
文章图片

文章图片

文章图片
文章图片

文章图片

文章图片

文章图片

文章图片
设想一下刚学开车的情况:在训练场上 , 我们可能会反复练习特定动作:到了某个位置就踩刹车 , 拐到某个点就打方向盘 。 久而久之 , 这些动作会形成 “条件记忆” , 一旦环境发生变化 , 就容易手忙脚乱 。 最近 , 千寻智能的研究人员注意到 , 基于模仿学习的视觉运动策略中也存在类似现象 , 并在论文《Do You Need Proprioceptive States in Visuomotor Policies?》中对此进行了深入探讨 。
论文链接:https://arxiv.org/abs/2509.18644 项目主页:https://statefreepolicy.github.io
文中研究人员提出了一种名为 State-free Policy 的策略 , 与 State-based Policy 相比 , 即便在训练数据中桌面高度、机器人位置和目标物体等都被严格固定的情况下 , 机器人仍能展现出强大的空间泛化能力 。 例如:
在夹笔任务中 , 获得桌面高度的泛化能力(标准桌高为 80 cm):
在叠衣服任务中 , 即使机械臂位置大幅偏离标准位置 , 机器人仍然能出色完成任务:
【纯视觉VLA方案从有限数据中学到强大的空间泛化能力】在全身机器人从冰箱拿饮料的过程中 , 即使冰箱位置发生移动 , 机器人也能够适应:
事实上 , 在机器人操作领域 , 基于模仿学习的视觉运动策略已经被广泛应用 。 不过 , 为了实现精确而可靠的控制 , 这类模型通常不仅依赖对任务环境的视觉观察 , 还会引入所谓的 “状态” 信息 —— 包括末端执行器的位置、关节角度等自身感知数据 。 这些状态信息能够为策略提供紧凑且精确的机器人姿态描述 , 但同时也带来一个问题:模型容易通过记忆训练轨迹而产生过拟合 , 从而严重限制空间泛化能力 。 尤其在当前环境下 , 获取大量包含位置泛化的真机数据成本极高 , 这已经成为制约视觉运动策略发展的关键瓶颈 。
State-free Policy 的工作条件
为了应对空间泛化能力差的问题 , 研究人员提出在视觉运动策略的输入中完全移除状态信息 , 仅依赖视觉观察 , 这一策略被称为 “State-free Policy” 。 该方法基于两个关键条件:一是动作在相对末端执行器空间中表示;二是确保视觉输入能够覆盖任务所需的完整观察范围 , 即完整的任务观察:
1. 相对末端动作空间:在这种动作表示空间下 , 模型根据输入预测当前末端执行器应该进行的相对移动 , 例如向 x 方向移动 1 厘米 , 而不是直接预测末端执行器相对于机器人本体的具体位置 。 这样的表示方式可以让策略更专注于动作的相对变化 , 而不是依赖精确的全局位置信息 , 从而降低对状态输入的依赖 , 提高在不同环境下的泛化能力 。
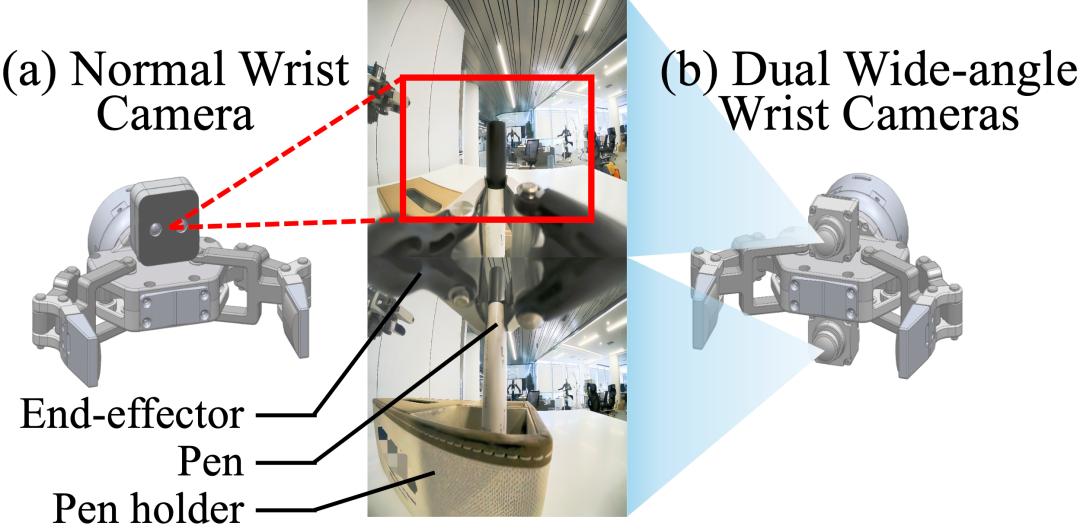
2. 完整的任务观察:在常见的输入状态的做法中 , 状态输入可以给策略提供大致的任务信息 , 例如到达某一个状态后模型就知道还需要大致运动多少就能够到达目标位置 , 而不需要关注图像输入中复杂的环境 。 为了提高策略的泛化性 , State-free Policy 移除了状态输入 , 因此任务中所有的物体信息必须全部由视觉输入提供 , 这促使我们为机器人的末端执行器配备更广阔的视野 。 本文中的相机系统由位于机器人头顶的主摄和腕部相机构成 。 如上图所示 , 在常规设定下 , 末端执行器上方会安装一个常规相机 。 而在双目广角设定下 , 研究者在末端执行器上方和下方都安装了一个广角相机 , 来提供更广泛的视野和末端执行下方的视野 。 不过需要注意的是 , 这种设定是为了即使在最复杂的环境下也能获得完整的任务观察 , 有时在简单的环境中常规的设定也可以满足完整的任务观察需求 。
真机实验结果
为了验证 State-free Policy 的空间泛化能力 , 研究人员进行了广泛的实验 , 尤其是在真机任务中 。 这些实验涵盖了不同的任务 , 包括简单的拾取放置任务、困难的叠衣服任务以及使用全身机器人在冰箱中拿取饮料的任务 。 这些任务的数据是有着严格的收集标准 , 即数据中物体的摆放均收到严格控制 , 例如在夹笔放入笔筒的任务中 , 桌面高度严格不变 , 且笔筒的位置也严格不变 。 这样的设定是保证空间泛化能力来自于模型本身 , 而不是泛化的数据 。 此外 , 研究人员发现除了更好的空间泛化能力之外 , State-free Policy 还具备包括更高的数据应用效率以及更快的跨本体泛化的优点 。 在此基础上 , 研究人员还有一个有趣的发现 , 那就是移除顶端的主摄可以进一步提高空间泛化能力:
