
文章图片
文章图片
文章图片

文章图片
机器之心报道
编辑:笑寒
都在研究考生 , 考卷出问题了 。基准测试在评估人工智能系统的优势与局限性方面具有基础性作用 , 是引导科研与产业发展的关键工具 。
随着 AI 智能体从研究原型逐步走向关键任务的实际应用 , 研究人员和从业者开始构建用于评估 AI 智能体能力与局限性的基准测试 。
这和常规模型的评估方式产生了很大不同 。 由于智能体的任务通常需要一个真实场景 , 并且任务缺乏标准答案 , 针对 AI 智能体的基准测试在任务设计和评估方式上要远比传统 AI 基准测试要复杂 。
显然 , 现有的智能体基准测试并没有达到一个可靠的状态 。
举几个例子:
- 在被 OpenAI 等机构用于评估 AI 智能体网页交互能力的基准测试 WebArena 中 , 在某个路径时长计算任务中 , AI 智能体给出的答案是「45 + 8 分钟」 , 而正确答案应为「63 分钟」 , WebArena 竟将其判定为正确答案 。
- τ-bench 是一个评估 AI 智能体在真实世界环境中可靠性的基准测试 。 而其将一个「无操作」的智能体在航班任务中判有 38% 正确率 。 尽管该智能体对机票政策毫无理解 , 结果却错误地评估了其能力 。
此外 , 在目前常用的 10 个 AI 智能体基准测试中(如 SWE-bench、OSWorld、KernelBench 等) , 研究在其中 8 个基准中发现了严重的问题 , 有些情况下甚至会导致对 AI 智能体能力 100% 的误判 。
这些数据传达出一个明确的信息:
【什么都不做就能得分?智能体基准测试出现大问题】现有智能体基准测试存在大问题 。 若要准确理解 AI 智能体的真实能力 , 必须以更严谨的方式构建基准测试 。
在一个来自伊利诺伊大学香槟分校、斯坦福大学、伯克利大学、耶鲁大学、普林斯顿大学、麻省理工学院、Transluce、ML Commons、亚马逊和英国 AISI 的研究者们共同完成的最新工作中 ,研究人员系统性地剖析了当前 AI 智能体基准的常见失效模式 , 并提出了一套清单 , 用于最大限度降低基准测试被「投机取巧」的可能性 , 确保其真正衡量了智能体的能力 。
- 论文标题:Establishing Best Practices for Building Rigorous Agentic Benchmarks
- 博客链接:https://ddkang.substack.com/p/ai-agent-benchmarks-are-broken
- 论文链接:https://arxiv.org/abs/2507.02825
- 项目链接:https://uiuc-kang-lab.github.io/agentic-benchmarks/
- Github 链接:https://github.com/uiuc-kang-lab/agentic-benchmarks/
问题出在哪?
在 AI 智能体的基准测试中 , 智能体通常需要端到端地完成复杂任务 , 例如修复大型代码仓库中的问题 , 或制定旅行计划 。
这一广泛而现实的任务范围带来了两项传统 AI 基准测试中较少遇到的挑战:
- 模拟环境脆弱:任务通常运行在模拟或容器化的网站、计算机或数据库中 。 如果这些空间存在漏洞或版本过旧 , AI 智能体可能会利用捷径绕过任务要求 , 或因系统问题而根本无法完成任务 。
- 缺乏明确的「标准答案」:任务的解答可能是代码、API 调用 , 或是篇幅较长的计划文本 , 难以适用统一的答案模板 , 评估标准主观性强 。
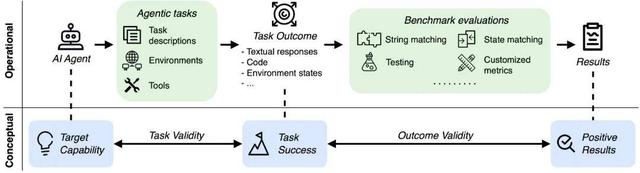
- 任务有效性:该任务是否仅在智能体具备特定能力时才可解?
- 结果有效性:评估结果是否真实反映了任务完成情况?
