
文章图片
文章图片
文章图片
文章图片

文章图片
朱昆仑是伊利诺伊大学香槟分校(UIUC)计算机科学系的研究生 , 现隶属于Ulab与Blender Lab , 曾在斯坦福大学、卡内基梅隆大学(CMU)与蒙特利尔学习算法研究所(Mila)进行学术访问 。 他的研究方向包括大语言模型(LLM)智能体、多智能体系统、AI科学家与工具学习等 , 在ICML、ICLR、ACL、TMLR等顶级会议与期刊发表论文10余篇 , 总引用超过1500次 。他积极参与多个广泛影响的开源项目 , 包括 OpenManus(RL)、ChatDev(MACNET)、ToolBench 等 , 累计在 GitHub 上获得超过 5万+ stars 。 此外 , 他曾受邀在 AMD 开发者大会、阿里巴巴云栖大会等重要学术与工业会议中作报告 , 分享其在AI智能体方面的开源成果 。
我们正在见证一个全新的时代:AI 的浪潮从强大的「个体」奔涌向复杂的「团队」 , 它们像人类团队一样协作开发软件、进行科学研究 , 甚至在虚拟世界中展开激烈的策略对抗 。
然而 , 一个问题也随之浮出水面:我们如何判断这些 AI 团队是「三个臭皮匠 , 赛过诸葛亮」 , 还是「三个和尚没水喝」?
现有的评测基准 , 如 AgentBench、GAIA 等 , 大多聚焦于单个智能体的推理和工具使用能力 , 却无法衡量多智能体系统内部至关重要的协作效率、沟通质量和竞争策略 。 这在 AI 能力评估领域 , 形成了一个巨大的「盲区」 。
为了填补这一空白 , 来自伊利诺伊大学厄巴纳-香槟分校的研究者们 , 近日推出了 MultiAgentBench 。 该成果近日被自然语言处理顶级会议 ACL 2025 主会正式接收 。
- 论文标题:MultiAgentBench:Evaluating the Collaboration and Competition of LLM agents
- 论文链接:https://arxiv.org/pdf/2503.01935
- 代码链接:https://github.com/Ulab-UIUC/MARBLE
这不仅是一个评测集 , 更是首个能够全面、系统化地评估 LLM 多智能体系统协作与竞争能力的综合性基准 。 它不仅仅是一套「考题」 , 而更像一个「模拟真实社会动态的实验室」 , 旨在揭示多智能体协作的奥秘 , 并回答一系列关键问题:
- 智能体的能力与协作 , 哪个更重要?
- AI 团队采用哪种组织架构和协作策略效率最高?
- 当 AI 被赋予共同或者冲突的目标时 , 它们会演化出怎样的社会行为?
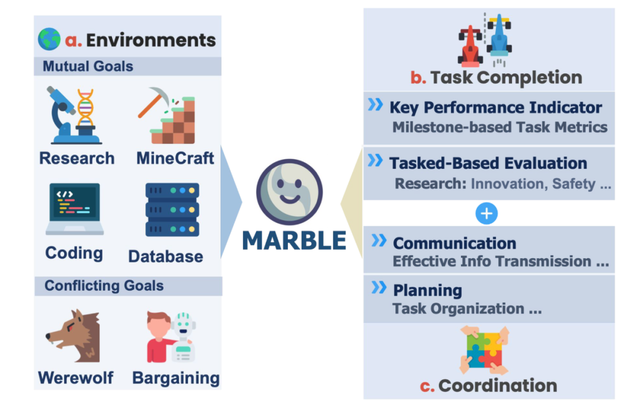
图 1:MultiAgentBench 评估流程概览
MARBLE 的主要贡献包括:
- 提出了 MultiAgentBench 这一综合性基准 , 在六种多样化交互场景中评估基于 LLM 的多智能体系统的协作与竞争 。
- 提出了创新的评估指标:不仅评估任务的完成质量 , 还衡量智能体的协作、规划与沟通的质量 。
- 揭示了多智能体协作中的一些「顿悟时刻」——智能体开始展现出涌现的社会行为 , 为实现类 AGI 级别的协作带来了有希望的启示 。
研究结果揭示了几个关键结论:在众多模型中 , gpt-4o-mini 展现出最强的综合任务能力;在协作模式上 , 「图结构」的去中心化协作模式效率最高;而在规划策略上 , 相比于「小组讨论」等规划方法 , 「认知自演化规划」方法能有效提升任务达成率 。 更重要的是 , 实验观察到了智能体在复杂博弈中自发产生的「社会智慧」 。
