
文章图片

文章图片

文章图片

文章图片
文章图片

文章图片
【谁说Scaling Law到头了?新研究:每一步的微小提升会带来指数级增长】
机器之心报道
编辑:张倩
很多人认为 , Scaling Law 正在面临收益递减 , 因此继续扩大计算规模训练模型的做法正在被质疑 。 最近的观察给出了不一样的结论 。 研究发现 , 哪怕模型在「单步任务」上的准确率提升越来越慢 , 这些小小的进步叠加起来 , 也能让模型完成的任务长度实现「指数级增长」 , 而这一点可能在现实中更有经济价值 。
如果继续扩大计算规模 , 边际收益却在递减 , 企业继续真金白银投入更大模型的训练是否还是一个合理的选择?大概从去年开始 , AI 领域就在争论这一问题 。
最近 , 有篇论文给出了一个有意思的观点:虽然 scaling law 显示 LLM 在测试损失等指标上存在收益递减 , 但模型在现实世界的价值往往源于一个智能体能够完成任务的长度 。 从这个角度来看 , 更大的模型非但没有收益递减 , 反而能将单步准确率的微小提升复合放大 , 在任务完成长度上实现指数级跃升 。
论文标题:The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs 论文链接:https://arxiv.org/pdf/2509.09677 代码链接:https://github.com/long-horizon-execution/measuring-execution 数据集链接:https://huggingface.co/datasets/arvindh75/Long-Horizon-Execution这篇论文来自剑桥大学等机构 。 论文指出 , 长期以来 , 完成长程任务一直是深度学习的致命弱点 。 自动驾驶 demo 很炫酷 , 但要真正上路跑长途 , 用了十多年才实现 。 AI 能生成惊艳的图片 , 但拍一段连贯、一致的长视频至今仍是难题 。 现在企业都想要 AI 帮忙处理整个项目 , 而不只是回答零散问题 。 但这里有个核心疑问:我们该如何衡量 LLM 能可靠执行多少步的工作?
LLM 在简单长任务上的失败被认为是推理能力的根本缺陷 。 尽管 LLM 在复杂推理基准测试上有了巨大改进 , 依然有论文声称思考模型只是给出了「思考的幻觉」(arXiv:2506.06941) , 因为当任务变得更长时 , 它们最终会失败 。
这些结果在社区中引发了很多争论 。 但本文作者认为 , 我们可以通过解耦推理或智能体任务中规划(planning)和执行(execution)的需求来解决这个问题 。
规划涉及决定检索什么信息或使用什么工具以及使用顺序 , 而执行就是让规划变成现实 。 在《思考的幻觉》论文中 , LLM 显然知道规划 , 因为它最初正确地执行了许多步骤 。 本文研究者认为 , 最终的失败在于执行 —— 随着任务变长 , 模型在执行规划时更容易犯错 。 尽管人们非常关注 LLM 的规划能力 , 但执行仍然是一个研究不足的挑战 。 随着 LLM 开始用于长推理和智能体任务 , 这一方向变得越来越重要 。
在这篇论文中 , 作者在受控环境中测量了 LLM 的长程执行能力 。 他们通过显式提供所需的知识和规划来隔离 LLM 的执行能力 。 通过控制轮数和每轮的步骤数(它们共同构成任务长度) , 他们揭示了关于 LLM 长程任务执行能力的见解:
1、Scaling 是否存在收益递减?
