
文章图片
文章图片

文章图片
文章图片
文章图片
本工作核心作者为汤子瑞(上海交通大学)、牛博宇(上海交通大学) 。 合作者为李帛修、周炜、王健楠、李国良、张心怡、吴帆 。 通讯作者为上海交通大学计算机学院博士生导师周煊赫 。 团队长期从事人工智能与数据交叉研究 。
半结构化表格是我们日常工作中常见的 “拦路虎”—— 布局五花八门、结构复杂多变 , 让自动化数据处理变得异常困难 。
面对这样的挑战 , 传统的表格处理工具往往力不从心 。 研究发现 , 现有的大模型以及表格理解领域模型在 NL2SQL / 结构化表格已经有了较好的效果(准确率超 80%) , 但是在那些诸如金融报表、库存表、企业管理表等具有合并单元格、嵌套表格、层次结构等特征的复杂半结构化表格上表现明显退化 。
为了解决这一痛点 , 来自上海交通大学计算机学院、西蒙菲莎大学、清华大学、中国人民大学的合作团队 , 带来基于树形框架的智能表格问答系统(ST-Raptor) , 其不仅能精准捕捉表格中的复杂布局 , 还能自动生成表格操作指令 , 并一步步执行这些操作流程 , 最终准确回答用户提出的问题 —— 就像给 Excel 装上了一个会思考的 “AI 大脑” 。
【ST-Raptor框架发布,实现复杂半结构化表格的精准理解与信息抽取】目前 , 该论文已被数据库领域国际顶尖学术会议 ACM SIGMOD 2026 接收 。
论文标题:ST-Raptor: LLM-Powered Semi-Structured Table Question Answering 论文链接:https://arxiv.org/abs/2508.18190 项目仓库:https://github.com/weAIDB/ST-Raptor
该项目发布后得到广泛关注与转发:
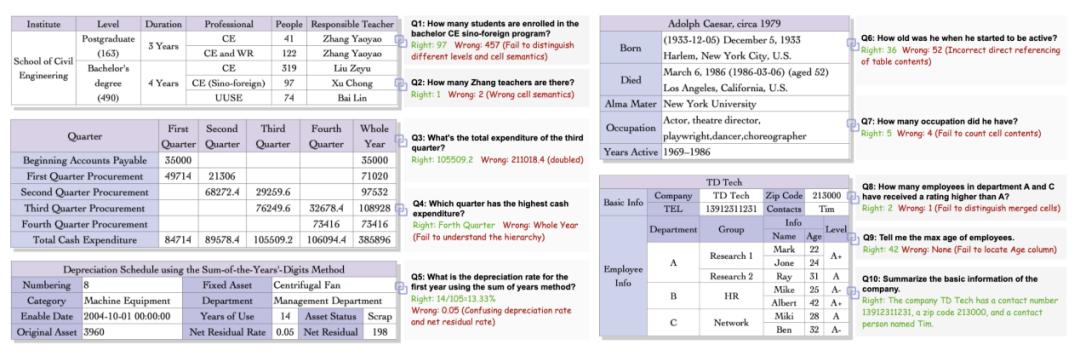
现有的 NL2SQL 方法需要将半结构化表格转换为结构化表格处理 , 这通常会导致大量的信息丢失 。 此外 , 现有的 NL2Code 和多模态 LLM 问答都无法准确捕捉半结构化表格独特的信息组织方法 , 因此无法准确回答相应的问题 。 下图展示了一些基线方法在半结构化表格问答上的表现 。 在总共 100 个问题的回答中 , 大模型的错误率均较高 , 且其在涉及到表格结构理解 , 数据获取 , 问题推理三方面表现均不佳 。