图 2:MARBLE 核心框架设计展示
框架设计
MultiAgentBench 的核心在于其背后的协作引擎 MARBLE (Multi-agent coordination Backbone with LLM Engine) 。 它将评测重点从单个智能体能力拓展到智能体之间的关系动态与组织结构 , 使研究者能够系统性分析多智能体协作和对抗过程中的效率与行为模式 。 在多智能体系统中 , 如何高效组织和协作 , 可能与个体能力同样重要 。
图 2 展示了 MARBLE 的整体架构 , 其中包含三个核心模块:
协作引擎
协作引擎作为整个系统的大脑中枢 , 负责整合并调度所有模块 , 明确区分「规划者」(Planners) 和「执行者」(Actors) 的角色 。 这种分工帮助实现从整体规划到具体执行的顺畅衔接 , 使评测能够更好地观测协作效率与执行效果 。
智能体图
智能体图模块不仅记录智能体是谁 , 还通过 (agent1 关系 agent2) 的三元组形式 , 建立起智能体之间的关系网络 , 包括「协作」、「监督」等 。 这种结构化关系使得智能体之间的互动具有可控性和方向性 , 更接近真实团队中的组织架构 。
认知模块
认知模块为每个智能体提供个性化信息、独立的记忆 , 以及多样化的推理方式 , 使其能够根据上下文和交互过程灵活调整策略 , 而非简单执行固定指令 。 这一设计使智能体在多智能体环境中展现出更具适应性和灵活度的行为 , 为研究智能体间协作与互动提供了支持 。
交互策略与环境
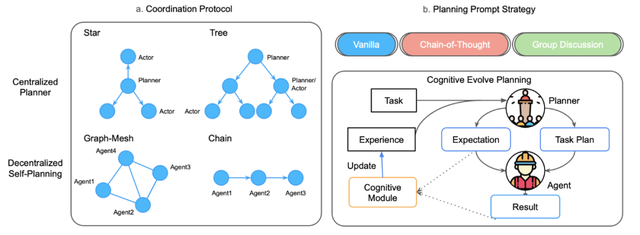
图 3:(a) 协作协议(如星型、树型、图结构与链式);(b) 规划策略 。
交互策略
MARBLE 框架内置了四种协作协议 , 如图 3 所示 , 包括中心化协议(星型、树型)与去中心化协议(图型、链型) , 来模拟现实世界中典型的团队协作模式 。
评测场景
MultiAgentBench 设计了六个覆盖不同领域的评测场景 , 全面模拟了从团队合作到利益冲突的各种应用环境:
- 共同目标:
- 科研 (Research):AI 科学家团队 , 合作撰写研究报告 。
- 我的世界 (Minecraft):AI 游戏团队 , 合作完成游戏目标 。
- 数据库 (Database):AI 数据库工程师团队 , 合作完成数据库开发项目 。
- 编程 (Coding):AI 软件工程师团队 , 合作完成软件工程开发项目 。
- 冲突目标:
- 狼人杀 (Werewolf):模拟狼人杀游戏 。 AI 智能体需要进行欺骗和伪装来获得游戏胜利 。
- 谈判 (Bargaining):模拟真实的商业谈判场景 。 AI 智能体需要在资源有限的情况下 , 通过策略性的让步、联盟或施压 , 为自己争取最大的利益 。
评价指标
图 4:基准创建过程及动态里程碑检测机制 。
任务完成度
- 基于里程碑的 KPI (Milestone-based KPI):这是 MultiAgentBench 评测体系的一大亮点 。 它不再将任务视为一个整体 , 而是将其分解为一系列关键的「里程碑」(例如 , 在科研任务中 , 「完成 5 个关键问题的定义」或「对上一版提案进行实质性改进」) 。 系统通过一个 LLM 裁判 , 动态地检测团队是否达成了这些里程碑 , 并自动记录做出核心贡献的智能体 。
- 任务得分 (Task Score , 以下简称 TS):这是对多智能体系统最终产出质量的综合评分 , 会根据任务类型(如科研、编程、游戏胜负)采用不同的评价标准 。
