测试:模型需要在两个 4.5 小时的考试环节中 , 在没有任何工具或网络辅助的情况下 , 阅读官方题目并撰写自然语言证明 。
在评估中 , 该模型成功解决了 2025 年 IMO 六道题目中的五道 , 获得了 35 分(满分 42 分)的成绩 , 足以获得金牌 。 每道题目都由三位前 IMO 奖牌获得者独立评分 , 并在达成一致后确定最终分数 。
在该消息公布后 , 整个 AI 社区都为之振奋 。 Alexander Wei 还晒出了 OpenAI 新模型生成的证明过程 。
证明过程链接:https://github.com/aw31/openai-imo-2025-proofs/
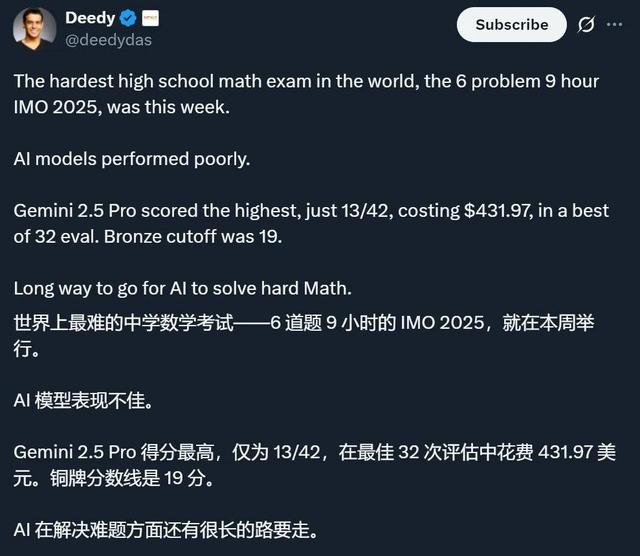
而且有趣的是 , 就在 Alexander Wei 发帖之前不久 , 各家 AI 模型刚被曝出在 IMO 中表现不佳 , 得分最高的 Gemini 2.5 Pro 得分仅为 13 分 , OpenAI 的 o3(high)则拿了 7 分 。 OpenAI 新模型成绩的官宣让这一事件出现了惊人的反转 。
不过 , 在这些消息发酵后不久 , 数学家陶哲轩站了出来 , 劝大家「谨慎看待」 。 他认为 , 如果没有严格控制、标准化的测试条件 , 我们就无法用一种有意义的方式来比较 AI 模型与人类 , 并表示自己「不会评论任何在竞赛前未公开其方法的自我报告的 AI 竞赛结果」 。 这引发了大家对于 AI 模型实际进展的思考 。
陶哲轩:谨慎看待各大 AI 模型的 IMO 成绩
陶哲轩在博客中写道:
人们很容易把当下 AI 的能力当成一个「一刀切」的单一指标:任务 X 要么在现有工具的能力之内 , 要么不在 。 实际上 , AI 的能力差距可以拉开好几个数量级 , 具体取决于给它什么资源、辅助方式 , 以及大家如何汇报自己的结果 。
我用一个比喻来说明这一点 。 就取刚结束的国际数学奥林匹克(IMO)竞赛做例子 。
标准赛制是:每个国家派 6 名高中生参赛 , 由一名领队(通常是职业数学家)带队 。 两天里 , 选手每天 4.5 小时用纸笔独立解答 3 道难题;考试期间选手之间、选手与领队之间不得交流 , 只能请监考员澄清题意 。 阅卷时领队为学生辩护 , 但并不直接参与做题 。 能拿到金牌(今年分数线 35/42 , 即 6 题里完美做出 5 题)被视为高中生极高的数学成就 。
但是 , 如果我们通过各种方式改变奥林匹克竞赛的形式 , 思考一下其难度会发生什么变化:
- 给学生几天时间来完成每道题目 , 而不是在四个半小时内完成三道题 。 (稍微延伸一下这个比喻 , 想象一个科幻场景:学生仍然只有四个半小时 , 但领队将他们置于某种昂贵且高耗能的时间加速机器中 , 在此期间学生们经历了数月甚至数年的时间 。 )