作者观察到 , 虽然单步准确率的提升幅度在减小 , 但准确率的微小提升可以复合放大 , 进而导致模型能够完成的任务长度呈指数级增长 。
过去大家觉得 , scaling 模型大小之所以会有用 , 是因为这会提高模型存储参数化知识或搜索规划的能力 。
然而 , 作者在实验中发现 , 在显式提供了所需的知识和规划后 , scaling 模型大小仍能显著提高模型成功执行的轮次数量 。 这说明 scaling 模型的价值不仅体现在能让模型记住更多知识或更会寻找问题解答上 。
2、Self-Conditioning 效应
人们可能会认为 , 长任务中的失败仅仅是由于小而恒定的每步错误率不断累积造成的 。 然而 , 作者发现 , 随着任务的推进 , 每步错误率本身会上升 。 这与人类形成了对比 , 人类在执行任务时通常会通过练习而进步 。
作者推测 , 由于模型训练的很大一部分是根据上下文预测最可能的下一个 token , 因此让模型以自身容易出错的历史为条件会增加未来出错的可能性 。 他们通过控制展示给模型的历史中的错误率来对此进行测试 。 随着历史中的错误率升高 , 他们观察到后续步骤的准确率急剧下降 , 这验证了模型会进行 self-condition 设定 。
作者表明 , 除了先前已发现的长上下文问题外 , self-conditioning 设定还会导致模型在长程任务中的性能下降 , 而且与长上下文问题不同的是 , 这种性能下降并不会通过增大模型规模而得到缓解 。
3、思考的影响
作者发现近期的思考模型不会受到先前错误的影响 , 能够修正 self-conditioning 限制 。 此外 , 顺序测试时计算量(sequential test time compute)的显著提升了模型在单轮对话中可完成任务的长度 。 在没有思维链(CoT)的情况下 , 像 DeepSeek V3 这样的前沿大语言模型甚至连两步执行都无法完成 , 而其具备思考能力的版本 R1 则能执行 200 步 , 这凸显了行动前进行推理的重要性 。
作者对前沿思考模型进行了基准测试 , 发现 GPT-5 的思考版本(代号 Horizon)能够执行超过 1000 步 , 远超紧随其后的竞争对手 —— 能执行 432 步的 Claude-4-Sonnet 。
LLM 能力的「参差不齐」既令人着迷又让人困惑 。 与传统机器不同 , 大语言模型在执行重复性任务时更容易出现故障 。 因此 , 作者认为 , 长任务中的执行失败不应被误解为缺乏推理或规划能力 。 他们发现 , 通过扩大模型规模和增加顺序测试时间的计算量 , 模型长程执行能力会得到显著提升 。 如果一个模型能够完成的任务长度表明其经济价值 , 那么持续投入以增加计算量可能是值得的 , 即便短任务基准测试给人一种进展放缓的错觉 。
这篇论文让很多人感觉深受启发 , 还有人提出我们应该设计更多针对模型执行深度方面的基准测试 , 以更好地衡量模型 scaling 所带来的收益 。
以下是论文的详细内容 。
论文方法详解
在论文中 , 作者详细介绍了他们的每一个结论是怎么得出来的 。
虽然单步准确率收益递减 , 但 scaling 仍有价值
作者首先分析了模型的单步准确率与其预测范围长度之间的关系 。 为了得出数学关系 , 他们做出了两个类似于 LeCun (2023) 的简化假设 。 第一 , 他们假设模型的步准确率在任务过程中保持恒定 。 第二 , 他们假设模型不会自我修正 , 这意味着任何单一错误都会导致任务失败 。 他们仅在此次分析中做这样的假设 , 该分析能提供有用的直觉 。 他们的实证分析则更进一步 , 还研究了 LLM 在实际情况中如何在长程任务执行时不表现出稳定的步骤准确率 , 以及它们可能如何纠正错误 。
命题 1:假设步骤准确率 p 恒定且无自校正 , 模型达到成功率 s 时的任务长度 H 由下式给出:
