
文章图片

文章图片
文章图片
文章图片

【导读】Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架 , 通过细粒度嵌入路由将语音与角色绑定 , 实现精准的音画同步 , 并支持动态背景生成 。 该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试 , 实验表明其在身份保真和音画同步上优于现有方法 。
近年来随着视频生成基础模型的涌现 , 音频驱动的说话人视频生成领域也取得了显著进展 。
但现有方法主要聚焦于单角色场景 , 现有可生成两个角色对话视频的方法仅能单独地生成两个分离的说话人视频 。
针对这一挑战 , 研究人员提出了首个专注同场景多角色说话视频生成的框架Bind-Your-Avatar
该模型基于扩散Transformer(MM-DiT) , 通过细粒度的嵌入路由机制将「谁在说」与「说什么」绑定在一起 , 从而实现对音频–角色对应关系的精确控制 。
论文地址:https://arxiv.org/abs/2506.19833 项目地址:https://yubo-shankui.github.io/bind-your-avatar作者同时构建了首个针对多角色对话视频生成的完整数据集(MTCC)和评测基准 , 提供了端到端的数据处理流程 。
大量实验表明 , Bind-Your-Avatar在多角色场景下生成效果优异 , 在人脸身份保真和音画同步等指标上均显著优于现有基线方法 。
Bind-Your-Avatar 方法概览Bind-Your-Avatar基于一个多模态文本到视频扩散Transformer(MM-DiT)搭建 , 模型输入包括:文本提示、多路语音音频流、多个角色的人脸参考图像 , 以及(可?。 ┮恢∮糜诨嬷票尘暗膇npainting帧 。
文本、音频和人脸身份特征通过特征编码器提取 , 并由Embedding路由引导的交叉注意力(Cross-Attention)将人脸和音频信息选择性地注入到视觉Token中 , 从而实现音画同步性的关联 。
模型的训练分为三个阶段:第一阶段只生成带补全帧的静音角色运动视频(不使用音频) , 第二阶段加入单角色语音输入学习音频驱动的精细角色运动(通过LoRA轻量化微调) , 第三阶段引入多角色语音输入并联合训练Embedding路由(使用教师强制方法防止掩码退化) 。
细粒度Embedding路由引导的音频–角色驱动 【免剪辑直出,AI生成多角色同框对话视频,动态路由精准绑定音频】Embedding路由的作用输出是一个时空掩码矩阵M , 用于指示每个视觉Token对应哪个角色(或背景) , 从而将说话人与具体语音绑定 。
在训练时 , 研究人员设计了交叉熵损失
监督路由输出 , 并结合几何先验引入时空一致性损失和层一致性损失 , 增强掩码的准确性和平滑性 。
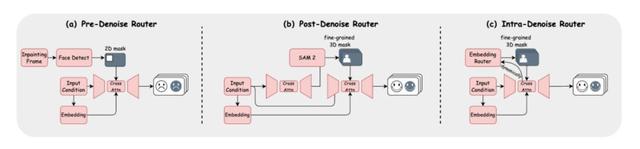
论文中探讨了三种路由实现方式:预去噪(Pre-Denoise , 用静态2D掩码)、后去噪(Post-Denoise , 两阶段生成后预测3D掩码)以及内置去噪(Intra-Denoise)路由 。
Intra-Denoise路由在扩散去噪过程中动态生成细粒度3D时空掩码 , 实现对各角色帧级独立控制 。 这种设计不仅提升了音频与对应角色口型的精度 , 还保持了角色身份的连贯性 。
为了得到高质量的3D-mask , 研究人员在路由的设计中提出了两个有效的方法 。 其中 , 掩码优化策略通过引入几何先验对掩码进行正则化 , 提高了角色与背景区域分割的准确度和时序一致性;此外 , 研究人员还提出了一种掩码细化流程 , 将初步预测的稀疏掩码进行平滑和时间一致性校正 , 进一步增强掩码质量 。