- 考试开始前 , 领队以一种学生认为更容易处理的形式重写题目 。
- 领队允许学生无限制地使用计算器、计算机代数系统、形式化证明助手、教科书 , 或使用互联网搜索 。
- 领队让六名队员组成的团队同时解决同一个问题 , 并就各自的部分进展和遇到的死胡同进行沟通 。
- 领队向学生提示可能有效的方法 , 并在某个学生花费太多时间在一个他们知道不太可能成功的方向上时进行干预 。
- 团队中的六名学生都提交解答 , 但领队只选择「最佳」解答提交给竞赛 , 而将其余的丢弃 。
- 如果团队中没有一个学生得出满意的解答 , 领队则完全不提交任何解答 , 并悄悄退出比赛 , 他们的参与记录也无从知晓 。
因此 , 在缺乏一种非参赛团队自选的、受控的测试方法论的情况下 , 人们应该警惕将不同 AI 模型在 IMO 这类竞赛中的表现 , 或将这些模型与人类参赛者的表现进行「同类比较」 。
与此相关的是 , 对于任何未在赛前披露其方法论的、自我报告的 AI 竞赛表现结果 , 我将不予置评 。
网友:能写几页纸的证明本身就值得关注
对于陶哲轩提出的质疑 , 网友展开了广泛讨论 。 首先需要指出 , 陶哲轩在帖子中提到的挑战 IMO 的 AI 模型可能不是特指 OpenAI 的模型 , 因此里面指出的一些问题对于 OpenAI 来说可能并不完全适用 。
比如 , 从 OpenAI 的声明来看 , 他们似乎没有使用工具调用 。
不过 , 有人反驳说 , 模型在训练期间就记住了整个互联网的语料 , 即使不调用工具 , 让他们和无法访问互联网的人类学生相比也不够公平 。
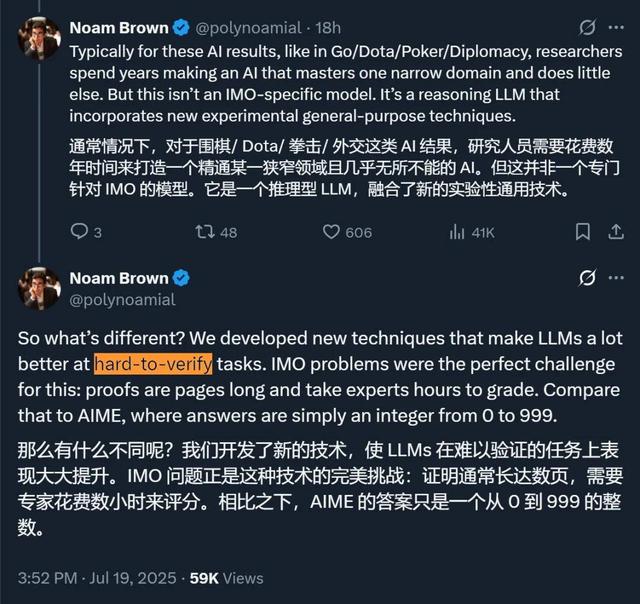
还有人指出 , 这些问题其实并不值得纠结 。 从 OpenAI 的这个模型中 , 我们应该看到的是:AI 已经能够在一个「难以验证」的领域进行超过一个小时的推理并给出正确答案了 。
所谓的「难以验证」 , 相对的是容易验证 , 比如像 AIME(美国数学竞赛体系中的高阶邀请赛)中的数学题 , 每题答案为 000-999 之间的整数 , 无需证明过程 , 仅填数字 。 对于这类问题 , 我们很容易用标准答案来训练模型 , 用强化学习等方法来教会模型解决这类问题 。 但对于长达多页的证明 , 我们一直缺乏明确的训练范式 。 这也是 OpenAI 的研究最令人好奇的地方 。
在关于该模型的讨论中 , OpenAI 推理研究主管 Noam Brown 也专门指出了这一点 , 而且明确表示他们「还有很大的空间来进一步提升测试时的计算能力和效率」 。
如果 OpenAI 真的掌握了让模型解决「难以验证」的问题的训练方法 , 他们是不是又往前走了一大步?