协作质量
这是对团队「软实力」的量化评估 , 由两个核心分数构成:
- 沟通分数 (Communication score):评估团队内部沟通的效率、清晰度以及信息的有效传递 。
- 规划分数 (Planning score):评估任务分配的合理性、角色维护的一致性以及战略的连贯性 。
- 协作总分 (Coordination Score 以下简称 CS):上述两者的平均值 , 直观地反映了团队的整体协作水平 。
实验结论
高效的协作 ≠ 优异的成果 , 个体能力是基石
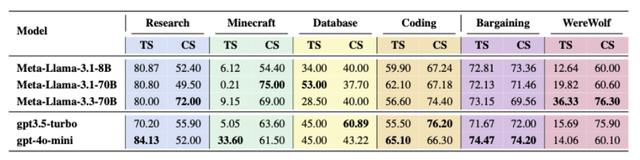
表 1:Minecraft、Database、Coding、Bargaining 与 Werewolf 五个场景中的平均 TS 与协作 CS 。 在三个任务场景中 , 均为同一模型同时取得最高 TS 与 CS , 表明 CS 是衡量 TS 的良好指标 。
沟通顺畅、配合默契的 AI 团队是否就能更加高质量地完成任务?直觉告诉我们「是的」 , 但实验数据(如表 1 所示)却指出——在多智能体系统中 , 协作与个体能力并非总能齐头并进 。
例如 , 在 Minecraft 任务中 , Meta-Llama-3.1-70B 模型展现出了高达 75.00 的 CS , 但其最终的 TS 仅为 0.21 。 协作分高 , 意味着智能体之间在频繁、清晰地沟通 , 并严格遵循着既定规划 。 但如果单个智能体的某项执行能力存在根本性缺陷 , 那么再完美的沟通和规划 , 也是空中楼阁 。
这表明 , 在当前阶段 , 多智能体系统的性能瓶颈首先在于单个智能体的核心能力 。 协作是能力的「放大器」 , 而非能力的「替代品」 。
AI 团队的「组织内耗」:警惕冗余层级与无效讨论
图 5:不同协作协议在多种评估指标下的表现 。
图 6:不同规划提示策略下研究任务的平均指标 。 认知自演化规划在 CS 上表现最佳 。
如图 5 所示 , 在四种协作协议中 , 图结构这种允许所有智能体自由沟通、并行协作的模式 , 在任务得分、规划质量和效率上全面占优 , 紧随其后的是星型 , 而表现最差的是树型结构 , 其层级过多的设计 , 导致沟通成本和信息损耗急剧增加 , 任务得分和协作分均为最低 。 这表明 , 对于需要复杂协作的任务 , 扁平、去中心化的组织架构比层级结构更有效 。
如图 6 所示 , 一个反直觉的结论出现了:让多个 AI 规划师进行「小组讨论」 , 效果竟是所有策略中最差的 。 这或许说明 , 当前阶段的 AI 的小组讨论不仅没能集思广益 , 反而可能陷入「集体降智」 。 与之形成对比的是 , 进行「认知自演化规划」的智能体表现出最佳的协作能力 。 这种策略的核心在于「复盘」——从过去的成败中学习 , 动态调整策略 , 实现持续进化 。 对于 AI 团队而言 , 一个懂得自我迭代和反思的「大脑」 , 比一场七嘴八舌的「头脑风暴」更加宝贵 。
AI 团队的「林格曼效应」
【顶尖AI如何发挥最大战力?UIUC用一个新多智能体协作基准寻找答案】
图 7:不同智能体数量对 KPI、CS 与 TS 的影响 。
在探究团队规模的影响时 , 实验发现 , 将智能体数量从 1 个增加到 3 个时 , 协作分数和任务分数得到了提升 。 然而 , 当继续增加智能体数量时 , 整体的 KPI 反而开始下降 。
这一现象与组织行为学中的「林格曼效应」(团队规模越大 , 个体贡献越倾向于减少)高度吻合 。 团队规模的扩大并非简单的「人多力量大」 , 这意味着 , 未来构建大规模 AI 智能体系统的关键 , 将是如何设计出高效、低开销的协作机制 , 以克服规模扩张带来的内在复杂性 。