作者在图 2 中绘制了 s=0.5 时的这一增长函数 。 注意 , 当步骤准确率超过 70% 后 , 步骤准确率的微小提升会带来比指数级更快的任务长度改善 。 这一推导表明 , 即使在通常包含短任务的问答基准测试中 , 准确率的提升似乎放缓 , 但从数学角度而言 , 人们仍可期待在更长的任务上取得显著收益 。
作者注意到 , 人类劳动的报酬往往是按时间计算的 。 如果一个智能体的经济价值也源于它能够完成的任务时长 , 那么单轮或短任务基准可能并非评估进一步投资于大语言模型计算资源所带来收益的可靠参考 。 这些基准可能会让人产生进展放缓的错觉 , 而作者认为 , 更能体现经济价值的指标 —— 模型能够完成的任务时长 , 实际上仍在快速增长 。
通过解耦规划和知识来隔离执行
接下来 , 作者描述了如何通过实证方法衡量模型的长程任务执行能力 。
首先 , 团队给出了一个很有启发性的例子:一个用于热门且具有经济价值的航班预订任务的智能体 。
在接收到搜索结果后 , 它必须对显示的航班进行评估 , 以确定要预订哪一个 。 评估单个航班选项的计划可能包括一系列操作 , 例如查看详细信息 , 核实航班时间、行李限额和航空公司评价是否符合用户偏好 , 应用任何可用的折扣或奖励计划 , 以及最终根据成本和行程时间做出选择 。 这些独立步骤中的每一步都需要检索一些信息 , 并将其与现有的信息状态相结合 , 以最终评估一个航班选项 , 而这两项操作都需要知识 。 对多个航班选项的成功评估构成了该规划的执行过程 , 直至做出最终的预订决定 。
这篇论文聚焦于执行环节 , 因为作者认为它是长程任务完成能力的关键组成部分 。 传统上 , 执行环节受到的关注少于推理、规划和世界知识等能力 , 而这些能力一直是 LLM 能力讨论的主要焦点 。 这种相对的忽视是很重要的 , 因为执行中的失败被错误地归因于推理或规划能力的局限 。 这种看法可能源于一种观点 , 即执行是一项简单或平凡的任务 。 毕竟 , 这是机器历来擅长的事情 。 人类一旦学会如何完成一项任务 , 在执行时也相当可靠 , 甚至会通过练习得到提高 。 然而 , 由于 LLM 并不具备正确性保证 , 作者假设 , 在长时程任务中 , 执行对 LLM 而言可能会出人意料地具有挑战性 。 他们推测:
即使推理、规划和世界知识都得到完善 , LLM 在长期执行过程中仍会出错 。
为了证明这一点 , 他们通过显式提供必要的知识和规划来隔离执行失败的情况 。 他们将前述航班选择智能体示例中提出的「先检索后组合」步骤串联起来 。 每个步骤都包括检索相关信息或规划中指定的工具 , 然后组合其输出以更新当前状态 。 规划负责决定检索什么以及如何组合 , 而执行则是实际执行这些操作 。 这符合一种自然的抽象 —— 键值(key-value)词典 。 键作为规划的一个步骤 , 指定要检索的知识或要调用的工具 , 而值则代表知识或工具的输出 , 随后需要将其与当前状态组合 。
在这项研究中 , 作者将规划作为每个查询中的键提供 , 从而消除了 LLM 对规划能力的需求 。 他们还在上下文中提供键值词典 , 消除了对模型参数知识的任何依赖 。 通过这种设计 , 作者直接控制两个重要的维度 , 它们相乘可得到任务长度(「先检索后组合」步骤的数量):轮次数量和轮次复杂度(K) 。 轮次复杂度可以通过改变每轮查询的键的数量来调整 。
实验结果
在实验部分 , 作者得出了以下几个核心结论:
长程任务执行具有挑战性 。 显著增大模型规模会大幅增加模型能够正确执行的轮次数量 。 模型会把自己上一步犯的错误当成新上下文继续学(self-conditioning) , 这导致每一步的准确率下降 。 增大模型规模并不足以缓解这一问题 。 思考模型能解决 self-conditioning 限制的问题 , 还能在单轮中执行明显更长的任务 。增加轮次的影响
