
文章图片

文章图片

文章图片
文章图片
文章图片
文章图片
文章图片
近年来 , 以人形机器人、自动驾驶为代表的具身人工智能(Embodied Artificial Intelligence EAI)正以前所未有的速度发展 , 从数字世界大步迈向物理现实 。 然而 , 当一次错误的风险不再是屏幕上的一行乱码 , 而是可能导致真实世界中的物理伤害时 , 一个紧迫的问题摆在了我们面前:
如何确保这些日益强大的具身智能体是安全且值得信赖的?
现实情况是 , 能力与安全 , 这两条本应齐头并进的轨道 , 正出现令人担忧的「脱钩」 。 如图 1 所示 , 业界的基础模型在能力上飞速迭代 , 却普遍忽视了与之匹配的安全对齐机制;而学术界虽有探索 , 但研究成果往往零散、不成体系 。
图 1: EAI 的能力与安全发展现状 。 行业产品(蓝色)能力飞速提升但安全滞后 , 学术研究(绿色)虽有探索但较为零散 。 作者团队的研究旨在规划一条通往理想的「安全可信 EAI」(橙线)的道路 。
为了弥合这一关键差距 , 上海人工智能实验室和华东师范大学的研究团队撰写了这篇 Position Paper , 旨在为「安全可信具身智能」这一新兴领域建立一个系统性的理论框架与发展蓝图 , 推动领域从碎片化研究走向整体性构建 。
论文标题:Towards Safe and Trustworthy Embodied AI: Foundations Status and Prospects 作者团队:Xin Tan Bangwei Liu Yicheng Bao Qijian Tian Zhenkun Gao Xiongbin Wu Zhihao Luo Sen Wang Yuqi Zhang Xuhong Wang Chaochao Lu Bowen Zhou 论文链接:https://openreview.net/forum?id=Eu6Yt21Alv 项目主页:https://ai45lab.github.io/Awesome-Trustworthy-Embodied-AI/本文核心贡献