如上图所示 , 在简单的拾取放置任务中 , 相比于有状态输入的策略 , State-free Policy 拥有显著更强的空间泛化能力 , 包括高度和水平泛化能力 。 例如 , 在夹笔放入笔筒的任务中 , 高度泛化的测试成功率从 0 提升到了 0.98 , 水平泛化的测试成功率从 0 提升到了 0.58;而相比于常规的相机设定 , 具有完整任务观察的设定使高度泛化的测试成功率从 0.87 提升到了 0.98 , 水平泛化的测试成功率从 0.27 提升到了 0.58 。
与此同时 , 在一些更困难的任务中 , 例如叠衣服 , 以及利用全身机器人从冰箱里取饮料(由于硬件限制 , 只进行了常规相机下的水平泛化能力测试) , State-free Policy 的水平泛化能力明显超过了带有状态输入的模型 。 以上实验证明了 State-free Policy 具有显著更强的空间泛化能力 , 能在数据多样性受限的情况下获得强大的空间泛化能力 。
State-free Policy 的额外优势
除了更强的空间泛化能力之外 , State-free Policy 还展现出更高的数据利用效率 。 相比之下 , 基于状态的策略往往需要大量多样化的示范数据来避免过拟合特定轨迹 , 从而增加了数据收集成本 。 而 State-free Policy 不易陷入这一问题 , 即使在数据有限的情况下也能保持良好表现 。 研究人员在夹笔任务中进一步验证了这一点:在不同规模的数据下(300、200、100、50 条演示数据) , 随着数据量减少 , 基于状态的策略迅速过拟合并导致性能下降 , 而 State-free Policy 则始终保持更高的成功率 。
另外 , State-free Policy 在跨本体微调中也展现出优势 。 相比依赖状态输入的策略需要重新对齐状态空间 , State-free Policy 只需在相似相机配置下适应轻微的图像偏移 , 因此能更高效地完成跨平台迁移 。 在叠衣服任务中 , 研究人员先在双臂 Arx5 上训练 , 再将其适配到人形双臂机器人 , 并用 100 条演示数据进行微调 。 上表的结果表明 , State-free Policy 收敛更快 , 成功率更高 , 验证了其更强的跨平台适应能力 。
在移除限制空间泛化的状态输入后 , 研究人员进一步思考是否还存在其他潜在瓶颈 , 并指出顶置相机可能同样带来问题 。 由于物体位置变化会导致顶视角下的图像分布发生偏移 , 在极端情况下(如桌面升至 100 cm)甚至会严重影响性能;而腕部相机则可随末端执行器移动 , 始终获得与训练时一致的相对视角 。 鉴于双广角腕部相机已能覆盖完整任务观察 , 顶置相机不仅多余 , 甚至可能带来负面影响 。 为验证这一点 , 研究人员在夹笔放入笔筒任务中设计了三种更具挑战性的情景:桌面升至 100 cm、笔筒加高一倍 , 以及笔筒在水平方向移动 20 cm 。
上表的结果显示 , 带有顶置相机的 State-free Policy 在这三种情景下表现均不理想 , 而仅使用双广角腕部相机的策略则始终保持较高成功率 。 这一发现提示我们 , 有必要重新审视传感器设计 , 未来或许应考虑去除顶置相机 。
总结
在本研究中 , 研究人员提出了 State-free Policy , 并基于两个条件加以实现:相对末端执行器动作空间 , 以及通过足够全面的视觉信息获取完整的任务观察 。 在不依赖状态输入的情况下 , 该策略不仅能够保持完美的域内性能 , 还在空间泛化方面取得了显著提升 。 同时 , State-free Policy 有效降低了对昂贵真实数据的需求 , 支持更高效的跨平台适应 , 并为未来的传感器设计提供了新的思路 , 为构建更具泛化能力的机器人学习系统提供了新的启示 。
推荐阅读















- LightVLA可微分token剪枝,首次实现VLA模型性能和效率的双重突破
- 苹果传统强项再发力,视觉领域三种模态终于统一
- 智能头戴设备AiSee为视障人士提供全新\视觉\体验
- 诺奖得主、谷歌AI掌门人泼冷水:所谓“博士级智能”纯属无稽之谈
- 具身VLA后训练:TeleAI提出潜空间引导的VLA跨本体泛化方法
- 基于3DGS场景理解和视觉语言预训练,让3D高斯「听懂人话」的一跃
- 8800+内存纯白次元主板进化!ROG X870吹雪S超详测评
- SuperCLUE多模态视觉评测榜出炉:文心4.5 Turbo并列国内第一!
- 对话优理奇CEO杨丰瑜:00后创业不押注VLA,把机器人先送进酒店干活
- 曝REDMI K90系列上2K LTPS纯直屏、全员潜望镜