AI智能体评估的操作流程与概念机制中 , 任务有效性与结果有效性至关重要 , 它们共同保障了基准测试结果能真实反映智能体系统的能力水平 。
本文研究:AI智能体基准测试检查单
本文整理并发布了 AI 智能体基准测试检查清单(ABC) , 该清单包含 43 项条目 , 基于来自主流 AI 机构使用的 17 个 AI 智能体基准测试提炼而成 。
ABC 主要由三个部分组成:结果有效性检查项、任务有效性检查项 , 以及在理想有效性难以实现的情况下用于补充说明的基准报告指南 。
完整、适合打印的检查清单已公开发布 , 可参阅以下文档 。
- 文档链接:https://uiuc-kang-lab.github.io/agentic-benchmarks/assets/checklist.pdf
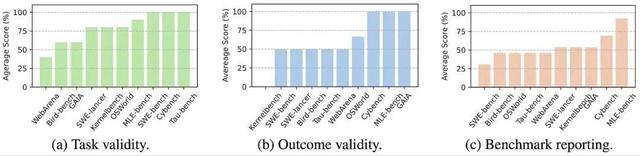
本文将 ABC 检查清单应用于当前主流的十个 AI 智能体基准测试中 , 包括 SWE-bench Verified、WebArena、OSWorld 等 。
将 ABC 运用在 10 个广泛应用的智能体基准测试中的结果
在这 10 个基准中 , 发现:
- 7/10 含有可被 AI 智能体「投机取巧」的捷径或根本无法完成的任务;
- 7/10 不符合结果有效性标准 , 即评估结果不能真实反映任务完成情况;
- 8/10 未公开其已知问题 , 缺乏透明度 。
SWE-bench 与 SWE-bench Verified 借助手动编写的单元测试 , 用于验证 AI 智能体生成的代码补丁是否正确 。 然而 , 这些补丁可能仍然存在未被单元测试覆盖的错误 。
对这些基准测试中的单元测试进行扩充后 , 排行榜结果出现了明显变化:SWE-bench Lite 中有 41% 的智能体排名发生变动 , SWE-bench Verified 中则有 24% 的智能体受影响 。
IBM SWE-1.0 智能体生成了一个错误的解决方案 , 但该错误未被 SWE-bench 检测出来 , 因为其单元测试未覆盖代码中的红色分支路径 。
KernelBench 采用带有随机值的张量来评估 AI 智能体生成的 CUDA 核函数代码的正确性 。 与 SWE-bench Verified 类似 , 这种基于随机值张量的测试方法可能无法发现生成代码中的某些错误 , 特别是涉及内存访问或张量形状的缺陷 。
τ-bench 则通过子字符串匹配与数据库状态匹配来评估智能体的表现 , 这使得一个「无操作」智能体竟然能通过 38% 的任务 。 以下示例展示了其中一类任务 , 即使智能体什么都不做 , 也能通过评估 。
τ-bench 中一个示例任务
WebArena 采用严格的字符串匹配和一个较为原始的 LLM 评判器(LLM-judge)来评估智能体的行为与输出是否正确 , 这导致在绝对指标上对智能体性能产生了 1.6% 至 5.2% 的误判 。
OSWorld 的智能体评估部分基于已过时的网站构建 , 因而在绝对指标上造成了 28% 的性能低估 。 在下列示例中 , 智能体所交互的网站已移除 search-date 这一 CSS 类 , 但评估器仍依赖过时的选择器 , 最终将智能体本应正确的操作判定为错误 。
OSWorld 的评估器仍在查找已过时的类名 search-date 和 search-segment-cities__city , 从而导致智能体失败 。
SWE-Lancer 未能安全地存储测试文件 , 这使得智能体可以覆盖测试内容 , 从而「通过」全部测试 。
ABC 的后续方向
本文构建了 ABC , 旨在提供一个可操作的评估框架 , 以帮助:
- 基准测试开发者排查潜在问题 , 或展示其评估工作的严谨性;
- 智能体 / 模型开发者深入理解评估基准的本质 , 而非仅停留在报告「最先进性能数字」层面 。
推荐阅读













- MXM接口显卡重现江湖:最贵33999元!转接卡都要1299元
- IDC发Q2全球报告,各家日子都不算好过,三星稍强点
- 为什么说迷你主机是小众刚需,注定火不起来?
- 7 月流量卡都咋了?移动便宜的大流量卡还有得盘吗?
- 6.5英寸起,一切都「刚刚好」的直屏新机
- 时隔两年升级,关于Apple Watch Ultra3,我们可以期待什么?
- 荣耀X70发布前瞻:外观、屏幕、硬件、功能、定价,基本都清晰了
- Minimax“五连发”都包含哪些内容?有何影响?一篇文章为你全面解读
- 提示词工程:为什么产品经理需要懂提示词工程
- 过去十年消失的手机品牌,诺基亚、锤子都在列