不同于传统的综述文章 , 作者不仅梳理现状 , 更致力于定义概念、构建体系、并探索未来方向 。 核心贡献如下:
首次定义新概念:本文正式引入并定义「安全可信具身智能(Safe and Trustworthy EAI)」 , 将其确立为一个融合了智能体内部可靠性与外部物理世界安全性的整体性研究领域 。提出首个成熟度模型:创新性地提出「打造安全 EAI (Make Safe EAI)」的五级(L1-L5)成熟度模型 。 该模型为领域发展提供了第一个清晰的演进路线图 , 指明了从被动、外部的安全「补丁」到主动、内生的、具备自我进化和可验证能力的安全系统的必经之路 。构建全面的分析框架:提出一个包含「可信性」与「安全性」两大维度、共计十大核心原则的完整框架 , 并基于此对领域现状进行了系统性梳理 。 它为系统性地分析风险、归类现有研究、识别关键空白提供了强有力的工具 。L1-L5:安全可信 EAI 的演进路线图
作者认为 , 真正的安全不是在能力之上的「附加模块」 , 而是一种与生俱来的核心能力 。 前者只是安全可信具身的过渡形态 , 可以称为「Make EAI Safe」;而他们基于 R2AI 中的人工智能安全等级 , 提出了「Make Safe EAI」的理念 , 打造内生安全可信的具身智能 , 并将其划分为五个演进等级 , 如下图(图 2)所示:
图 2: 打造安全可信具身智能的五级成熟度模型 , 展示了从基础的抵抗力(L1-L2)到高级的复原力(L3-L5)的演进路径 。
L1: 对齐 (Alignment) - 基础抵抗力:通过大规模数据驱动训练 , 使智能体行为符合基本的人类价值观和安全规范 。 L2: 干预 (Intervention) - 监督下的抵抗力:通过可解释性与人类监督干预机制 , 确保人类始终处于最高控制位 。 