MTCC数据集为了支持多角色视频生成 , 研究人员构建了MTCC数据集(Multi-Talking-Characters-Conversations) , 该数据集包含200+小时的多角色对话视频 。
数据处理流程包括:
视频清洗(筛选分辨率、时长、帧率;确保视频中恰有两个清晰角色;姿态差异度过滤等)、音频分离与同步筛?。 ㄊ褂肁V-MossFormer和Sync-C指标确保音画一致)、语音与文本标注(应用Wav2Vec提取音频特征 , QWen2-VL生成描述)以及SAM2生成角色区域掩码作为监督信号 。
MTCC附带完整的开源处理代码 , 为社区提供了从原始视频到训练数据的端到端流水线 。
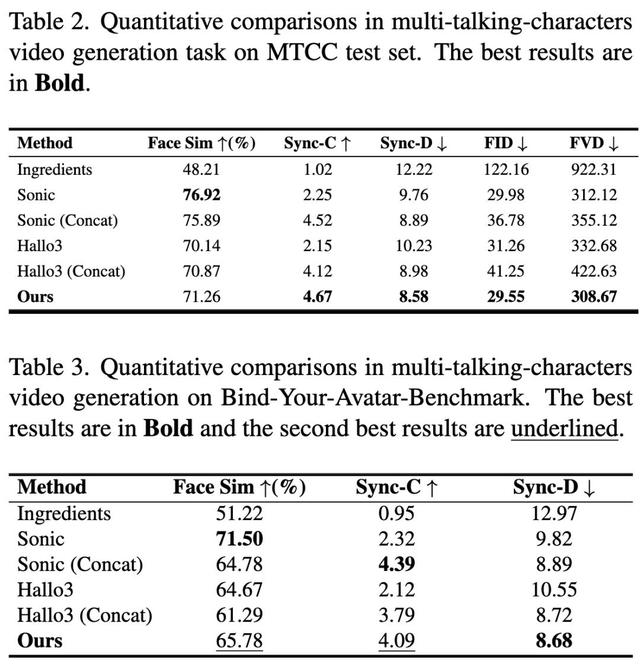
实验与分析 定量分析研究人员在MTCC测试集和全新基准集(Bind-Your-Avatar-Benchmark , 含40组双角色人脸和双流音频)上与多种基线方法进行了对比 , 包括最近的Sonic、Hallo3和Ingredients等 。 这些方法原本设计用于单角色或无背景场景 , 对本任务进行了适配 。
定量指标涵盖角色身份保持(Face Similarity)、音画同步(Sync-C、Sync-D)以及视觉质量(FID、FVD)等 。
结果表明 , Bind-Your-Avatar在人脸相似度和音画同步度指标上均显著优于各基线(同步指标尤其优异) , 而在FID/FVD等视觉质量指标上也保持竞争力 。
消融实验进一步验证:细粒度3D掩码比边界框或静态2D掩码能更好地应对角色运动和近距离互动 , 提升了动态场景下的生成质量 。
定性分析Bind-Your-Avatar能自然处理多角色的交叉说话场景 , 同时生成统一、动态的背景 , 无需后期拼接 。
例如 , Bind-Your-Avatar能生成两个角色同时讲述不同内容的对话视频 , 并保持每个角色的口型与对应语音高度同步 , 同时人物面部和表情逼真 。
结语Bind-Your-Avatar 首次提出了同场景多角色语音驱动视频生成任务 , 并提供了从算法到数据集的完整解决方案 。
其主要贡献包括:细粒度Embedding路由机制(实现「谁在说什么」的精确绑定)、动态3D-mask路由设计(逐帧控制各角色) , 以及MTCC数据集和对应的多角色生成基准 。
未来工作将聚焦于增强角色动作的真实感(如身体和手势动作)并优化模型实时性能 , 以适应更大规模和在线化的多角色视频生成需求 。
研究人员后续将开源数据集和代码 , 方便社区进一步研究 。
参考资料:
https://arxiv.org/abs/2506.19833
推荐阅读












- “京东取消外卖超时20分钟免单”冲上热搜
- 向QQ音乐看齐,腾讯视频开测广告免费模式
- 苹果2025高校优惠开启:Mac系列和iPad系列为主 最长享三个月免息分期
- 四款免费开源音乐播放软件推荐:畅享自由音乐之旅
- 狂背90%哈利波特,这玩意真成免费电子书库了?
- NASA与网飞达成合作,将免费直播火箭发射及国际空间站实景
- 昨夜,阿里版GPT-4o登场,一句话精准P图,免费可用
- 谷歌杀疯,百万token神器免费开源,Claude和Codex都顶不住了?
- 苹果拟调整App Store规则向欧盟示好 避免因反垄断再遭处罚
- 免费、开源!谷歌Gemini CLI彻底火了,平替Claude Code