作者首先验证了一个假设 —— 即使在不需要世界知识和规划的任务中 , 长时程任务执行也可能具有挑战性 。 然后 , 他们研究了增大模型规模对长时程任务执行的益处 。
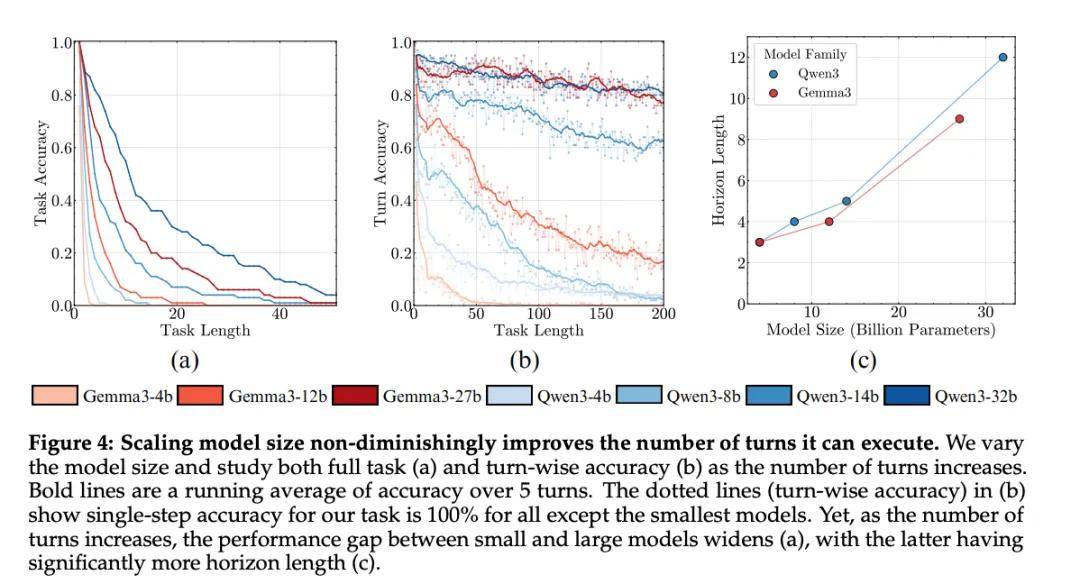
作者在图 4 中展示了结果 。 除了 Gemma3-4B 和 Qwen3-4B 之外 , 所有模型在第一步都达到了 100% 的准确率 , 这凸显出它们具备完美完成任务中单个步骤所需的知识和推理能力 。 然而 , 任务准确率在后续回合中迅速下降 。 即使是表现最佳的模型(Qwen3-32B) , 其准确率在 15 个轮次内也降至 50% 以下 。 这证实了作者的假设:即使去除了规划和知识方面的要求 , 长时程任务执行对 LLM 而言仍可能具有挑战性 。
如图 4(a)所示 , 更大的模型在更多轮次中保持更高的任务准确率 , 导致在任务长度上呈现明显的 scaling 趋势(图 4(c)) 。
为什么每轮准确率会下降?是 self-conditioning 在作怪
人们可能会认为模型的每轮表现会保持稳定 。 然而 , 图 4(b)显示 , 随着轮次数量的增加 , 各轮次的准确率在稳步下降 。 对此 , 作者研究了两个相互对立的假设:
模型的性能会仅仅因为上下文长度的增加而下降 , 与内容无关; 模型会以自身过去的错误为条件(self-conditioning) 。 在观察到自己在之前回合中的错误后 , 它犯错误的可能性会更大 。结果显示 , self-conditioning 会导致轮次准确率在长上下文之外进一步下降 。
图 5(a)中的结果表明 , 长上下文和 self-conditioning 都会导致准确率下降 。 当以无错误的历史为条件(诱导错误率 = 0.00)时 , 模型在第 100 轮的轮次准确率低于其初始值 , 这与之前关于长上下文退化的观察结果一致 。 更有趣的是 , 随着上下文中注入错误的比例的提高 , 第 100 轮的准确率持续下降 。 这证明了 self-conditioning 效应 —— 随着模型出错 , 它们更有可能犯更多错误 , 从而导致整个输出轨迹中的每轮准确率持续下降 , 如图 5(b)所示 。
此外 , 与长上下文不同 , 扩大模型规模并不能缓解 self-conditioning 效应 。 请注意 , 在诱导错误率为 0 的情况下 , 第 100 轮的准确率会随着模型规模的增大而持续提高 。
如图 5(c)所示 , 将模型扩展到前沿水平(2000 亿以上参数) , 如 Kimi-K2、DeepSeek-V3 和 Qwen3-235B Instruct-2507 , 在多达 100 轮的对话中基本解决了长上下文退化问题 , 在修复后的历史对话上实现了近乎完美的准确率 。
然而 , 即使是这些大型模型仍然容易受到 self-conditioning 作用的影响 , 因为随着其历史对话中诱导错误率的增加 , 它们的性能会持续下降 。 这可能与最近的研究结果类似 , 即大型模型在多轮对话中会出现性格转变 。 而在本文的案例中 , 这种转变是朝着容易出错的「性格」方向发展 。
在图 6 中 , 作者清晰地发现 Qwen3 thinking 模型不会进行 self-condition—— 无论其上下文中的错误率如何 , 模型在第 100 轮的准确率都保持稳定 。 这可能源于两个原因:
强化学习训练能够减少语言模型最可能的下一个 token 预测行为 , 使它们更倾向于任务成功而非延续上下文 。 移除先前轮次的思维轨迹可能会降低先前轮次对模型输出的影响 , 因为模型会独立思考新的轮次 。通过检查模型的思维轨迹 , 作者观察到它们在思维链中不会回溯到先前的轮次 。 此外 , 作者通过明确移除先前历史作为一种潜在的修正方法进行了上下文管理实验 , 发现这确实减轻了 self-conditioning 。
模型在单个轮次中能够完成的任务有多长?