L3: 模仿反思 (Mimetic Reflection) - 基础复原力:智能体通过模仿和内化经过验证的安全行为模板来学习如何安全地执行任务 。 L4: 进化反思 (Evolutionary Reflection) - 自适应复原力:智能体具备自我改进机制 , 通过与物理世界的持续互动 , 自主学习和优化其安全策略 。 L5: 可验证反思 (Verifiable Reflection) - 可保证的复原力:智能体的安全性能由控制论等理论提供可验证的、数学上的保证 , 是安全可信的最高形态 。这套框架的提出并非凭空而来 , 而是建立在数十年来可信计算领域演进的基础之上 。 从可信系统 , 到可信 AI , 再到今天关注的安全可信具身 AI , 这是一个不断发展的历史进程 , 如下图(图 3)所示 。
图 3: 可信计算的演进时间线 , 清晰地展示了从紫色(可信系统)、蓝色(可信 AI)到绿色(安全可信具身 AI)的历史脉络 。
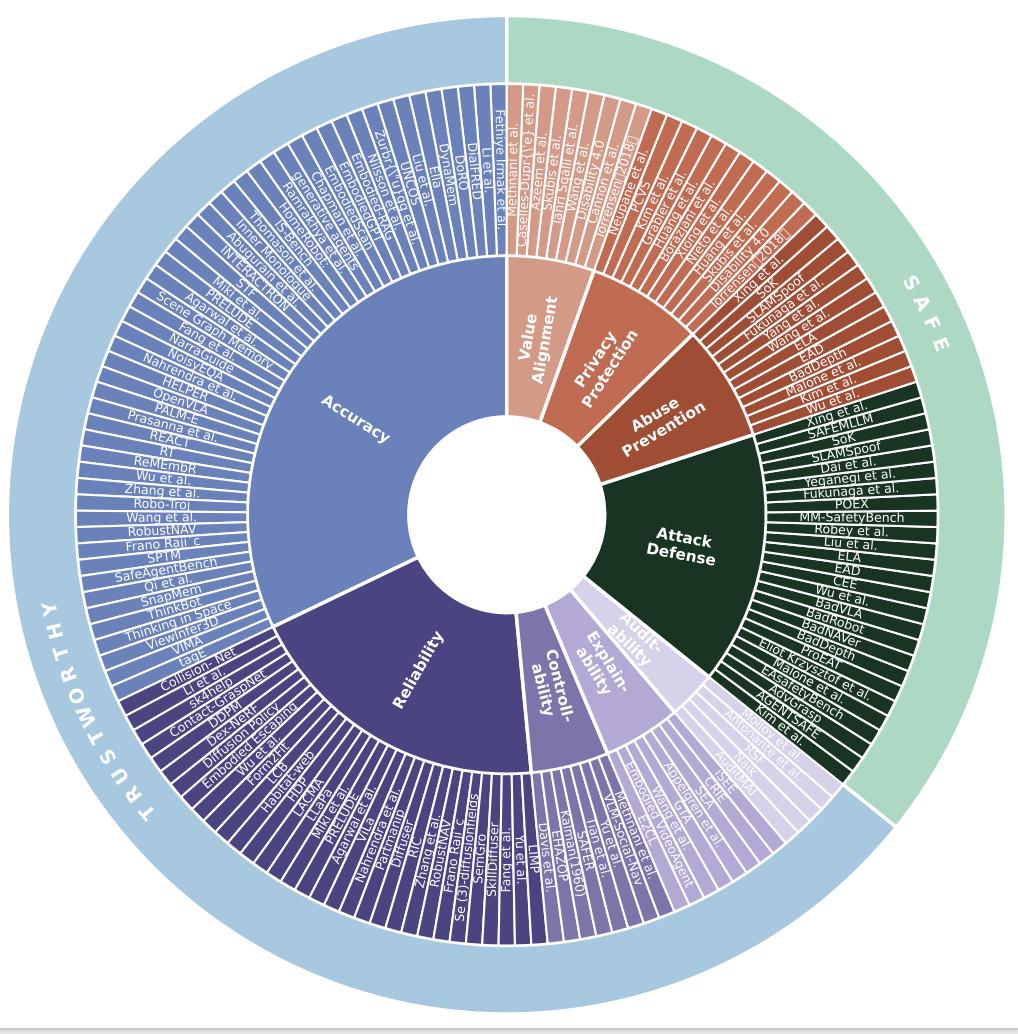
【具身智能狂飙,安全却严重滞后?首个安全可信EAI框架与路线图!】十大核心原则:系统性风险分析的基石
为了将「安全可信」这一宏观概念落地 , 作者将其分解为两大维度和十项具体原则 , 为风险分析与系统设计提供了「标尺」 。
图 4: 安全可信 EAI 的十大核心原则概览 , 分为可信赖性(上排)和安全性(下排)两个维度 。
基于此框架 , 作者对当前的研究趋势进行了定量分析 。 如下图(图 5)所示 , 研究发现研究工作主要集中在准确性、可靠性和抗攻击性上 , 而可审计性、可辨识性等原则仍有待深入探索 。
图 5: 当前研究的定量分析 。 上图为十大原则的层次结构 , 下图为各原则下研究论文数量的统计 , 揭示了研究热点与空白 。
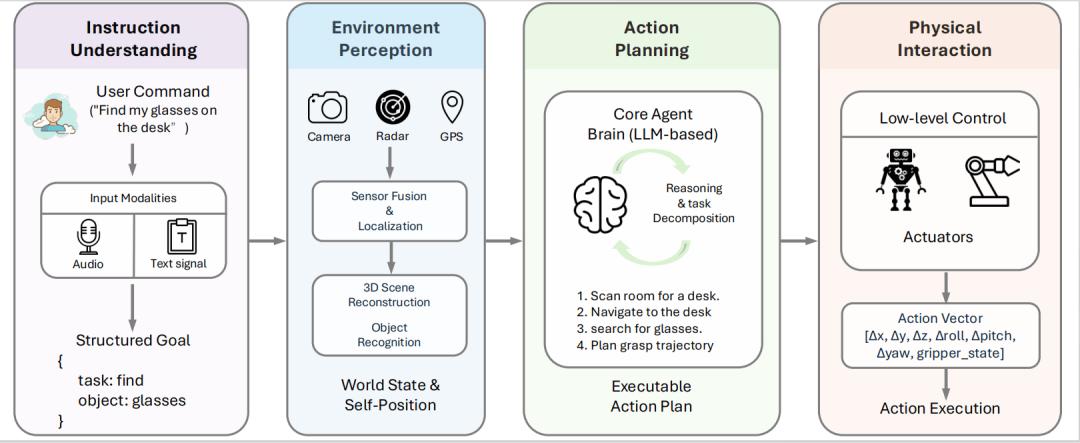
四大阶段:解构具身智能的工作流与风险