准确率低的原因主要由于以下几点:(1)半结构化表格结构个性化程度高 , 结构复杂多样且隐含了部分语义信息 , 大模型难以捕捉到布局的微妙之处 。 (2)在进行表格数据检索时 , 模型容易产生幻觉 , 造成失真 。 (3)模型对问题的理解能力不足 , 不能从表格里获取解决问题需要的信息 。
HO-Tree
创新性的半结构化表格表示方案
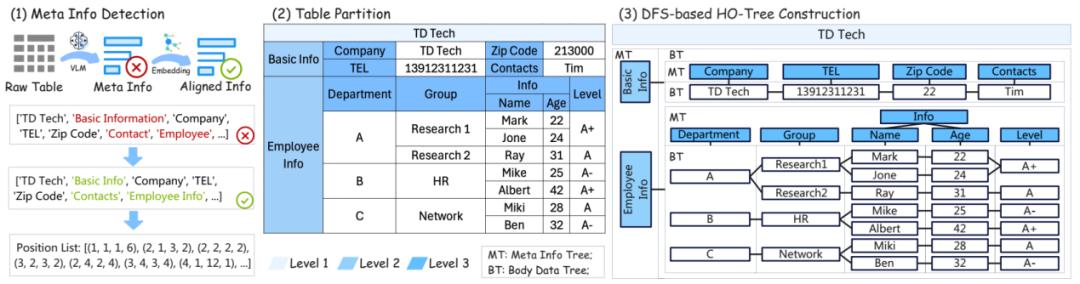
为了定制解决半结构化表格信息的复杂分布问题 , 本文提出了层次正交树(HO-Tree)这一数据结构 。 HO-Tree 由 Meta Tree(MTree)和 Body Tree(BTree)嵌套组合形成 , 其中 MTree 代表了表头中的元数据 , BTree 代表了表内容中的信息数据 。
上图展示了构建 HO-Tree 的基本步骤 。 对于一个 excel 表格 , 首先将表内容转化为 HTML 格式并渲染 , 接着用 VLM 提取图片中的表头信息 , 在对齐后得到元信息组 。 接着 , 根据得到的元信息将表格进行分层级的区域划分 , 最后根据这一层级得到 HO-Tree 。 通过这一步骤 , 半结构化表格被转化为了计算机易于操作的数据形式 , 为后续处理提供了便利 。
树上操作与流程设计
精准回答问题的 “手术刀”
在建构好 HO-Tree 之后 , 本文继续设计了一套在树上进行检索的操作 , 通过迭代地使用这些操作 , LLM 可以按步骤分析表格 , 最终获取信息回答问题 。 这些操作可以分为以下四类:
数据获取操作:可以获取树上子节点 , 父节点等信息 , 递归地进行数据获取操作可以有效去除冗余信息 , 得到回答问题所必要的信息 。数据处理操作:根据问题需要的形式 , 将得到的数据进行处理(如求和 , 计数 , 按条件筛选等) 。对齐操作:将过程中的信息和表格内容进行对齐 , 增强检索时的健壮性 。推理操作:将获取的最终答案和问题进行对齐 , 得到满足格式要求的最终答案输出 。
这些操作可以帮助 LLM 以直观的方法获取数据 , 分析表格 , 并且以可信的方式得到最终答案 。 结合这些操作 , 可以搭建一套流水线回答问题 。 如下图例子所示 , 在得到问题后 , ST-Raptor 将其拆解为三个子问题 , 通过预定义的树上操作进行搜索 , 处理 , 最后经过推理得到答案 。
实验结论
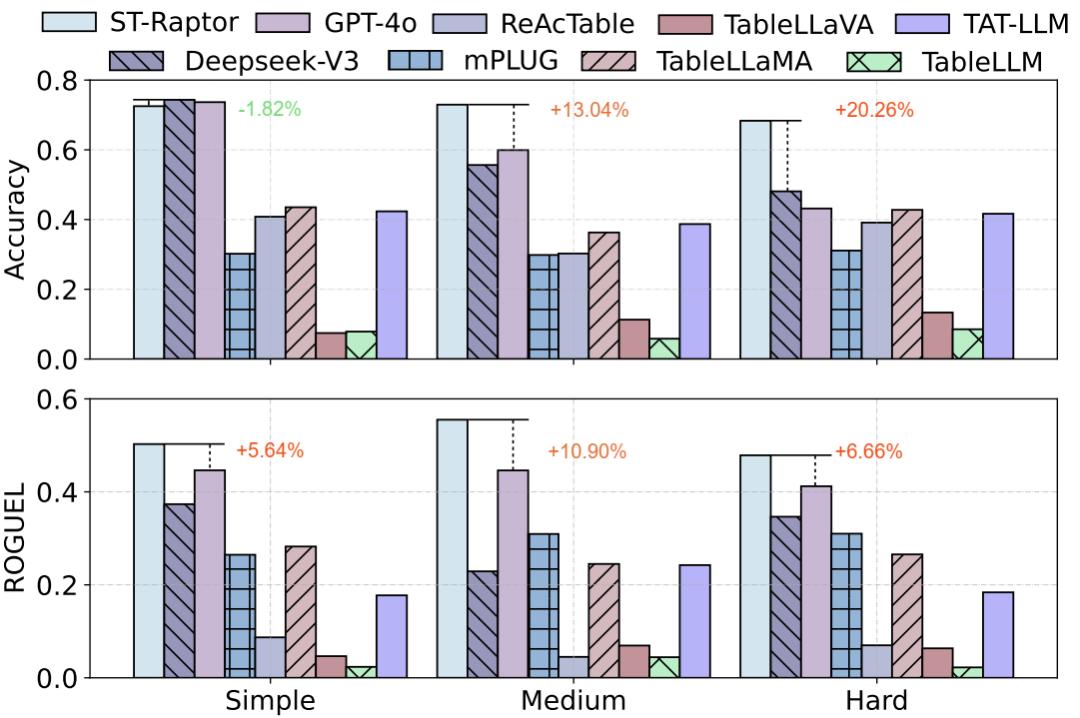
