
文章图片

文章图片
文章图片
文章图片
本项目为AI Geeks、澳洲人工智能研究所、利物浦大学、拉筹伯大学的联合工作 。
我们提出了 PresentAgent , 一个能够将长篇文档转化为带解说的演示视频、多模态智能体 。 现有方法大多局限于生成静态幻灯片或文本摘要 , 而我们的方案突破了这些限制 , 能够生成高度同步的视觉内容和语音解说 , 逼真模拟人类风格的演示 。
- 论文标题:PresentAgent: Multimodal Agent for Presentation Video Generation
- 论文地址:https://arxiv.org/abs/2507.04036
- 代码:https://github.com/AIGeeksGroup/PresentAgent
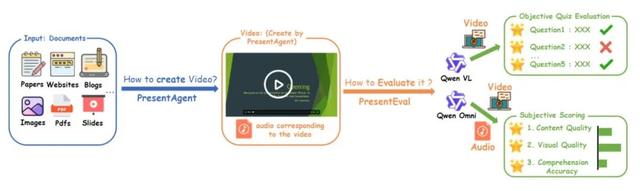
为了实现这一整合 , PresentAgent 采用了模块化流程 , 如图 1 所示 , 包括以下步骤:1. 系统性地对输入文档进行分段;2. 规划并渲染幻灯片风格的视觉?。 ?. 利用大型语言模型与文本转语音模型生成具有上下文的语音解说;4. 最终将音频与视觉内容精确对齐 , 无缝组合成完整视频 。
图 1 PresentAgent 概览 。该系统以文档(如网页)为输入 , 经过以下生成流程:(1)文档处理、(2)结构化幻灯片生成、(3)同步字幕创建 , 以及(4) 语音合成 。 最终输出为一个结合幻灯片和同步讲解的演示视频 。 图中紫色高亮部分表示生成过程中的关键中间输出 。
考虑到这种多模态输出的评估难度 , 我们引入了 PresentEval , 一个由视觉-语言模型驱动的统一评估框架 , 从以下三个关键维度全面打分:内容忠实度(Content Fidelity)、视觉清晰度(Visual Clarity)和观众理解度(Audience Comprehension) 。
评估采用基于提示的方式进行 。 我们在一个精心整理的包含 30 对「文档-演示」样本的数据集上进行了实验验证 , 结果表明 , PresentAgent 在所有评估指标上接近人类水平的表现 。
这些结果展示了可控多模态智能体在将静态文本材料转化为动态、有效、易获取的演示格式方面的巨大潜力 。
我们的主要贡献如下:
- 提出新任务: 首次提出「文档到演示视频生成」这一新任务 , 旨在从各类长文本自动生成结构化的幻灯片视频 , 并配有语音解说 。
- 设计 PresentAgent 系统: 提出一个模块化生成框架 , 涵盖文档解析、布局感知幻灯片构建、讲稿生成及音视同步 , 实现可控、可解释的视频生成过程 。
- 提出 PresentEval 评估框架: 构建一个由视觉语言模型驱动的多维度评估机制 , 从内容、视觉与理解等维度对视频进行提示式评分 。
- 构建高质量评测数据集: 我们制作了一个包含 30 对真实文档与对应演示视频的数据集 。 实验和消融研究显示 , PresentAgent 不仅接近人类表现 , 且显著优于现有方案 。
演示视频评估基准(Presentation Benchmark)
图 2 我们评估基准中的文档多样性
为了支持文档到演示视频生成的评估 , 我们构建了一个多领域、多文体的真实对照数据集——Doc2Present Benchmark , 其中每对数据都包含一个文档与一个配套的演示视频 。 不同于以往只关注摘要或幻灯片的基准 , 我们的数据包括:
- 商业报告
- 产品手册
- 政策简报
- 教程类文档等
每篇文档均配有人工制作的视频讲解 , 如图 2 所示 。
图 3 我们的评测方法框架概览
与 paper2poster 的方法类似 , 我们设计了一个测验式评估框架 , 即通过视觉语言模型仅根据生成视频(幻灯片+讲解)回答内容问题 , 以模拟观众的理解水平 , 同时我们还引入人工制作的视频作为参考标准 , 既用于评分校准 , 也作为性能上限对比 。
该评估框架由两部分组成:
- 客观测验评估: 通过选择题测量视频传递信息的准确性;
- 主观评分评估: 从内容质量、视觉/音频设计与理解清晰度等维度 , 对视频进行 1–5 分等级评分;这两类指标共同构成了对生成视频的全面质量评估体系 , 如图 3 所示 。