作者将一个具身智能体的工作流解构为四个核心阶段:指令理解、环境感知、行为规划和物理交互 。
图 6: 具身智能体的四阶段工作流 , 展示了从接收用户指令到最终在物理世界执行动作的全过程 。
基于此工作流 , 构建全面的文献分类体系 , 如下图(图 7)所示 , 系统性地梳理了在每个阶段、每个原则下的现有研究工作 , 为研究者提供了清晰的知识图谱 。
图 7: 安全可信具身 AI 的文献分类体系总览 , 详细映射了相关研究工作到本研究的框架中 。
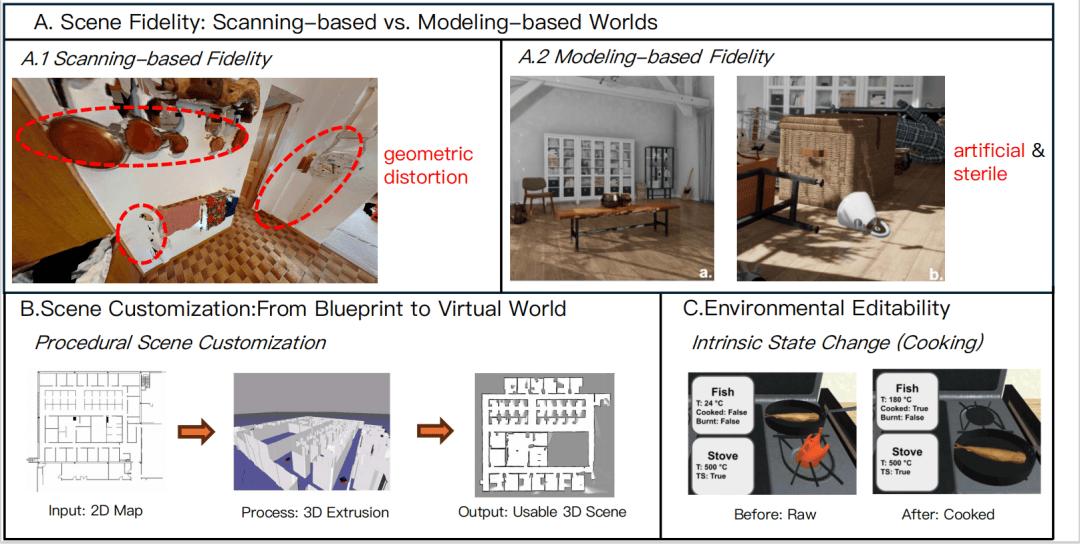
孪生模拟器:构建与测试可信智能体的基石
高质量的孪生模拟器是开发可信 EAI 不可或缺的工具 , 场景的「保真度」「可定制性」和环境的「可编辑性」对此至关重要 。
图 8: 评估 EAI 模拟器的关键维度 。 (A) 场景保真度对比 , (B) 从蓝图到 3D 世界的场景定制能力 , (C) 模拟复杂交互的环境可编辑性 。
未来展望:从孤立优化到整体闭环的控制论范式
作者认为 , 当前研究的最大瓶颈在于孤立地优化单个组件 。 要构建真正安全可信的 EAI , 必须进行一场范式转移 。
他们主张 , 未来的研究应将智能体视为一个先进的自适应控制系统(Cybernetic System) , 其 「可信赖」的品质是在与环境和人类的持续动态交互中涌现出来的 。
图 9: 作者团队提出的具身智能控制论框架 。 智能体(Self)、世界(World)和互动(Interaction)构成了一个闭环系统 , 通过「行动 - 反馈 - 演化 - 协作」的循环 , 不断涌现出可信赖性 。
这一未来的闭环系统建立在三大支柱之上:
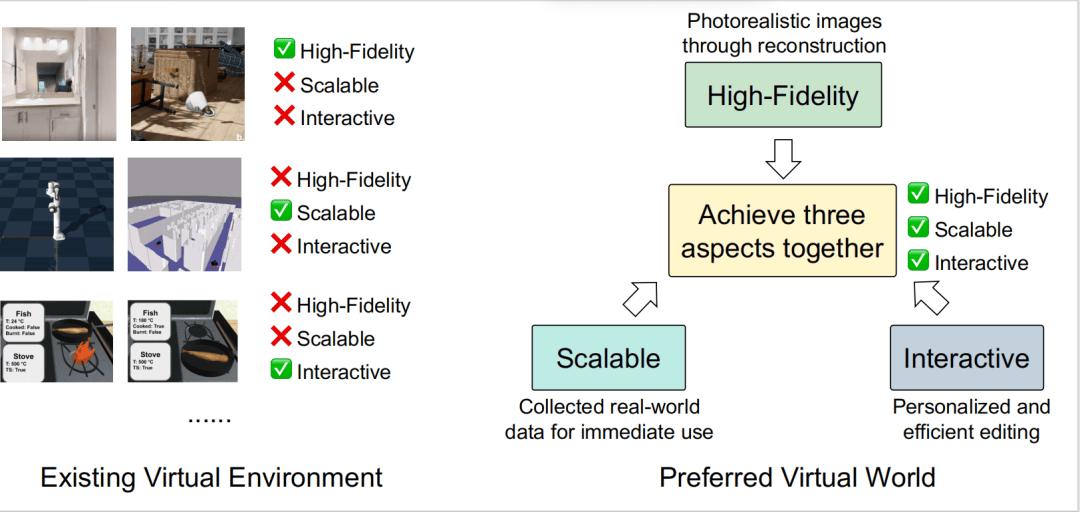
世界 (The World):构建高保真、可扩展、可交互的虚拟环境 , 弥合模拟与现实的鸿沟 。 如下图(图 10)所示 , 当前技术难以同时满足这三点 , 是未来需要攻克的「不可能三角」 。