模型能够处理的总任务长度是轮次数量和每轮需要执行的步骤数量共同作用的结果 。 作者也在实验中测量了后一个维度:模型每轮能够执行的最大步骤数量 。
实验结果显示 , 在没有思维链的情况下 , 不具备思考能力的模型难以在单轮中完成哪怕两个步骤的衔接 。
在图 12(左)中 , 作者首先发现 , 当被提示直接作答且不使用思维链时 , 更大规模的 Qwen3 32B、Gemma3 27B , 以及像 DeepSeek-V3(670B)和 Kimi K2(1026B)这样的前沿非思考型模型 , 连复杂度为 2 的单轮任务都无法完成 。 这与先前的研究结果一致 , 即对于 Transformer 模型执行序列任务而言 , 思考 token 是必不可少的 。
作者强调这一点是因为 , 许多智能体工作流为了在上下文窗口中容纳更多动作 , 会直接要求模型行动而不使用思维链 。 作者发现 , 借助思维链 , 模型在单轮中能够执行的步骤数量显著增加 。 这表明 , 对于智能体而言 , 行动前先进行推理至关重要 。 在附录 B 中 , 作者还展示了诸如多数投票之类的并行测试时计算 , 仅能在单轮执行长度和轮次数量上带来微小提升 。 这为以下观点提供了初步证据:对于长时程执行任务 , 顺序性的测试时计算更为有效 。
在图 12(右侧)中 , 作者就前沿模型在单轮对话中能够执行的任务长度进行了基准测试 。 他们发现 GPT-5(代号 Horizon)与其他模型(如 Gemini 2.5 Pro、Grok 4 和 DeepSeek R1)之间存在惊人的巨大差距 。 他们还发现 , 经过强化学习训练的思维模型 DeepSeek R1 的性能显著优于其经指令微调的对应模型 DeepSeek-V3 。
总体而言 , 长时程执行是一项挑战 , 开源权重模型在这方面仍在追赶那些仅通过 API 提供的模型 , 这凸显了未来研究的机遇 。
作者的实验部分写得非常翔实 , 不过有人质疑这些实验是否符合长时程任务的标准 。 感兴趣的读者可以去仔细看一下 。
更多细节请参见原论文 。
推荐阅读














- 百度CTO王海峰:AGI曙光已现Scaling Law仍有效|新智元十周年峰会
- MOVA携高端品牌NexLawn亮相IFA,创新力全面爆发
- 谁说性能手机拍照就很差?iQOO Z10 Turbo+影像体验分享
- 开启RL Scaling新纪元,siiRL开源:完全分布式强化学习框架
- 谁说华为没有性价比?麒麟芯+256GB+卫星图片消息,低至1509元起
- 终于开窍了?微星正式上架AMD版CLAW 8掌机
- 3K价位段国产平板横评 谁说Mac只能配iPad?
- 瞬间解压!好玩的随身小音箱,Allawy Magic10解压蓝牙音箱评测
- 新U遇冷老U产能告急!Intel两代CPU冰火两重天:谁说要买新不买旧
- 谁说高性能必须高能耗?揭秘企业级SSD功耗管理“黑科技”