现有的表格数据集大多以结构化为主 , 一些半结构化的数据集也都并不涉及复杂嵌套关系 , 和真实情境不符 。 因此 , 本文构建了一个半结构化表格数据集 SSTQA , 共有 102 张复杂的真实情境表格和 764 个针对这些表格的问题 , 总共包含了 19 个代表性的真实场景 。 如下图所示 , 在 SSTQA 上 , ST-Raptor 相较其余方法而言 , 取得了很高的准确率提升 , 尤其是在结构复杂困难的表格上远超其余方法 。
在其余两个半结构化表格问题数据集 WikiTQ 和 TempTabQA 上的测试结果如下表所示 , ST-Raptor 准确率位于榜首 , 展现出了优秀的泛化能力 。
综上所述 , ST-Raptor 提供了一套行之有效的半结构化表格问答解决方案 , 为现实生活中的半结构化表格自动化处理提供了新思路 。 通过挂载 ST-Raptor , LLM 可以增加对半结构化表格的理解能力和分析能力 , 提升表格问答的准确性 。 在未来 , 可以优化 HO-Tree 的表示和创建 , 使其囊括更多复杂表格;同时可以定制更多树上操作 , 使问题回答更流畅便捷 。
ST-Raptor 立足于表格结构解析这一核心挑战 , 有效弥补了大语言模型在处理二维表格结构时的能力短板 , 能够直接支持包括 Excel 在内的多种复杂半结构化表格输入 。 尽管如此 , 现实场景中的半结构化表格仍普遍存在格式不规范、布局多样、语义歧义以及跨表关联等复杂问题 , 值得在模型架构、语义理解与泛化能力等方面展开长期而深入的探索 。
推荐阅读












- 创智复旦字节发布AgentGym-RL,昇腾加持,开创智能体训练新范式
- 佳能发布数字电影摄影机EOS C50 搭载7K全画幅CMOS
- 20 英寸?苹果新品来了,发布时间曝光
- 苹果发布会总结:iPhone 17加量不加价,更强的Pro、超薄Air登场
- 永不商业化!阿里神秘项目揭晓:高德发布“高德扫街榜”
- 苹果史上“最具野心的一代”?一文看全iPhone 17发布会
- 苹果新品发布!郑州富士康iPhone17港区产线已接近满产,返费价格突破9000元,近20万人两班倒赶工
- 苹果史上最贵iPhone发布 多家机构看好果链龙头公司
- 快手AI超级员工上线!一句话剪出完整短视频,从文案到发布一条龙
- 苹果iPhone17发布,标准版120HZ高刷,安卓厂商好日子到头了?