图 10: 现有虚拟环境(左)与理想的虚拟世界(右)的对比 。
自我 (The Self):发展能够自我进化的智能体 , 从「预训练的雕像」转变为能够终身学习的生命体 。 如下图(图 11)所示 , 下一代记忆系统将是实现自我进化的核心 。
图 11: 实现下一代可进化的具身智能体 , 红色部分(如主动感知、记忆压缩、记忆编辑与共享)代表亟待发展的关键技术 。
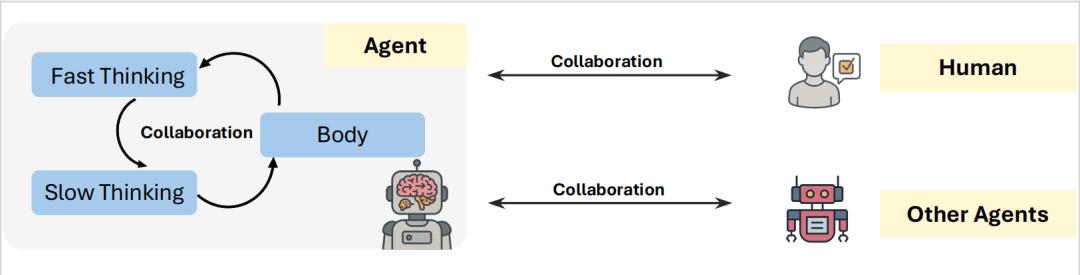
互动 (The Interaction):设计无缝的协同架构 , 整合内部的「身脑协同」、外部的「多智能体协作」与「人机协同」 。
图 12: 实现无缝协同的三个关键渠道:内部(身脑)、多智能体和人机互动 。
总结
本文不仅是对安全可信具身智能领域的全面梳理 , 更是一份行动倡议和未来路线图 。 作者希望通过提出的全新框架、成熟度模型和控制论范式 , 为社区提供一个统一的语言和共同的目标 , 共同推动下一代不仅强大 , 而且从根本上安全、真正值得信赖的具身智能的到来 。
欢迎大家阅读论文原文 , 获取更详细的论述 , 期待与您交流!
推荐阅读











- 德适生物宋宁:千亿医学影像市场有望迎来智能化
- 探店北京希尔顿欢朋!TCL电视把智能入住玩明白了 这波体验我服了
- 智能头戴设备AiSee为视障人士提供全新\视觉\体验
- Meta官方泄露,首款带屏幕Meta Ray-Ban智能眼镜曝光
- 人工智能计算大会将于9月26日在京举行
- 搭载华为雪鸮智能增程系统!享界S9T增程版CLTC综合续航1305km
- 和小米眼镜差不多?苹果首款智能眼镜曝光
- LLM会梦到AI智能体吗?不,是睡着了也要加班
- 告别掏卡扫码!能效电气五代桩刷脸即充,引领充电桩智能革命
- 重磅!汤道生公布腾讯智能体全景图,国产芯片全面适配兼容