PresentAgent
图 4 PresentAgent 框架概览
本系统以多种类型的文档(例如论文、网页、PDF 等)为输入 , 遵循模块化的生成流程:
- 首先进行提纲生成;
- 检索出最适合的幻灯片模板;
- 然后借助视觉-语言模型生成幻灯片和解说文稿;
- 将解说文稿通过 TTS 转换为音频 , 并合成为完整的演示视频;
- 为了评估视频质量 , 我们设计了多个维度的提示语;
- 最后将提示输入基于视觉语言模型(VLM)的评分模块 , 输出各个维度的指标结果 。
为了将长文本文档转化为带口语化讲解的演示视频 , 我们设计了一个多阶段的生成框架 , 模拟人类准备幻灯片与演讲内容的流程 , 如图 4 所示 。 该方法分为四步:
- 语义分段;
- 结构化幻灯片生成;
- 口语化讲解生成;
- 可视与音频组合为同步视频 。
该模块化设计支持可控性、可解释性和多模态对齐 , 兼顾高质量生成与细粒度评估 。 下文将分别介绍各模块 。
实验
我们构建了一个包含 30 个长文档的测试集 , 每个文档配有人类手工制作的演示视频作为参考 。 这些文档涵盖教育、产品说明、科研综述与政策简报等主题 。
所有生成与人工视频均使用 PresentEval 框架进行评估 。 由于当前尚无模型可完整评估超 2 分钟的多模态视频 , 我们采用分段评估策略:
- 客观评估阶段: 使用 Qwen-VL-2.5-3B 回答固定的多项选择题 , 评估内容理解;
- 主观评分阶段: 提取视频与音频片段 , 使用 Qwen-Omni-7B 针对内容质量、视觉/听觉质量和理解难度分别打分 。
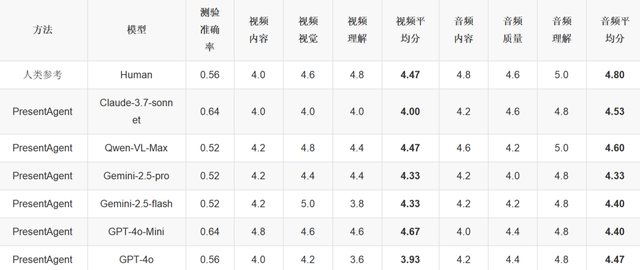
主实验结果
在测验准确率方面 , 大多数 PresentAgent 的变体与人工基准结果(0.56)相当甚至更优 。 其中 Claude-3.7-sonnet 取得了最高准确率 0.64 , 表明生成内容与源文档之间具有较强的一致性 。 其他模型如 Qwen-VL-Max 和 Gemini-2.5-flash 得分略低(0.52) , 表明在事实对齐方面仍有提升空间 。
在主观质量方面 , 由人类制作的演示仍在视频和音频整体评分上保持领先 。 然而 , 一些 PresentAgent 变体表现出有竞争力的性能 。 例如 , GPT-4o-Mini 在视频内容和视觉吸引力方面获得了最高分(均接近或达到 4.8) , 而 Claude-3.7-sonnet 则在音频质量方面表现最为平衡(均分为 4.53) 。
有趣的是 , Gemini-2.5-flash 在视觉质量上取得了最高得分(5.0) , 但在理解性方面较低 , 这反映了美观性与清晰度之间的权衡 。 这些结果突显了我们模块化生成流程的有效性 , 以及统一评估框架 PresentEval 在捕捉演示质量多个维度方面的实用价值 。
案例分析
图 5 PresentAgent 自动生成演示视频示例
【演讲生成黑科技,PresentAgent从文本到演讲视频】图 5 体现了一个完整的 PresentAgent 自动生成演示视频示例 , 其中一篇技术博客被转化为带解说的演示 。 系统识别出结构性片段(如引言、技术解释等) , 并为其生成了包含口语风格字幕和同步语音的幻灯片 , 涵盖了「并行化工作流」、「代理系统架构」等技术主题 , 展示了系统在保持技术准确性的同时 , 以清晰、对话式方式传达信息的能力 。
推荐阅读











- 客制化、三模、RGB、1万毫安,黑爵MK87 机械键盘要行业内卷了
- AI大神卡帕西投钱!全球首个直播生成模型发布,实时生成无时长限制
- 全球智能手机榜单更新:传音第5,小米第3,第一名成最大黑马
- 曜启新境!影驰「黑曜石」机箱正式发售!
- 免剪辑直出,AI生成多角色同框对话视频,动态路由精准绑定音频
- 黄仁勋着唐装亮相链博会,将首次公开发表中文演讲
- 一键实现PPT演讲自由,「解说音频+视频」同步生成,效果逼近真人
- 黄仁勋18年前旧照曝光!本人感慨:那时还是一头黑发 现在头发白了
- vivo手机诞生“新黑马”,首销打破销量纪录,国补后价格更加亲民
- ICML 2025 Oral!北大和腾讯优图破解AI生成图像检测泛化难题