目前 , 这些问题尚无定论 。 OpenAI 的做法也非常神秘:他们提到最近会发布 GPT-5 , 但又明确指出这个拿到 IMO 金牌的模型不是 GPT-5 。 这个模型的面世可能还要等几个月 。
One more thing:领导神秘模型的 Alexander Wei 是谁?
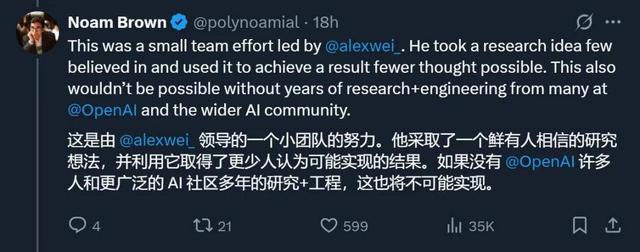
这个拿到 IMO 金牌的推理模型来自 Alexander Wei 领导的一个小组 。 Noam Brown 提到 , 在新模型中 , Alexander Wei 采取了一个鲜有人相信的想法 , 并利用它取得了极少人认为可能实现的结果 。
Alexander Wei 专注于 LLM 的推理能力提升 , 特别是在数学推理和自然语言证明生成方面 。 他还曾获得国际信息学奥林匹克(IOI)金牌 。
他于 2023 年获得加州大学伯克利分校的计算机科学博士学位 , 师从 Nika Haghtalab、Michael I. Jordan 及 Jacob Steinhardt 。 此前 , 他于 2020 年在哈佛大学完成了计算机科学的本硕学习 。 他的研究曾荣获 SODA 最佳学生论文奖和 INFORMS 拍卖与市场设计领域的 Rothkopf 奖 。
加入 OpenAI 之前 , Wei 博士曾先后在 Meta AI (FAIR)、Microsoft Research 及 D. E. Shaw 公司积累了丰富的研究与行业经验 。
在 Meta AI (FAIR) 期间 , 他参与研发了在策略游戏《外交》(Diplomacy) 中达到人类顶尖水平的 AI 系统 CICERO , 该成果发表于 2022 年的《Science》杂志 。
Alexander Wei 小组的工作给最近深陷挖脚危机的 OpenAI 注入了一针强心剂 , Noam Brown 似乎也有意借此向外界传递一个重要信号:OpenAI 依然是一个前沿技术实验室 , 其拥有的技术比其他实验室提前几个月 。 只有在这里工作 , 你才能在第一时间接触到这些东西 。 你同意他的看法吗?
参考链接:https://x.com/alexwei_/status/1946477754372985146
https://x.com/polynoamial/status/1946478252496695523
【先别急着给OpenAI加冕!陶哲轩:这种「金牌」,含金量取决于赛制】https://mathstodon.xyz/@tao/114881420636881657
推荐阅读












- 荣耀X70首发用了一天,开箱激活第一眼真给我唬住了
- 饿了么发布“明厨亮灶2.0” 搭档钉钉免费给商家安装硬件设备
- 三星自己不用的技术给了苹果?折叠屏iPhone要靠无折痕改写规则?
- 只给Pro用?iPhone 17 抗反光玻璃曝光,标准版用户看了想哭
- iQOONeo10Pro+,推荐给追求极致体验的重度玩家!
- NVIDIA、AMD,都要来给中国AI芯片上强度,降温了?
- 特朗普点头!AMD AI加速卡也可以卖给中国了
- 最新手机销量排名Top 10:iPhone占据前二,第三名给我看懵了
- 好消息!2024年,国产GPU自给率,已达到了30%了
- 半斤对八两,荣耀GT Pro和iQOO 13选哪款?我给你支招