「Aha-Moments」:当 AI 开始展现社会智慧
MultiAgentBench 最重要的发现 , 或许是在「狼人杀」和「谈判」这类竞争性场景中 , 观察到的一系列惊人的「涌现行为」 。 这些复杂的社会策略并非由人类编码设计 , 而是 AI 为了赢得胜利这一最终目标 , 自发「学习」和「演化」出来的 。
- 战略性沉默:在「狼人杀」游戏中 , 「预言家」智能体学会了不再第一时间公布自己的验人结果 。 它会评估风险 , 选择性地、在最关键的时刻才披露信息 , 以求最大化收益并保护自己 。 这是一种基于风险评估的「战略性沉默」 , 是高级博弈能力的体现 。
- 信任与猜忌:实验中 , 村民阵营会因为内部猜忌而产生「内斗」 , 互相攻击;而狼人阵营则能通过高度一致的欺骗和内部协作 , 制造「虚假共识」来迷惑对手 。 这表明 , 智能体正在根据角色和信任关系 , 自发地形成动态的联盟和敌对关系 。
- 动态适应环境:游戏中的「女巫」角色 , 其行为策略会随着战局的演进而动态变化 。 在游戏早期 , 它倾向于「囤积」宝贵的药水;而到了游戏后期 , 为了求胜 , 它会变得更具「冒险精神」 。 这展示了智能体策略的高度动态性和对环境的适应性 。
这些「Aha-Moments」标志着 LLM 智能体正在经历一次从纯粹的「逻辑推理机器」 , 向具备初级社会行为能力的角色的转变 。 它们正在学习和运用人类社会互动中最核心的元素:欺骗、信任、策略和权衡 。 当一个智能体开始思考「其他智能体正在思考什么」时 , 这正是「心智理论」的雏形 。
总结
MultiAgentBench 的推出 , 为我们打开了一扇观察和理解 AI 群体智能的窗户 。 它不仅仅是一个评测工具 , 更是一个强大的「社会模拟器」 , 系统性地揭示了构建高效 AI 团队的几条重要准则:
- 个体能力是基石:协作是能力的放大器 , 而非替代品 。 没有强大的个体 , 再好的团队协作也只是空中楼阁 。
- 组织结构定成败:扁平、去中心化的网络结构胜于层级的树型模式 , 后者会带来巨大的「组织内耗」 。
- 规模并非多多益善:AI 团队同样受「林格曼效应」的约束 , 盲目扩大规模反而会降低效率 , 如何设计低成本的协作机制是关键 。
- 社会智能的涌现:在合适的博弈环境下 , AI 能够自发学习并展现出「战略性沉默」、「信任分化」等高级社会行为 , 这是通往更高级别人工智能的希望所在 。
总而言之 , 这项工作标志着我们对 AI 的研究 , 正在从关注「个体智商」迈向理解「群体情商」的新阶段 。 未来 , 通过构建更复杂的交互环境 , 我们将能更好地理解、引导并最终利用这种强大的新兴智能 , 为解决现实世界中的复杂问题 , 迈出坚实的一步 。
推荐阅读














- 国补下半场激战来袭,智能投影如何从 “浪潮” 里捞走更多真金?
- 18A工艺该发挥实力了:英特尔新款至强可拥有192核心
- V·STAR顶尖人才计划|顶薪+期权,与VAST一起定义下一代3D范式
- 三次卖到断货,荣耀新旗舰如何成为“真香机”?
- EUV,是如何工作的?
- 如何用DeepSeek做数据分析?这套方法超神!
- 十年AI医疗实战复盘:无光环、无资本,我们如何靠「真痛点」撕开市场?
- 潘春节解密“双轨并驱”:机械革命如何在PC红海杀出重围
- 当石头科技碰上顶尖艺术院校:冰冷的电器硬件变了
- 96Gbps超高带宽加持!HDMI 2.2规范如何赋能显示终端新一轮创新革命